0. 개요
주제 : K-Fold Cross Validation
내용 : 앞서 공부 했던 선형회귀, KNN (회귀 모델) 과 결정 트리, 로지스틱 회귀(분류 모델)에서 더 나아가 정교한 평가 절차를 진행하는 K-Fold Cross Validation에 대해 학습
1. K-Fold Cross Validation
1) x, y 분리
# Target 확인
target = 'Outcome'
# 데이터 분리
x = data.drop(target, axis=1)
y = data.loc[:, target]2) 학습용, 평가용 데이터 분리
# 라이브러리 불러오기
from sklearn.model_selection import train_test_split
# 학습용, 평가용 데이터 7:3으로 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)3) 정규화
KNN 알고리즘을 사용하기 위해 정규화를 진행합니다.
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train_s = scaler.transform(x_train)
x_test_s = scaler.transform(x_test)1-1. K-Fold Cross Validation 성능 예측
- K분할 교차 검증 방법으로 모델 성능을 예측합니다.
- cross_val_score(model, x_train, y_train, cv=n) 형태로 사용합니다.
- cv 옵션에 k값(분할 개수, 기본값=5)을 지정합니다.
- cross_val_score 함수는 넘파이 배열 형태의 값을 반환합니다.
- cross_val_score 함수 반환 값의 평균을 해당 모델의 예측 성능으로 볼 수 있습니다.
1) Decision Tree
# 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 선언하기
model = DecisionTreeClassifier(max_depth=5, random_state=1)
# 검증하기
cv_score = cross_val_score(model, x_train, y_train, cv=10, scoring='accuracy')
# 확인
print(cv_score)
print('평균:', cv_score.mean())
print('표준편차:', cv_score.std())
# 기록
result = {}
result['Decision Tree'] = cv_score.mean()2) KNN
# 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
# 선언하기
model = KNeighborsClassifier()
# 검증하기
cv_score = cross_val_score(model, x_train_s, y_train, cv=10, scoring='accuracy')
# 확인
print(cv_score)
print('평균:', cv_score.mean())
print('표준편차:', cv_score.std())
# 기록
result['KNN'] = cv_score.mean()3) Logistic Regression
# 불러오기
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# 선언하기
model = LogisticRegression()
# 검증하기
cv_score = cross_val_score(model, x_train, y_train, cv=10, scoring='accuracy')
# 확인
print(cv_score)
print('평균:', cv_score.mean())
print('표준편차:', cv_score.std())
# 기록
result['Logistic Regression'] = cv_score.mean()1-2. 성능 비교
# 성능 비교
plt.figure(figsize=(5, 5))
plt.barh(y=list(result), width=result.values())
plt.xlabel('Score')
plt.ylabel('Model')
plt.show()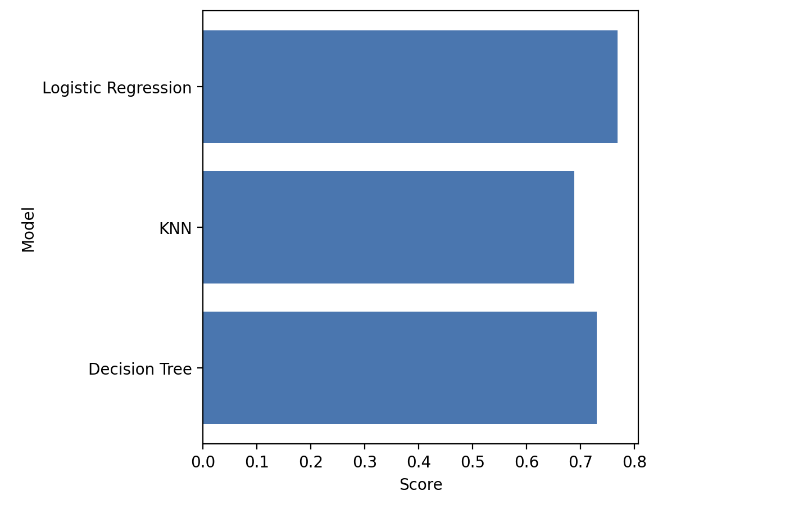

안녕하세요. wony입니다.