1. 개요
주제 : 이변량분석
목표 : 이변량 분석의 4가지 방법(숫자vs숫자, 범주vs숫자, 숫자vs범주, 범주vs범주를 완벽하게 구분하고 구현할 수 있다.)
2. 시각화 - 범주 vs 범주
(1) 교차표(pd.crosstab)
범주 vs 범주를 비교하고 분석하기 위해서는 먼저 교차표를 만들어야 합니다.
- pd.crosstab(행, 열, normalize = )
✍ 입력
# 두 범주별 빈도수를 교차표로 만들어 봅시다.
pd.crosstab(titanic['Survived'], titanic['Sex'], normalize = 'columns')
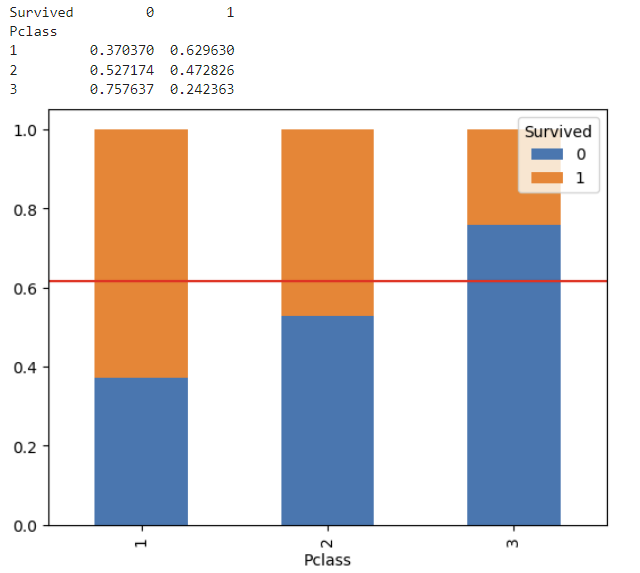
(2) 시각화
- mosaic
- 100% Stacked Bar
- 먼저 crosstab으로 집계 : pd.crosstab(feature, target, normalize = 'index')
- .plot.bar(stacked = true)
- 전체 평균선 : plt.axhline()
(3) 카이제곱 검정
✍ 입력
# 1) 먼저 교차표 집계
table = pd.crosstab(titanic['Survived'], titanic['Pclass'])
print(table)
print('-' * 50)
# 2) 카이제곱검정
spst.chi2_contingency(table)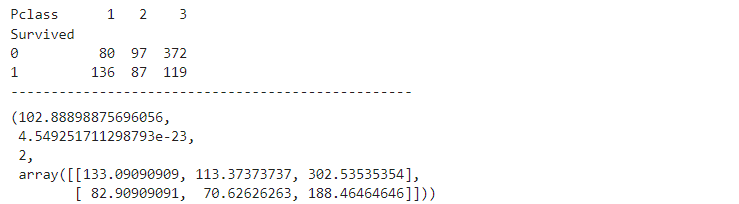
2. 시각화 - 숫자 vs 범주
(1) 시각화
kdeplot을 그려봅시다.
두가지 방법이 있습니다.
① kdeplot( , hue = 'Survived')
생존여부의 비율이 유지된 채로 그려짐
두 그래프의 아래 면적의 합이 1
② kdeplot( , hue = 'Survived', common_norm = False)
생존여부 각각 아래 면적의 합이 1인 그래프
②-① kdeplot( , hue = 'Survived', multiple = 'fill')
나이에 따라 생존여부 비율을 비교해볼 수 있음. (양의 비교가 아닌 비율!)
sns.kdeplot(x='Age', data = titanic, hue ='Survived')
plt.show()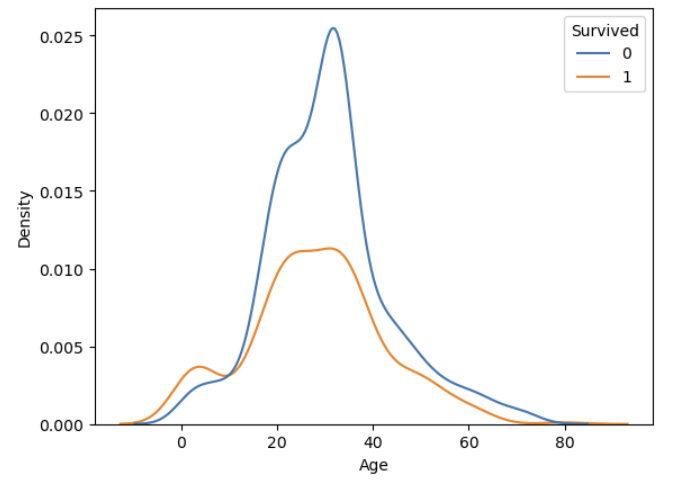
sns.kdeplot(x='Age', data=titanic, hue='Survived', common_norm = False)
plt.show()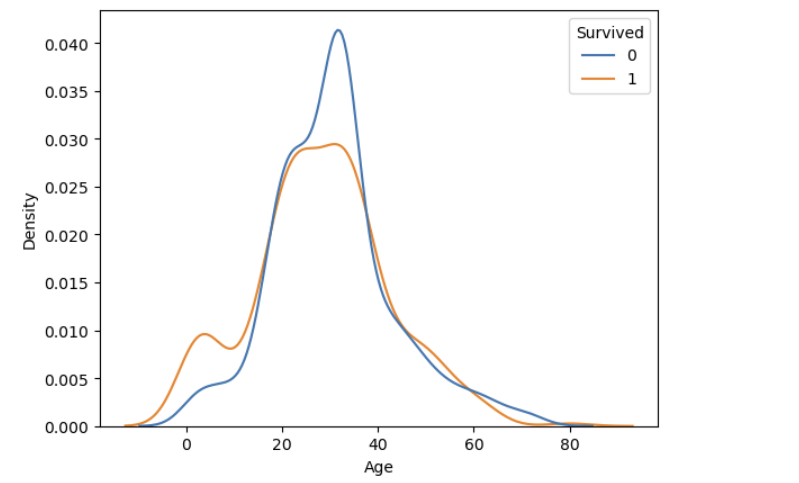

안녕하세요. 꾸준히 기록하는 hyowon입니다.