0. 개요 및 데이터 준비와 성능 예측
주제 : 머신러닝. 머신러닝의 전체 과정의 코드 실습
내용 : 이를 통해, 앙상블 모델을 완벽하게 구현해 낼 수 있다.
1. 앙상블 이해
- 통합은 힘이다.
- 약한 모델이 올바르게 결합하면 더 정확하고 견고한 모델을 얻을 수 있다!
- 앙상블의 랜덤포레스트, XGBoost, LightGBM 잘 이해하기!
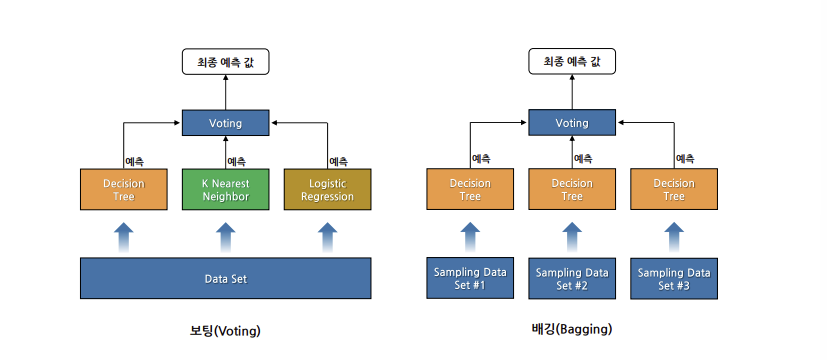
1) 보팅
- 여러 모델들의 예측 결과를 투표를 통해 최종 예측 결과를 결정하는 방법
- 하트 보팅 : 다수 모델이 예측한 값이 최종 결괏값
- 소프트 보팅 : 모든 모델이 예측한 레이블 값의 결정 확률 평균을 구한 뒤 가장 확률이 높은 값을 최종 선택
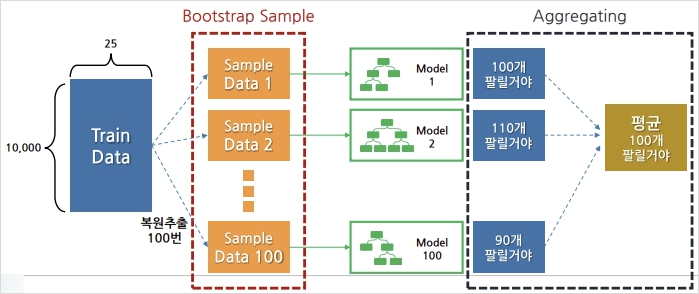
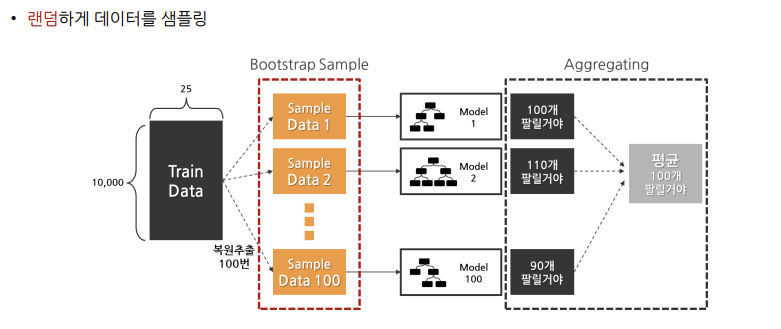
2) 배깅
- Bootstrap Aggregating의 약자
- 데이터로부터 부트스트랩 한 데이터로 모델들을 학습시킨 후, 모델들의 예측 결과를 집계해 최종 결과를 얻는 방법
- 같은 유형의 알고리즘 기반 모델들을 사용
- 데이터 분할 시 중복을 허용
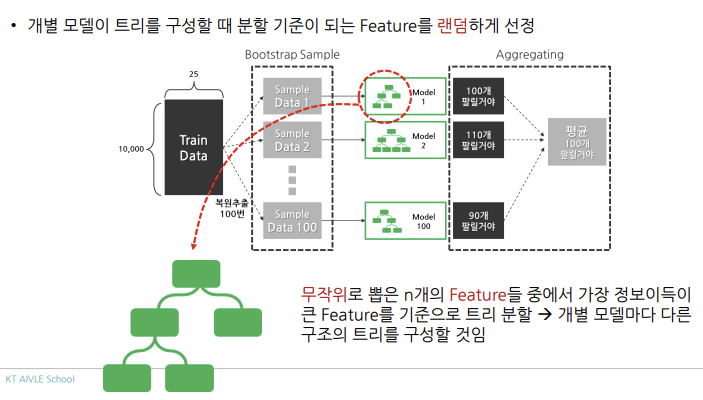
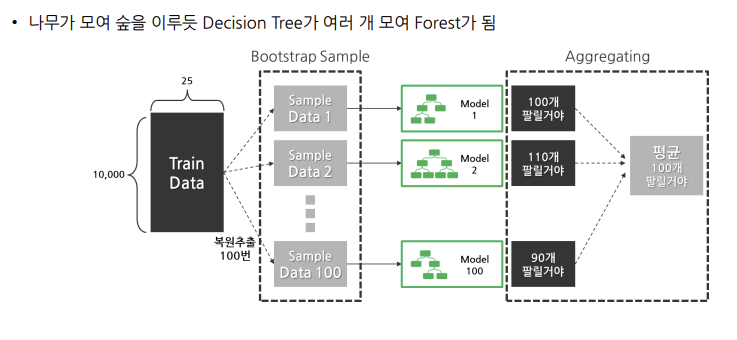
2-1) 랜덤 포레스트
- 배깅의 가장 대표적인 알고리즘
- 여러 Decision Tree 모델이 전체 데이터에서 배깅 방식으로 각자의 데이터 샘플링
- 모델들이 개별적으로 학습을 수행한 뒤 모든 결과를 집계하여 최종 결과 결정
3) 부스팅
- 같은 유형의 알고리즘 기반 모델 여러 개에 대해 순차적으로 학습을 수행
- 이전 모델이 제대로 예측하지 못한 데이터에 대해서 가중치를 부여하여 다음 모델이 학습과 예측을 진행하는 방법
- 대표적인 부스팅 알고리즘 : XGBoost, LightGBM
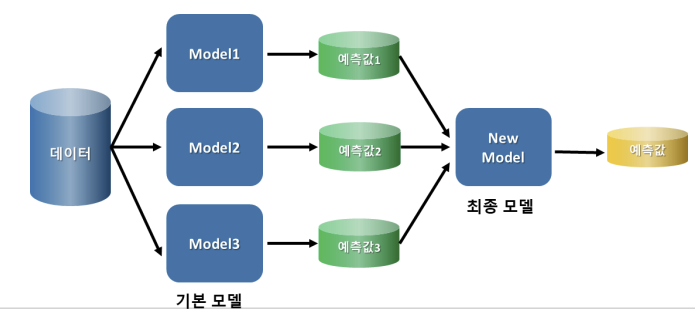
4) 스태킹
- 여러 모델의 예측 값을 최종 모델의 학습 데이터로 사용하여 예측하는 방법
- 예를 들면, KNN, Logistic Regression, XGBoost 모델을 사용해 4종류 예측값을 구한 후 이 예측 값을 최종 모델인 Randomforest 학습 데이터로 사용
4-1) Random Forest(회귀, 분류 모델 구현)
회귀모델 구현
# 불러오기
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = RandomForestRegressor(max_depth=5, n_estimators=100, random_state=1)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))분류모델 구현
# 불러오기
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = RandomForestClassifier(max_depth=5, n_estimators=100, random_state=1)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))4-2) XGBoost 회귀, 분류모델 구현
회귀모델 구현
# 불러오기
from xgboost import XGBRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = XGBRegressor(max_depth=5, n_estimators=100, random_state=1)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))분류모델 구현
# 불러오기
from xgboost import XGBClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = XGBClassifier(max_depth=5, n_estimators=100, random_state=1)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
안녕하세요. 꾸준히 기록하는 hyowon입니다.