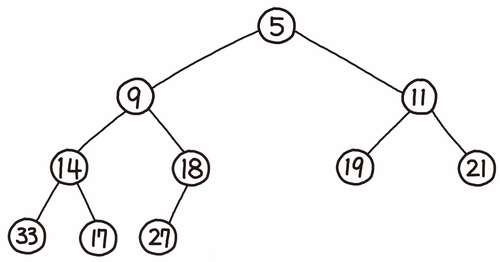
힙(Heap)은 힙 속성을 항상 만족하는 거의 완전한 트리를 기반으로 하는 자료구조로, 최솟값 또는 최댓값을 효율적으로 얻고자 고안되었다.
힙은 힙 정렬 알고리즘을 고안하면서 설계된 것으로, 사실상 힙은 힙 정렬의 부산물이라고 할 수 있다.
힙 속성(Heap Property):
부모-자식 노드 간에 항상 일정한 대소관계가 성립함
최소 힙(Min Heap) : 부모의 값이 자식의 값보다 항상 작은 힙
최대 힙(Max Heap) : 부모의 값이 자식의 값보다 항상 큰 힙
힙 속성에 따라 루트 노드는 힙의 최댓값 또는 최솟값을 가지므로, 최솟값 또는 최댓값을 O(1)에 얻을 수 있다.
힙은 힙 속성을 항상 만족한다는 점 덕분에 아주 유용하다.
원래 용도인 힙 정렬뿐만 아니라, 우선순위 큐 구현에 주로 활용된다.
또한 다익스트라 알고리즘(Dijkstra's algorithm)의 시간 복잡도를 O(V^2)에서 O(E log V)로 줄일 수 있었다.
이 외에도 프림 알고리즘(Prim's algorithm) 등에서도 활용되며, 중앙값의 근사값을 빠르게 구할 때에도 활용할 수 있다.
주로 삽입, 삭제의 속도를 위해 주로 완전 이진 트리로 구현된다.
따라서 데이터의 삽입과 삭제 모두 O(log N)이 소요된다.
완전 이진 트리는 다음와 같이 배열로 간단히 구현할 수 있다.
2 * (부모 노드의 좌표) = (왼쪽 자식 노드의 좌표)
인덱스 계산을 편하게 하기 위해 주로 0번 인덱스를 비워두고 1번 인덱스부터 사용하는 경우가 많다.
루트의 좌표가 0인 경우 2 * (부모 노드의 좌표) + 1 = (왼쪽 자식 노드의 좌표)이다.
왼쪽 자식 노드의 좌표에 1을 더하면 오른쪽 자식 노드의 좌표가 된다.
구현 [Python]
우선 전체 코드를 한 번에 살펴보면 다음과 같다.
class BinaryHeap:
def __init__(self):
self.items = [None]
def __len__(self):
return len(self.items) - 1
def _percolate_up(self, i):
if i == 1:
return
parent = i // 2
if self.items[i] < self.items[parent]:
self.items[i], self.items[parent] = \
self.items[parent], self.items[i]
self._percolate_up(parent)
def insert(self, item):
self.items.append(item)
self._percolate_up(len(self))
def _percolate_down(self, i):
left = 2 * i
right = left + 1
smallest = i
if left <= len(self) and self.items[left] < self.items[smallest]:
smallest = left
if right <= len(self) and self.items[right] < self.items[smallest]:
smallest = right
if smallest != i:
self.items[i], self.items[smallest] = \
self.items[smallest], self.items[i]
self._percolate_down(smallest)
def extract(self):
extracted = self.items[1]
self.items[1] = self.items[len(self)]
self.items.pop()
self._percolate_down(1)
return extracted
데이터 삽입
- 추가하려는 노드를 힙의 맨뒤에 추가한다.
- 추가한 노드와 그것의 부모 노드를 비교한다.
- 힙 속성을 만족하면 삽입 과정을 종료한다. 그렇지 않으면 두 노드를 스왑하고 과정2로 되돌아간다.
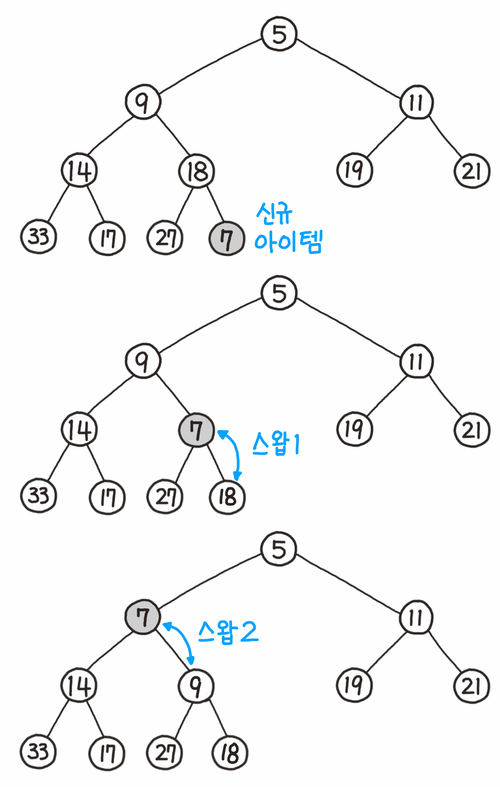
이를 파이썬으로 구현한 코드는 아래와 같다.
def _percolate_up(self, i):
if i == 1:
return
parent = i // 2
if self.items[i] < self.items[parent]:
self.items[i], self.items[parent] = \
self.items[parent], self.items[i]
self._percolate_up(parent)
def insert(self, item):
self.items.append(item)
self._percolate_up(len(self))데이터 삭제
- 힙의 맨뒤 노드를 루트 노드에 삽입한다.
- 루트로 삽입된 노드와 그것의 자식 노드와 비교한다.
- 힙 속성을 만족하면 삭제 과정을 종료한다. 그렇지 않으면 더 작은 자식 노드와 루트에 삽입된 노드를 스왑하고 과정2로 되돌아간다.
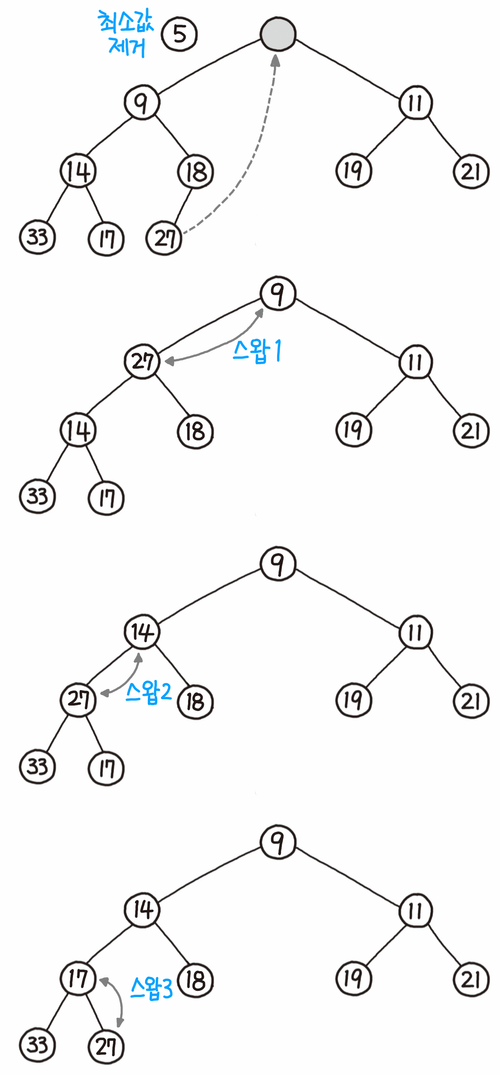
이를 파이썬으로 구현한 코드는 다음과 같다.
def _percolate_down(self, i):
left = 2 * i
right = left + 1
smallest = i
if left <= len(self) and self.items[left] < self.items[smallest]:
smallest = left
if right <= len(self) and self.items[right] < self.items[smallest]:
smallest = right
if smallest != i:
self.items[i], self.items[smallest] = \
self.items[smallest], self.items[i]
self._percolate_down(smallest)
def extract(self):
extracted = self.items[1]
self.items[1] = self.items[len(self)]
self.items.pop()
self._percolate_down(1)
return extracted힙 vs 이진 탐색 트리(BST)
그렇다면 힙과 이진 탐색 트리의 차이점은 무엇일까?
힙은 상하 관계를 보장하며, 이진 탐색 트리는 좌우 관계를 보장한다고 할 수 있다.
BST는 left_child < node < right_child를 만족한다.
이러한 특징으로 인해 모든 값이 정렬되어야 할 때 사용한다.
반면 힙은 최솟값 또는 최댓값을 탐색할 때 사용하게 된다.
이진 힙은 이 작업을 O(1)에 수행할 수 있어 효율적이다.

시각 자료 출처 :
https://namu.wiki/w/힙%20트리