0. 개요
주제 : 변수중요도
목표 : 데이터를 분석함에 있어 변수 중요도가 굉장히 중요함을 느낀다. 프로젝트를 하면서 반드시 필요했던 부분들을 숙지해보자!
1. 변수중요도(Feature Importance)
변수 중요도 : 모델 전체에서 어떤 feature가 중요한지 알려주는 것
Tree Based Model
Tree 기반 모델은 Feature Importance를 제공한다. Decision Tree, Random Forest, XGB … 등등.
1) Decision Tree
Decision Tree에서는 Mean Decrease Impurity(MDI)로 표현한다. Tree 전체에 대해서, feature 별로 Information Gain의 (가중) 평균을 계산한다. (Information Gain : 지니 불순도가 감소하는 정도.)
2) Random Forest
Random Forest에서는 각 트리 모델의 변수 중요도의 평균이다.
3) XGB
XGBoost에서는 변수 중요도를 계산하는 3가지 방법이 있다.
weight
모델 전체에서 해당 feature가 split 할 때 사용된 횟수의 합
plot_importance에서의 기본값
gain
feature 별 평균 information gain
model.featureimportances의 기본값
total_gain : feature 별 information gain의 총합
cover
feature가 split 할 때 샘플 수의 평균
total_cover : 샘플수의 총합
2. 변수 중요도 시각화
- feature_importances__ 속성 값으로 변수 중요도 확인
- Feature 순서대로 값을 가짐
- 값이 클 수록 Feature의 중요도가 높음
- 트리 구성에 중요한 역할을 한 변수를 시각화해서 확인할 수 있음
- 가로 막대 또는 세로 막대 그래프로 시각화
# 변수 중요도 시각화
plt.figure(figsize=(6, 8))
plt.barh(list(x), model.feature_importances_)
plt.ylabel('Features')
plt.xlabel('Importances')
plt.show()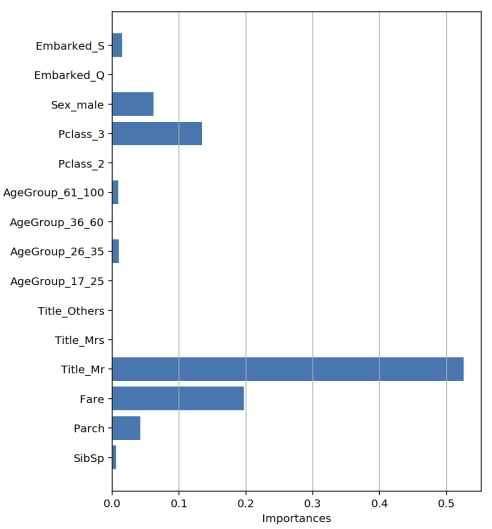

안녕하세요. 꾸준히 기록하는 hyowon입니다.