0. 개요 및 데이터 준비와 성능 예측
주제 : 딥러닝 전체 과정의 코드 실습
내용 : 이를 통해, 딥러닝 회귀, 분류를 완벽하게 구현해 낼 수 있다.
- 데이터 준비
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/advertising.csv'
adv = pd.read_csv(path)
adv.head()
target = 'Sales'
x = adv.drop(target, axis=1)
y = adv.loc[:, target]
# 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 20)
# 선형회귀 모델링
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train, y_train)
pred = model.predict(x_val)
print(f'RMSE : {mean_squared_error(y_val, pred, squared=False)}')
print(f'MAE : {mean_absolute_error(y_val, pred)}')
print(f'MAPE : {mean_absolute_percentage_error(y_val, pred)}')1. 딥러닝 모델링
1) 전처리 : Scaling
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)2) 필요 함수 불러오기
from keras.models import Sequential
from keras.layers import Dense
from keras.backend import clear_session3) 모델 선언
여기서 Dense의 1은 output_shape(nfeatures에 있는 것들 합친것)
nfeatures = x_train.shape[1] #num of columns
nfeatures
# 메모리 정리
clear_session()
# Sequential 타입 모델 선언
model = Sequential( Dense(1, input_shape = (nfeatures,)) )
# 모델요약
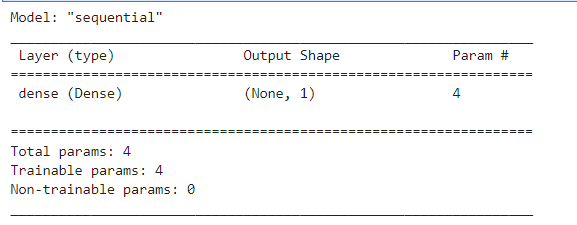
model.summary()
model.compile(optimizer='adam', loss='mse')
4) 학습
model.fit(x_train, y_train)5) 예측
pred = model.predict(x_val)6) 검증
print(f'RMSE : {mean_squared_error(y_val, pred, squared=False)}')
print(f'MAE : {mean_absolute_error(y_val, pred)}')
print(f'MAPE : {mean_absolute_percentage_error(y_val, pred)}')
안녕하세요. 꾸준히 기록하는 hyowon입니다.