0. 개요 및 데이터 준비와 성능 예측
주제 : 머신러닝. 머신러닝의 전체 과정의 코드 실습
내용 : 이를 통해, 하이퍼파라미터 튜닝을 완벽하게 구현해 낼 수 있다.
- 데이터 준비
# target 확인
target = 'medv'
# 데이터 분리
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 모듈 불러오기
from sklearn.model_selection import train_test_split
# 데이터 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)- 성능 예측(k-Fold)
# 불러오기
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score, RandomizedSearchCV
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model_dt = DecisionTreeRegressor(random_state=1)
# 성능예측
cv_score = cross_val_score(model_dt, x_train, y_train, cv=5)
# 결과확인
print(cv_score)
print('평균:', cv_score.mean())
1. Random Search
1) 모델 튜닝
- 성능을 확인할 파라미터를 딕셔너리 형태로 선언합니다.
- 기존 모델을 기본으로 RandomizedSearchCV 알고리즘을 사용하는 모델을 선언합니다.
- 다음 정보를 최종 모델에 파라미터로 전달합니다.
- 기본 모델 이름
- 파라미터 변수
- cv: K-Fold 분할 개수(기본값=5)
- n_iter: 시도 횟수(기본값=10)
- scoring: 평가 방법
# 파라미터 선언
# max_depth: 1~50
param = {'max_depth': range(1, 51)}
# Random Search 선언
# cv=5
# n_iter=20
# scoring='r2'
model = RandomizedSearchCV(model_dt, # 기본 모델 이름
param, # 앞에서 선언한 튜닝용 파라미터 변수
cv=5, # k-Fold Cross Validation (default=5)
n_iter=20, # Random하게 시도할 횟수 (default=10)
scoring='r2') # 평가 방법
# 학습하기
model.fit(x_train, y_train)
2) 결과 확인
- model.cvresults 속성에 성능 테스트와 관련된 많은 정보가 포함되어 있습니다.
- 이 중 중요한 정보를만 추출해서 확인합니다.
- 다음 3가지는 꼭 기억해야 합니다.
- model.cvresults['mean_test_score']: 테스트로 얻은 성능
- model.bestparams: 최적의 파라미터
- model.bestscore: 최고의 성능
# 중요 정보 확인
print('=' * 80)
print(model.cv_results_['mean_test_score'])
print('-' * 80)
print('최적파라미터:', model.best_params_)
print('-' * 80)
print('최고성능:', model.best_score_)
print('=' * 80)3) 변수 중요도
- model.bestestimator 모델의 변수 중요도를 확인합니다.
# 변수 중요도
plt.figure(figsize=(5, 5))
plt.barh(y=list(x), width=model.best_estimator_.feature_importances_)
plt.show()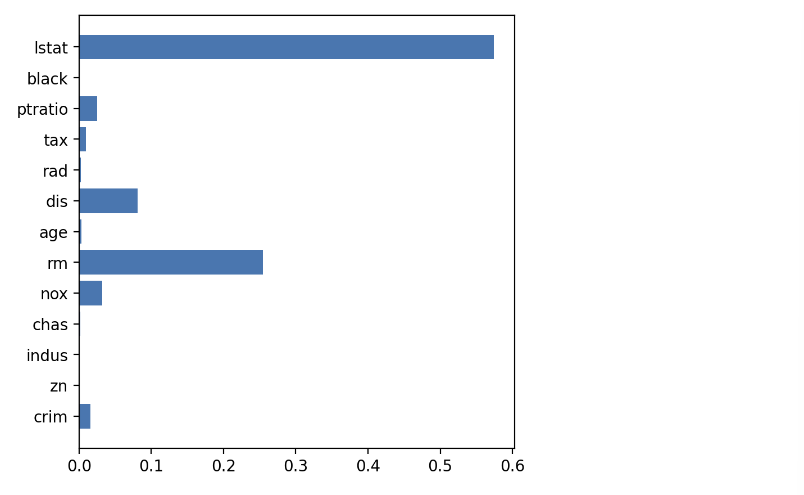
4) 성능 평가
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print('MAE:', mean_absolute_error(y_test, y_pred))
print('R2-Score:', r2_score(y_test, y_pred))2. Grid Search
1) 모델 튜닝
- 성능을 확인할 파라미터를 딕셔너리 형태로 선언합니다.
- 기존 모델을 기본으로 GridSearchCV 알고리즘을 사용하는 모델을 선언합니다.
- 다음 정보를 최종 모델에 파라미터로 전달합니다.
- 기본 모델 이름
- 파라미터 변수
- cv: K-Fold 분할 개수(기본값=5)
- n_iter: 시도 횟수(기본값=10)
- scoring: 평가 방법
# 파라미터 선언
# max_depth: 1~50
param = {'max_depth': range(1, 51)}
# 선언하기
model_dt = DecisionTreeRegressor(random_state=2022)
# Grid Search 선언
# cv=5
# scoring='r2'
model = GridSearchCV(model_dt, # 기본 모델 이름
param, # 앞에서 선언한 튜닝용 파라미터 변수
cv=5, # k-Fold Cross Validation (default=5)
scoring='r2') # 평가 방법2) 결과 확인
# 중요 정보 확인
print('=' * 80)
print(model.cv_results_['mean_test_score'])
print('-' * 80)
print('최적파라미터:', model.best_params_)
print('-' * 80)
print('최고성능:', model.best_score_)
print('=' * 80)3) 변수 중요도
- model.bestestimator 모델의 변수 중요도를 확인합니다.
# 변수 중요도
plt.figure(figsize=(5, 5))
plt.barh(y=list(x), width=model.best_estimator_.feature_importances_)
plt.show()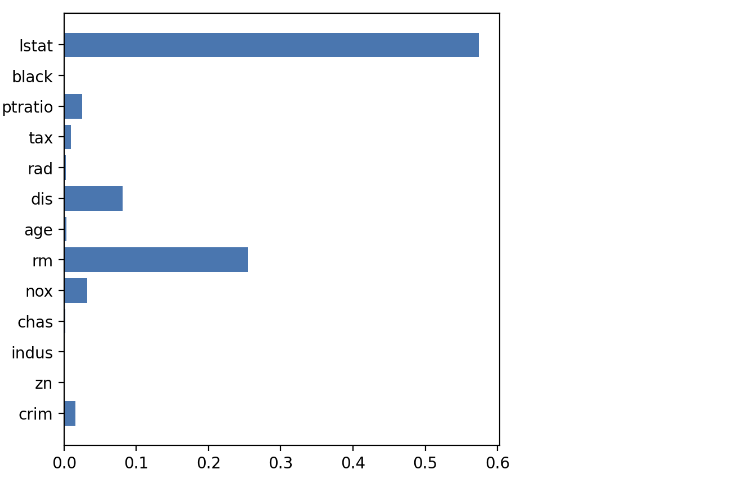
4) 성능 평가
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print('MAE:', mean_absolute_error(y_test, y_pred))
print('R2-Score:', r2_score(y_test, y_pred))
안녕하세요. 꾸준히 기록하는 hyowon입니다.