0. 개요 및 복습
주제 : 딥러닝
목표 : 머신러닝에서 나아가 딥러닝에 대해 배워 보자!
1) 복습 : 모델의 성능
모델의 성능은 오차를 통해 계산됩니다.
- 모델링 : train error를 최소화 하는 모델을 생성하는 과정
- 모델 튜닝 : validation error를 최소화 하는 모델 선정

코드 순서
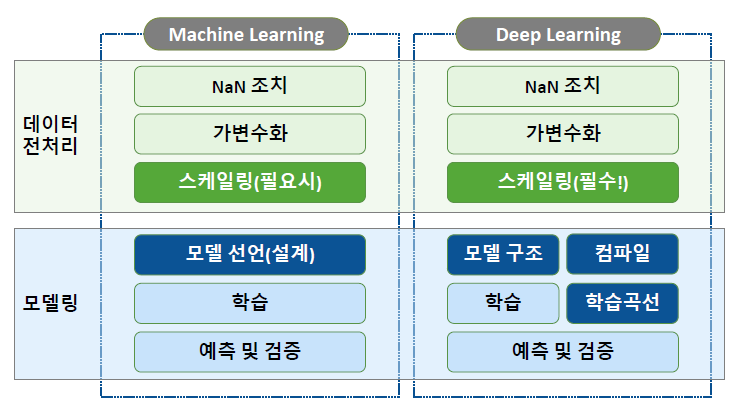
2) 전체 코드 정리(히든 레이어 추가)
# 데이터 전처리
target = 'medv'
x = data.drop(target, axis = 1)
y = data.loc[:, target]
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 20)
# 스케일링
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)
# 모델링
nfeatures = x_train.shape[1] #num of columns
nfeatures
# 메모리 정리
clear_session()
# Sequential 타입 모델 선언(레이어 여러 개 입력은 리스트로)
model3 = Sequential([ Dense(2, input_shape = (nfeatures,), activation = 'relu'),
Dense(1) ])
# 모델요약
model3.summary()
# 컴파일
model3.compile( optimizer= Adam(learning_rate=0.1), loss = 'mse')
# 학습
hist = model3.fit(x_train, y_train, epochs = 50 , validation_split= .2 ).history
# 평가
pred3 = model3.predict(x_val)
print(f'RMSE : {mean_squared_error(y_val, pred3, squared=False)}')
print(f'MAE : {mean_absolute_error(y_val, pred3)}')
print(f'MAPE : {mean_absolute_percentage_error(y_val, pred3)}')1. 딥러닝 개념
딥러닝 학습 절차
- 가중치 초기값을 할당합니다. (초기 모델을 만든다.)
- model.fit(x_train,y_train) 하면 열심히 가중치 조절한다!
- 초기 모델로 예측한다.
- 오차를 계산한다.(loss function)
- 오차를 줄이는 방향으로 가중치를 조금 조절한다.(optimizer)
- 다시 처음으로 가서 반복한다.(epoch)
2. 딥러닝 모델링 - 회귀
1) 딥러닝 전처리 : 스케일링
- 딥러닝은 스케일링을 필요로 합니다.
- 방법 1 : Normalization(정규화)
- 모든 값의 범위를 0~1로 변환
- 방법 2 : Standardization(표준화)
- 모든 값을, 평균 0, 표준편차 = 1로 변환
# 스케일러 선언
scaler = MinMaxScaler()
# train 셋으로 fitting 적용
x_train = scaler.fit_transform(x_train)
# validation 셋은 적용만!
x_val = scaler.transform(x_val)2) 딥러닝 - Process
딥러닝의 각 단계는
- 이전 단계의 Output을 Input으로 받아 처리 후 다음 단계로 전달한다.
- nfeatures로 총 feature의 개수를 파악한다(nfeatures 정의도 해줘야)
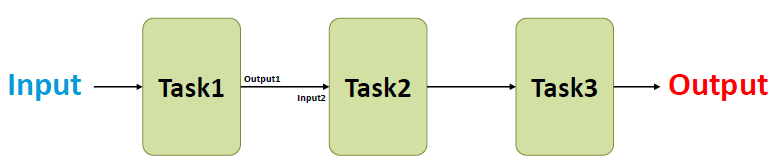
# nfeatures 정의 및 확인
nfeatures = x_train.shape[1]
nfeatures
# 메모리 정리
clear_session()
# Sequential 타임
model = Sequential([Dense(1, input_shape(nfeatures,))])
# 모델 요약
model.summary()
3) 딥러닝 코드 - compile
컴파일
- 선언된 모델에 대해 몇가지 설정을 한 후, 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
loss function(오차함수)
- 오차 계산을 무엇으로 할지 결정
- mse : 회귀모델은 보통 mse로 오차 계산
optimizer
- 오차를 최소화 하도록 가중치를 조절하는 역할
- optimizer = 'adam' : learning_rate 기본값 = 0.001
- optimizer = Adam(learning_rate=0.1) 과 같이 조절 가능
model.compile(optimizer = Adam(learning_rate=0.1), loss = 'mse')
4) 딥러닝 코드 - 학습
epochs 반복횟수
- 가중치 조절 반복 횟수
- 전체 데이터를 몇 번 학습할 것인지 정해 준다.
**validation_split = 0.2- train 데이터에서 20%를 검증셋으로 분리
**history- 학습을 수행하는 과정 중에 가중치가 업데이트 되면서 그때그때마다 성능을 측정하여 기록
- 학습시 계산된 오차 기록
history = model.fit(x_train, y_train, epochs = 20, validation_split = 0.2).history

5) 딥러닝 구조 - Hidden layer
- layer 여러 개 : 리스트[ ]로 입력
- hidden layer
- input_shape는 첫번째 layer만 필요
- activation
- 히든 레이어는 활성함수를 필요로 합ㄴ디ㅏ.
- 활성함수는 보통 'relu'사용
- output layer
- 예측 결과가 1개
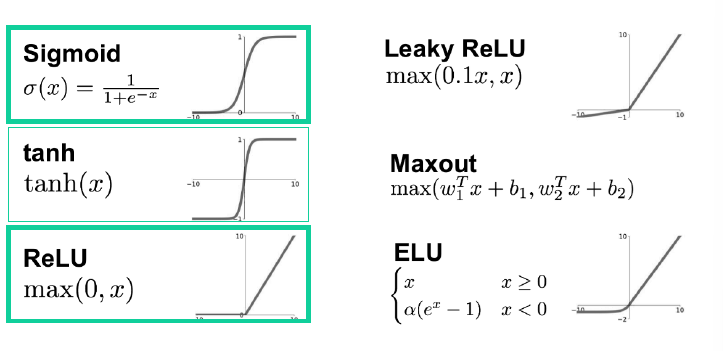
활성화 함수
- 활성화 함수
- 현재 레이어(각 노드)의 결과값을 다음 레이어(연결된 각 노드)로 어떻게 전달할지 결정/변환해주는 함수
이게 없으면 히든 레이어를 아무리 추가해도 그냥 선형회귀가 된다!!
- Hidden Layer에서는 : 선형함수를 비선형함수로
- Output Layer에서는 : 결과값을 다른 값으로 변환해 주는 역할
- 주로 분류 모델에서 필요

안녕하세요. wony입니다.