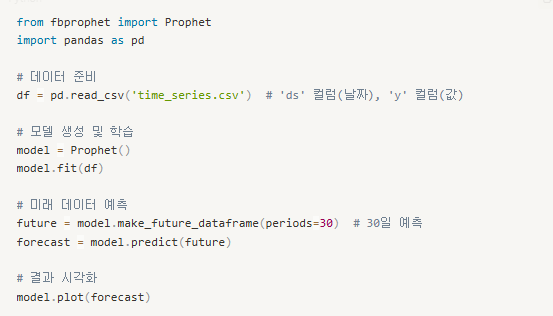
01. 통계적 시계열 모델 전처리
- statsmodels 라이브러리
시계열 데이터를 추세, 계절성, 불규칙성 성분으로 나누어 plot 그리는 작업

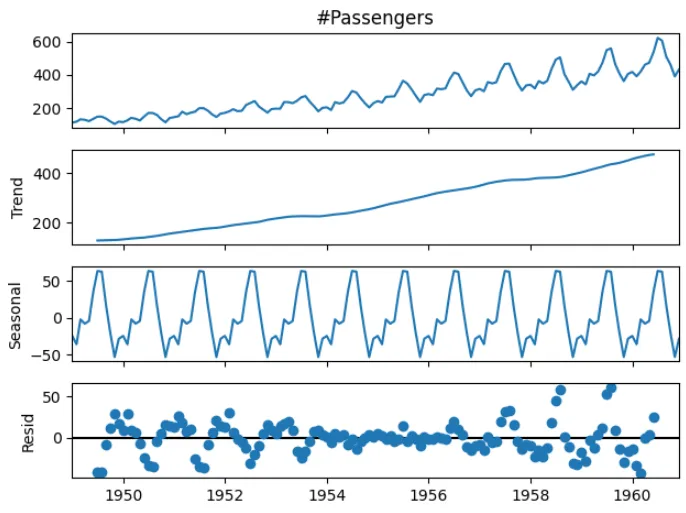
period ⇒ 1년 기준으로 주기를 나타내는 변수(월별 데이터면 12, 주별 데이터면 52, 일별데이터면 365)
1) Additive (덧셈 모델)
시계열 데이터=추세+계절성+잔차 (변화량이 일정한 크기로 발생하는 데이터에 적합)
즉, 계절성의 크기가 일정한 경우에 사용
2) multiplicative(곱셈 모델)
시계열 데이터=추세×계절성×잔차 (분들이 곱해지는 모델로, 변화가 비율적으로 발생하는 데이터에 적합)
즉, 계절성이 증가하거나 감소하는 경우에 사용
3) 잔차 (Residuals)
원본 데이터에서 추세와 계절성을 제거한 후 남는 변동성
만약, 잔차(Residual)에 특정 패턴이 보이면 추가적인 계절성이나 주기성이 존재할 가능성이 있음
- 비정상성과 정상성
통계적 모델은 비정상 데이터를 정상성 데이터로 변환해야함
단, 통계적 모델이 아닌 경우, 정상성 데이터로 변환하지 않아도 됨
-
비정상성 데이터란?
- 시간이 지날수록 데이터의 평균(Trend)이 증가/감소하는 경우
- 계절성(Seasonality) 이 포함되어 특정 주기마다 패턴이 달라지는 경우
- 시간이 지날수록 데이터의 변동성(Variance)이 증가하는 경우-
정상성 데이터란?
정상적이다. (Stationary) = 안정적이다.
- 추세(Trend)나 계절성이 없고, 데이터의 평균과 분산이 일정한 경우
- 주어진 시간 간격에서 변동성이 안정적이며 예측 가능한 수준
- 시계열의 통계적 특징(평균, 분산, 자기 상관)이 변하지 않는다. (일정한 패턴을 유지)
- 랜덤한 움직임을 가지지만, 시점마다 유사하게 동작하는 특징이 있어 시간에 따라 안정된 분포를 갖는다.
(1) 모든 시점 t에 대해 평균이 같다.
(2) 모든 시점 t에 대해 분산이 같다.
(3) 자기 공분산 (자기 상관관계)이 시간이 아닌 시차에 의존한다.
정상적이지 않은 시계열 데이터의 경우?
- 로그 변환: 분산이 커지는 경향을 가지는 시계열을 안정화
- 차분: 추세를 제거하는 효과
- 계절차분: 계절추세를 제거하는 효과
-
왜 비정상성데이터를 정상성 데이터로 변화해야할까?
시계열 데이터가 정상성을 띠고 있어야 ARIMA 분석을 통해 미래 시계열 값을 예측할 수 있음
시계열 데이터가 비정상성을 띤다면 평균과 분산이 다르기 때문에 임의의 시점 t-1, t에서 얻은 모델은 t+1~t+n에서 사용할 수 없게 됨 -
비정상성 데이터를 정상성 데이터로 변화하는 방법
1) 차분
트렌드(추세)를 제거하여 데이터를 정상성으로 만드는 방법

-
2) 로그 변환
지수적 성장이나 비대칭적인 분포를 선형적이고 정규분포에 가까운 형태로 변환.

3) 로그 차분
로그 차분(Log Differencing) 은 시계열 데이터에서 트렌드(추세)와 변동성(Variance)을 동시에 안정화하기 위해 사용하는 변환 기법

4) 계절 차분
일정한 주기로 반복되는 계절성(Seasonality)을 제거하는 방법
02. ARIMA모델
- ACF, PACF
- ACF (자기상관 함수): 시계열 데이터의 특정 시점과 이전 시점 간의 상관 관계를 나타내는 함수입니다. 시계열 데이터의 전체적인 패턴을 파악하는 데 유용하며, 데이터가 얼마나 주기적으로 반복되는지를 알 수 있습니다.

- PACF (부분 자기상관 함수): 자기상관 함수에서 단순히 이전의 시점 간 상관만을 고려하는 것이 아니라, 특정 시점의 값이 이전의 값들과 어떻게 관계가 있는지를 고려하여 직접적인 상관만을 추출하는 함수입니다.

- ARIMA 모델
ARIMA 모델은 시계열 데이터의 자기상관성(AR), 차분(D), 이동 평균(MA)을 이용해 미래 값을 예측하는 시계열 통계 모델입니다.

