- 시계열 데이터란?
-
행과 행에 시간의 순서가 있는 데이터
-
행과 행의 시간간격이 동일한 데이터
그렇다면 질문?
-
시간이 1분 단위가 아닌 뒤죽박죽일 경우 시계열 데이터를 사용할 수 있는가?
⇒ 네! ex) 어떻게든 균일한 시간으로 바꾸거나 불규칙한 간격을 그대로 두고 사용가능합니다.
-
일별 데이터인데 특정 날에 3개의 row 데이터가 있어도 사용 할 수 있나요?
⇒ 네! ex) 같은 날짜의 데이터를 집계하거나, 평균, 합계 방식으로 축소 할 수 있어요.
-
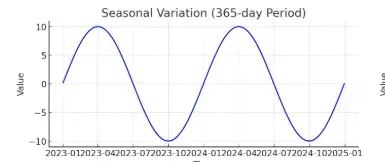
1. 계절변동 (Seasonal Variation)
- 특징: 일정한 주기(예: 일별, 주별, 월별)로 반복되는 변동.
- 설명: 계절적, 환경적 요인에 의해 정기적으로 나타나는 패턴.
- 센서 데이터 예시:
- 에너지 소비 센서: 여름철에는 에어컨 사용으로 전력 소비 증가, 겨울에는 난방 기기로 인해 증가.
- 환경 센서: 계절별로 온도·습도가 주기적으로 변화.
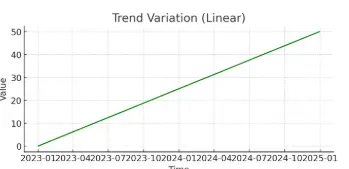
2. 추세변동 (Trend Variation)
- 특징: 시간이 지남에 따라 지속적으로 증가하거나 감소하는 경향.
- 설명: 데이터의 장기적인 상승 또는 하락 패턴.
- 센서 데이터 예시:
-
기계 부품 마모 센서: 사용 시간이 길어질수록 진동 센서 값이 점점 증가.
-
산업용 온도 센서: 여름철 공장 기기 사용 증가로 인해 장기적으로 기온이 상승.
-
배터리 전압 센서: 배터리 수명이 줄어들면서 전압이 지속적으로 감소.
-
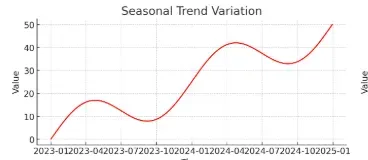
3. 계절적 추세변동 (Seasonal Trend Variation)
- 특징: 계절성과 추세가 결합된 변동.
- 설명: 계절적인 패턴이 반복되면서, 장기적으로 증가 또는 감소하는 추세도 함께 나타나는 형태.
- 센서 데이터 예시:
-
에너지 소비 센서: 점점 증가하는 전력 사용량(추세) + 계절별 변동.
-
스마트팜 환경 센서: 계절에 따라 온도·습도가 반복되면서, 장기적으로 기온 상승.
-
교통량 센서: 매년 도심 차량 수가 증가하면서, 출퇴근 시간 패턴이 반복됨.
-
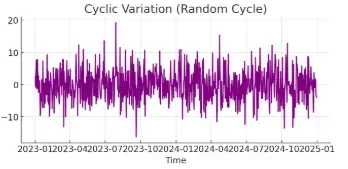
4. 순환변동 (Cyclic Variation)
- 특징: 경제적, 환경적 요인에 의해 발생하는 불규칙적이고 주기가 일정하지 않은 변동.
- 설명: 계절성과 다르게 일정한 주기가 없으며, 장기적인 변화에 따라 변동.
- 센서 데이터 예시:
-
환경 센서: 미세먼지 수치가 특정 시기에 따라 불규칙적으로 증가.
-
공장 생산 라인 센서: 제품 수요 변화에 따라 가동률이 높아졌다 낮아졌다 반복됨.
-
전력망 센서: 에너지 수급 정책 변화에 따라 전력 소비 패턴이 바뀜.
-
5. 우연변동 (White Noise)
- 특징: 예측 불가능하고 규칙성이 없는 무작위 변동.
- 설명: 시계열 데이터에 포함된 노이즈 또는 오류로, 예측을 어렵게 만드는 변동.
- 센서 데이터 예시:
-
기계 진동 센서: 특정 순간 기계 이상으로 인해 갑자기 높은 진동 수치가 기록됨.
-
온도 센서: 갑작스러운 환경 변화(강풍, 폭우)로 인해 온도가 급격히 변동.
