1. 개요
주제 : 이변량분석(숫자vs숫자)
목표 : 이변량 분석의 4가지 방법(숫자vs숫자, 범주vs숫자, 숫자vs범주, 범주vs범주를 완벽하게 구분하고 구현할 수 있다.)
2. 시각화 : 산점도
- 상관 분석에 대해서 이야기 해봅시다.
- 상관 분석은 연속형 변수 X에 대한 연속형 변수 Y의 관계를 분석할 때 사용됩니다.
- Scatter를 통해 시각화 합니다.
(1) 산점도
- 문법
- plt.scatter( x축 값, y축 값 )
- plt.scatter( ‘x변수’, ‘y변수’, data = dataframe이름)
✍ 입력
plt.scatter('Temp', 'Ozone', data = air)
plt.show()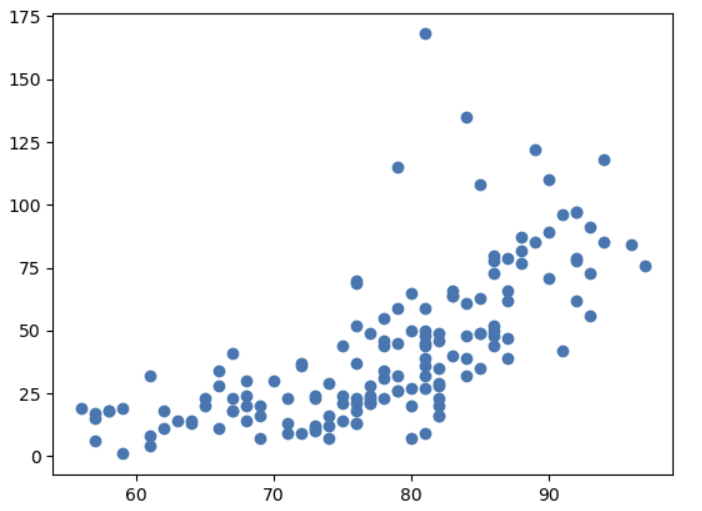
3. 수치화 : 상관분석
(1) 상관계수, p-value
- 상관계수 𝑟
- 공분산을 표준화 한 값
- 1 ~ 1 사이의 값
- 1, 1에 가까울 수록 강한 상관관계를 나타냄. - 경험에 의한 대략의 기준(절대적인 기준이 절대 아닙니다.)
- 강한 : 0.5 < |𝑟| ≤ 1
- 중간 : 0.2 < |𝑟| ≤ 0.5
- 약한 : 0.1 < |𝑟| ≤ 0.2
- (거의)없음 : |𝑟| ≤ 0.1
✍ 입력
import scipy.stats as spst
# 상관계수와 p-value
spst.pearsonr(air['Temp'], air['Ozone'])✍ 출력
# 첫 번째 값은 상관계수, 두 번째 값은 p-value
(0.6833717861490115, 2.197769800200214e-22)(2) 데이터프레임 한꺼번에 상관계수 구하기
✍ 입력
air.corr()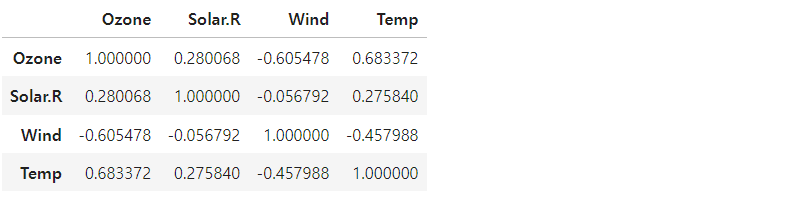
(3) 상관계수를 heatmap으로 시각화
✍ 입력
plt.figure(figsize = (8, 8))