ARIMA(p, d, q)가 중요/ ARMA(p,q)
d : 시계열 plot을 보고 정상성 여부를 확인하고, 차분을 진행하고, 차분 후의 plot을 보고 여부를 확인하는 프로세스로 진행한다.
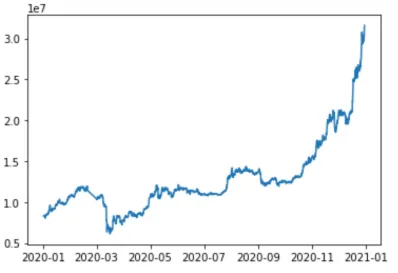
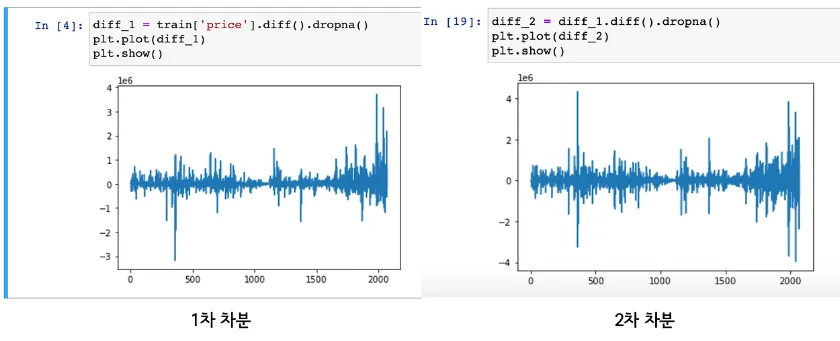
1차 차분으로도 트렌드(추세)가 완전히 제거되지 않는 경우 추가적으로 2차 차분을 적용하여 데이터의 평균과 분산을 일정하게 만듬
ARIMA(1,2,0)
p, q의 경우 보통 ACF와, PACF를 보고 결정
p: PACF에서 첫 번째 유의미한 지점(즉, 자기상관이 급격히 0으로 떨어지는 시점)을 p 값
q: ACF에서 첫 번째 유의미한 지점(즉, 자기상관이 급격히 0으로 떨어지는 시점)을 q 값
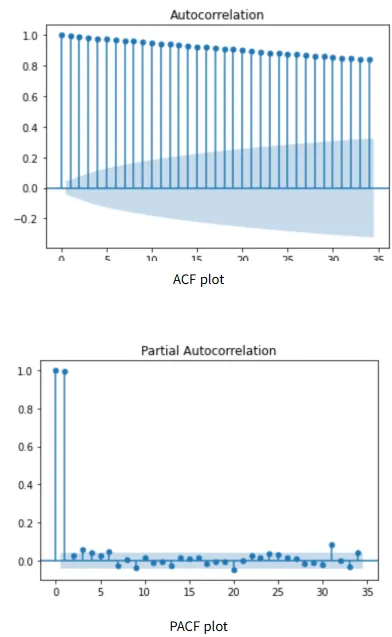
결론 : ARIMA(1, 2, 0)
ACF와 PACF를 통해서 비정상성 분석이 가능
- ACF 값이 느리게 감소(서서히 감소)하는 패턴을 보임 ⇒ 트렌드(추세, Trend)를 포함하고 있을 가능성이 높음
- 여러 시차(Lag)에서 지속적으로 유의미한 값 → 추세(Trend) 제거 필요
특정 주기마다 강한 피크를 가짐 → 계절성(Seasonality) 제거 필요
AR(p)
현재 값이 과거 값들의 선형 결합으로 표현되는 모델(추세가 강한데이터)
MA(q)
현재 값이 과거 오차(White noise)의 선형 결합으로 표현되는 모델
과거의 오차를 기반으로 미래를 예측
AR(p)+MA(q)
자기회귀(AR) + 이동 평균(MA) 요소를 동시에 반영
- SARIMA 모델 ✅ 정의:
-
ARIMA 모델에 계절성(Seasonality)을 추가한 확장 모델
✅ 수식:
-
(p, d, q): ARIMA의 일반적인 차수
-
(P, D, Q, s): 계절성 차수
-
P: 계절성 자기회귀(Seasonal AR)
-
D: 계절 차분(Seasonal Differencing)
-
Q: 계절성 이동 평균(Seasonal MA)
-
s: 계절 주기(예: 월별 데이터 → 12, 주별 데이터 → 52)
(P, D, Q, s) 찾기
-
s (계절 주기) 결정
- 데이터가 주별이면
s=52, 월별이면s=12사용
- 데이터가 주별이면
-
D (계절 차분 차수) 찾기
- 계절 주기(
s)만큼 차분 수행 후 정상성이 확보되면D=1 - 필요하면 추가 차분
- 계절 주기(
-
P, Q 찾기
- 계절 차분 후, ACF/PACF에서 계절 패턴을 분석하여 결정✅ 특징:
-
계절성이 있는 데이터에 적합
-
비정상성 + 계절성까지 해결 가능
-
-

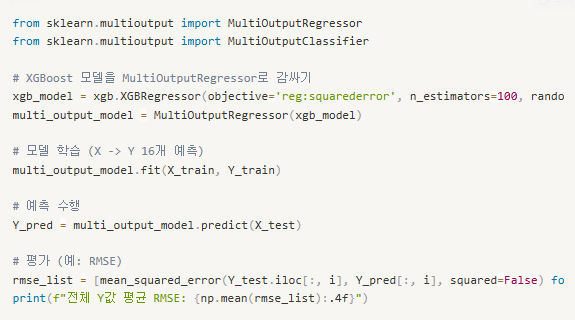
03. 다중 타겟 예측 모델(MultiOutputRegressor, MultiOutputClassifier)
- MultiOutputRegressor, MultiOutputClassifier MultiOutputRegressor : 다중 출력 회귀를 위한 모델
MultiOutputClassifier : 다중 출력 분류를 위한 모델

04. prophet모델
- Prophet (Facebook Prophet)
- 특징: 트렌드, 계절성, 휴일 효과 등을 반영하여 자동으로 예측할 수 있는 모델.
- 장점:
- 빠르고 쉬운 설정 (자동화된 하이퍼파라미터 튜닝 제공)
- 결측치와 이상치에 강함
- 계절성(주간, 월간, 연간) 및 공휴일 등의 외부 요인 반영 가능
- 단점:
- 단순한 선형 모델 기반이므로 복잡한 패턴을 학습하는 데 한계가 있음
- 데이터의 양이 많아야 신뢰도 높은 예측 가능