-
네트워크 트래픽 센서: 사이버 공격이나 예기치 못한 사용량 급증으로 인해 데이터 전송량이 급격히 변동.
-
- 시계열 다루는 방법
-
날짜를 년, 월, 일로 나누기
2024-01-02 ⇒ 2024, 01, 02
2024-01-03 ⇒ 2024, 01, 03
2024-01-04 ⇒ 2024, 01, 04
2024-01-05 ⇒ 2024, 01, 05
2024-01-06 ⇒ 2024, 01, 06주기성이나, 특정 날짜와 같은 세부적인 정보를 모델에 제공하는 방법
1) 월별/분기별/계절별 패턴을 모델이 인식
2) 다양한 주기적인 변동 예측 가능
3) 계절성이나 주말/평일 차이를 반영
-
2. Lag Feature
2.1. 정의 및 개념
- 정의:
1) 시계열 데이터에서 과거의 관측값(시차, lag)을 현재 또는 미래의 예측 변수로 활용하는 것을 말함
예를 들어) 시계열 yt에 대해 yt-1,yt-2 등 과거의 값을 피처(feature)로 추가함으로써, 데이터의 자기상관성을 모델이 학습할 수 있도록 도와줌 - 왜 이렇게 할까요?
- 시계열 데이터는 시간의 흐름에 따라 변화하며, 과거의 상태가 현재와 미래 상태에 영향을 미치는 경향이 있습니다.
- Lag Feature를 통해 이러한 시간적 의존성을 캡처하여, 예측 모델이 더 정확한 예측을 할 수 있게 합니다.
2.2. 중요성 및 활용 이유
- 자기상관성(correlation) 포착:
- 많은 시계열 데이터는 자기상관성이 존재합니다. 즉, 일정 시간 간격으로 과거의 데이터가 현재의 데이터에 영향을 미치기 때문에, lag feature를 추가하면 모델이 이 패턴을 학습할 수 있습니다.
- 자기상관성 이란? : 시계열 데이터에서 특정 시점의 값이 과거의 값들과 얼마나 연관되어 있는지
- 자기상관성이 높으면 과거 데이터가 현재 데이터와 강한 관계를 가짐.
- 자기상관성이 낮거나 0에 가까우면 이전 값과 현재 값이 독립적임.
- 예측 성능 향상:
- 과거의 데이터 정보를 활용하면 단순 시계열 모델보다 더 정교한 예측이 가능합니다. 예를 들어, 주식 가격, 기상 데이터, IoT 센서 데이터 등에서 이전 값들이 중요한 예측 신호로 작용합니다.
- 모델 해석성 강화:
- 어떤 시점의 과거 값이 예측에 어떤 영향을 미치는지 분석할 수 있어, 모델 해석 및 의사 결정 과정에 도움을 줍니다.
- 다양한 응용 분야:
-
금융, 에너지, 제조, 물류 등 여러 도메인에서 Lag Feature는 중요한 입력 변수로 활용됩니다.

-
3. Rolling Statistics
3.1. 정의 및 개념
- 정의: Rolling Statistics는 일정한 윈도우(window) 내에서 계산되는 통계량을 의미 대표적으로 이동 평균(rolling mean), 이동 표준편차(rolling std) 등이 있으며, 윈도우 내의 데이터 분포나 변동성을 파악하는 데 유용합니다.
- 중요성:
- 노이즈 완화: 이동 평균은 데이터의 단기적인 노이즈를 줄이고 장기적인 추세를 부각시킵니다.
- 변동성 분석: 이동 표준편차 등은 데이터의 변동성을 평가하여, 급격한 변화나 이상치를 식별하는 데 도움이 됩니다.
- 지역적 패턴 포착: 시계열의 국부적인 특성을 반영함으로써, 예측 모델에 지역적 패턴 정보를 제공할 수 있습니다.
3.2. 생성방법
-
Pandas의
rolling()사용:rolling(window=n)함수로 지정한 n 크기의 윈도우 내에서 평균, 표준편차, 분산 등을 계산할 수 있습니다. -
윈도우 크기 선택:데이터의 특성에 따라 적절한 윈도우 크기를 선택하는 것이 중요합니다. 너무 짧으면 노이즈가 남고, 너무 길면 세부 패턴을 놓칠 수 있습니다.
-
윈도우 내 함수 적용:
.mean(),.std(),.min(),.max()등 다양한 통계 함수를 윈도우에 적용할 수 있습니다.
- 중요성:
