0. 개요
주제 : 서울시 생활정보 기반 대중교통 수요 분석
목표 : 대중교통 수요 분석을 통해 어떤 구에 버스 정류장을 설치해야 할지 생각해보자
1. 데이터 불러오기
2. 기본 정보 확인 및 클렌징
[실습] 위 데이터에서 버스정류장 위치를 '구' 별로 구분해보기
✍ 입력
bus_station['버스정류장ARS번호']
✍ 입력
# 버스정류장 ARS번호에서 시작하는 앞자리 2개로 '자치구'라는 새로운 컬럼 생성
# str() : 정수나 실수를 문자열 형태로 바꿔주는 함수, slice()
bus_station['자치구'] = bus_station['버스정류장ARS번호'].str.slice(start=0, stop = -3)
bus_station['자치구']
✍ 입력
# 구 코드를 구 이름으로 변환하기
# map() : 리스트, 튜플 등 반복 가능한 데이터 집합을 입력으로 받아 변환하는 함수
bus_station['자치구'] = bus_station['자치구'].map({
'1': '종로구',
'2': '중구',
'3': '용산구',
'4': '성동구',
'5': '광진구',
'6': '동대문구',
'7': '중랑구',
'8': '성북구',
'9': '강북구',
'10': '도봉구',
'11': '노원구',
'12': '은평구',
'13': '서대문구',
'14': '마포구',
'15': '양천구',
'16': '강서구',
'17': '구로구',
'18': '금천구',
'19': '영등포구',
'20': '동작구',
'21': '관악구',
'22': '서초구',
'23': '강남구',
'24': '송파구',
'25': '강동구'})[실습1] 결측치 처리하기
✍ 입력
bus_station.loc[bus_station['버스정류장ARS번호'] == '~']
bus_station = bus_station.dropna()
# "버스정류장ARS번호" dtype을 정수형(int)으로 변경
bus_station = bus_station.astype({'버스정류장ARS번호':'int64'})[실습2] 구별로 버스정류장의 개수 확인하기 (서울시)
groupby 잘 사용하자!!
✍ 입력
# 자치구별 버스정류장 고유값들의 갯수를 출력하여 'bus_station_count' 변수로 저장
# nunique(), groupby()
bus_station_count = bus_station.groupby("자치구")["버스정류장ARS번호"].nunique()
bus_station_count
✍ 입력
# 중랑구에 428개의 버스정류장이 있다는데, 실제 ARS번호를 확인해봅시다.
# 자치구별 버스정류장 고유값들을 출력하여 'bus_staiton_unique' 변수로 저장
bus_station_unique = bus_station.groupby("자치구")["버스정류장ARS번호"].unique()[실습3] 서울의 버스 정류장 데이터만 포함하고 있는 excel 파일 열기 ('1.1 bus_station_202401.xlsx')
✍ 입력
# 서울의 버스 정류장 데이터만 포함하고 있는 excel 파일 열기 ('1.1 bus_station_202401.xlsx')
# https://data.seoul.go.kr/dataList/OA-15067/S/1/datasetView.do (출처:서울열린데이터광장)
# 'only_seoul' 변수로 저장
only_seoul = pd.read_excel('1.1 bus_station_202401.xlsx')[실습4] # 'only_seoul'과 'bus_station' 데이터 병합
✍ 입력
# 'ARS-ID'열 이름을 '버스정류장ARS번호'로 바꾸기
only_seoul.rename(columns={'ARS_ID':'버스정류장ARS번호'}, inplace=True)
# 'only_seoul'과 'bus_station' 데이터 병합
df = pd.merge(only_seoul, bus_station, how='inner', on = '버스정류장ARS번호')[실습5] 구 별로 버스 정류장의 개수 확인하기, 'seoul_bus_station_ARS' 변수로 저장
✍ 입력
# 구 별로 버스 정류장의 개수 확인하기, 'seoul_bus_station_ARS' 변수로 저장
seoul_bus_station_ARS = df.groupby(by=["자치구"], as_index=False)["버스정류장ARS번호"].nunique()
seoul_bus_station_ARS
[실습6] 구 별로 버스 노선의 개수 확인하기
✍ 입력
seoul_bus_station_line = df.groupby(by=['자치구'],as_index=False)["노선번호"].nununique()
seoul_bus_station_line
[실습7] 각 구별로 승차 총 승객수, 하차 총 승객수 구하기
✍ 입력
seoul_bus_station_sum = df.groupby(by = ["자치구"] , as_index=False)[["승차총승객수","하차총승객수"]].sum()
seoul_bus_station_sum
[실습8] 각 구별 승차 평균 승객수, 하차 평균 승객수 구하기
✍ 입력
seoul_bus_station_mean = df.groupby(by = ["자치구"],as_index = False)[["승차총승객수", "하차총승객수"]].mean()
seoul_bus_station_mean[실습9] 각 구별 승차 평균 승객수, 하차 평균 승객수 구하기
-> 여러 개의 파일 합치는 것 연습!!
✍ 입력
# 네 개 파일을 합쳐주세요.
# seoul_bus_station_ARS
# seoul_bus_station_line
# seoul_bus_station_sum
# seoul_bus_station_mean
# concat도 여러 데이터프레임을 합칠 수 있습니다. 그러나 여러 데이터프레임을
# 하나의 데이터프레임으로 합치는 것은 'pd.concat()을 사용하여 수행 가능합니다.'
# 하지만, 여러 데이터프레임을 공통된 열을 기준으로 병합하려면 pd.merge가 더 적합함
a = pd.merge(seoul_bus_station_ARS, seoul_bus_station_line, how = 'inner', on = '자치구' )
b = pd.merge(a, seoul_bus_station_sum, how = 'inner', on = '자치구')
seoul_bus_station = pd.merge(b, seoul_bus_station_mean, how = 'inner', on = '자치구')
# '버스정류장ARS번호' -> '정류장수', '노선번호' -> '노선수'로 열이름 변경
seoul_bus_station.rename(columns= {'버스정류장ARS번호':'정류장수', '노선번호':'노선수'}, inplace=True)[실습10] 데이터 분포 알아보기
✍ 입력
# 자치구별 정류장 수를 볼 수 있는 그래프를 출력해주세요.
plt.figure(figsize=(20,4))
plt.plot('자치구', '정류장수', data = seoul_bus_station)
plt.xlabel('자치구')
plt.ylabel('정류장 수')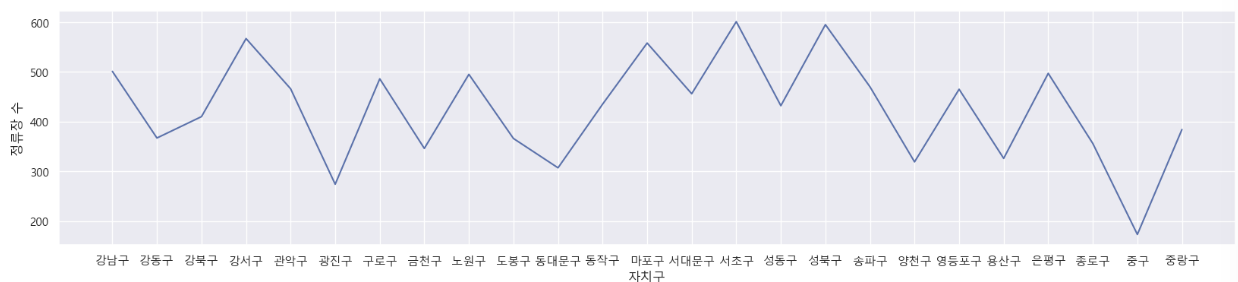

안녕하세요. wony입니다.