sns.heatmap(air.corr(),
annot = True, # 숫자(상관계수) 표기 여부
fmt = '.3f', # 숫자 포멧 : 소수점 3자리까지 표기
cmap = 'RdYlBu_r', # 칼라맵
vmin = -1, vmax = 1) # 값의 최소, 최대값
plt.show()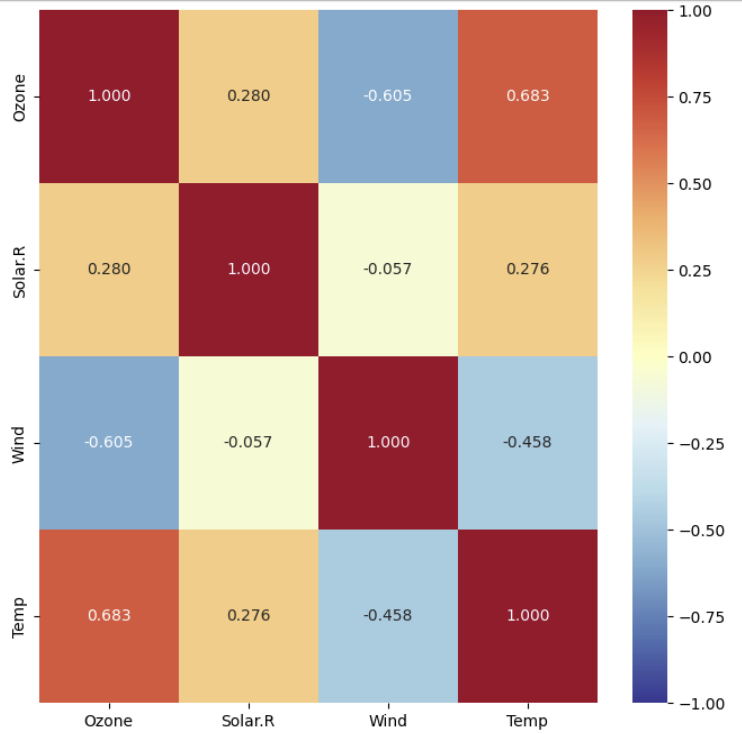
1. 개요
주제 : 이변량분석(범주 vs 숫자)
목표 : 이변량 분석의 4가지 방법을 구현할 수 있다!
2. 시각화
- titanic data에서 Age를 Y로 두고 비교해 봅시다.
(1) 평균 비교 : barplot
countplot(단변량) 과 barplot(이변량)
sns.barplot: 주어진 x와 y 값에 대해 막대 그래프를 생성합니다. y 값은 연속형 데이터일 수 있습니다.
sns.countplot: 주어진 카테고리 변수의 각 카테고리에 대한 빈도를 보여주는 막대 그래프를 생성합니다. 따라서 주로 명목 또는 이산형 변수에 사용됩니다.
✍ 입력
sns.barplot(x = "Survived", y= "Age", data = titanic)
plt.grid()
plt.show()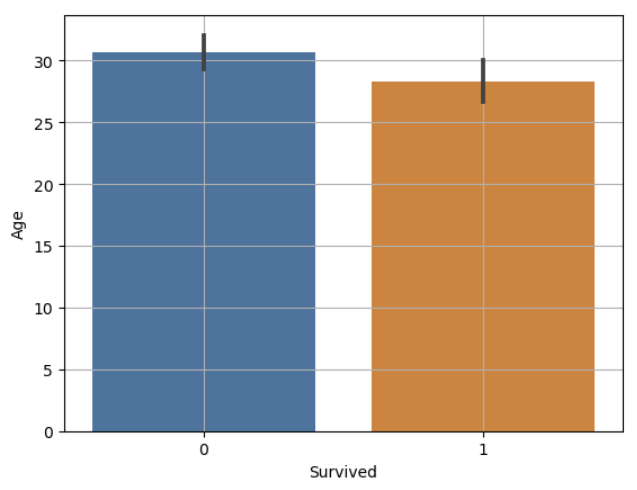
✍ 입력
titanic.loc[:10, ['Survived','Age']]
(2) boxplot
✍ 입력
sns.boxplot(x='Survived', y = 'Age', data = titanic)
plt.grid()
plt.show()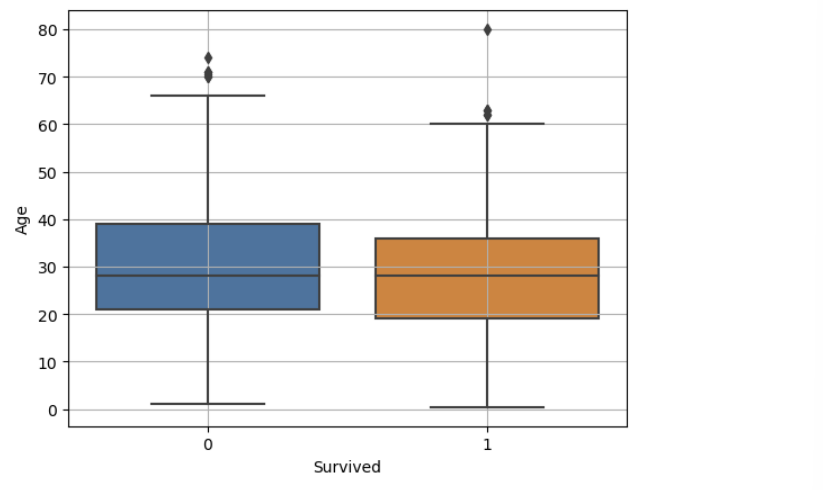
3. 수치화
(1) t-test
1) 데이터 준비
✍ 입력
# 먼저 NaN이 있는지 확인해 봅시다.
titanic.isna().sum()
# NaN 행 제외
temp = titanic.loc[titanic['Age'].notnull()]
# 두 그룹으로 데이터 저장
died = temp.loc[temp['Survived']==0, 'Age']
survived = temp.loc[temp['Survived']==1, 'Age']2) t-test
✍ 입력
spst.ttest_ind(died, survived)✍ 출력
TtestResult(statistic=2.06668694625381, pvalue=0.03912465401348249, df=712.0)[문1] 성별에 따라 운임에 차이가 있을 것이다.
✍ 입력
sns.barplot(x='Sex', y='Fare', data = titanic)
plt.grid()
plt.show()(2) anova
- 분산 분석 ANalysis Of VAriance
- 여러 집단 간에 차이
- 𝐹 통계량 = 값이 대략 2~3 이상이면 차이가 있다고 판단합니다.
# Pclass(3 범주) --> Age
sns.barplot(x="Pclass", y="Age", data=titanic)
plt.grid()
plt.show()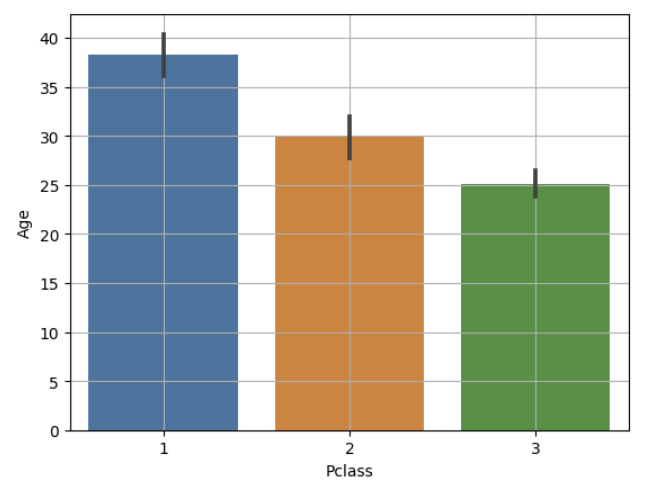
✍ 입력
# 1) 분산 분석을 위한 데이터 만들기
# NaN 행 제외
temp = titanic.loc[titanic['Age'].notnull()]
# 그룹별 저장
P_1 = temp.loc[temp.Pclass == 1, 'Age']
P_2 = temp.loc[temp.Pclass == 2, 'Age']
P_3 = temp.loc[temp.Pclass == 3, 'Age']
# 2) anova
spst.f_oneway(P_1, P_2, P_3)✍ 출력
F_onewayResult(statistic=57.443484340676214, pvalue=7.487984171959904e-24)
안녕하세요. 꾸준히 기록하는 hyowon입니다.