01. 딥러닝이란?
- 딥러닝의 개요
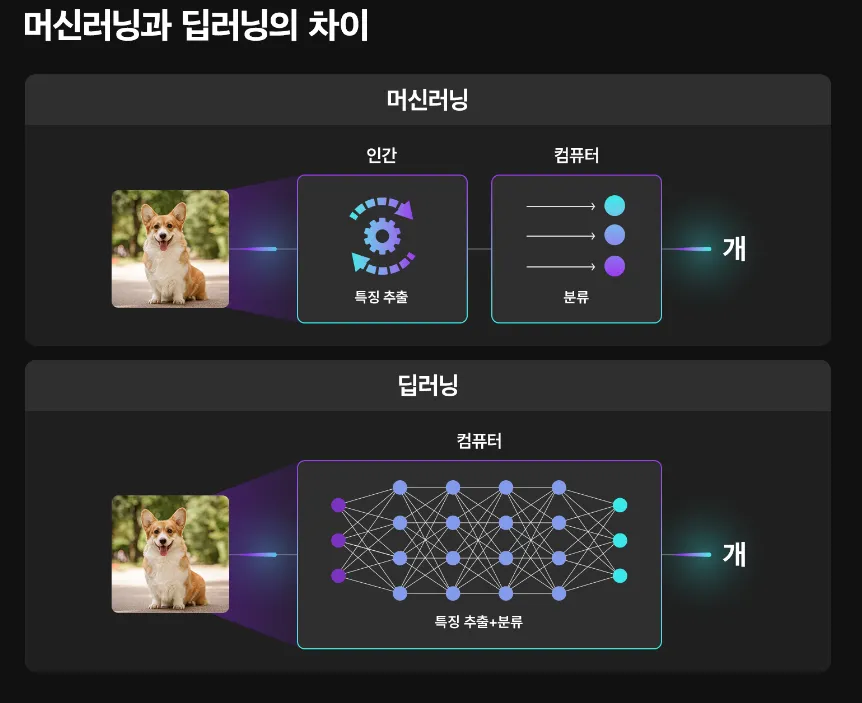
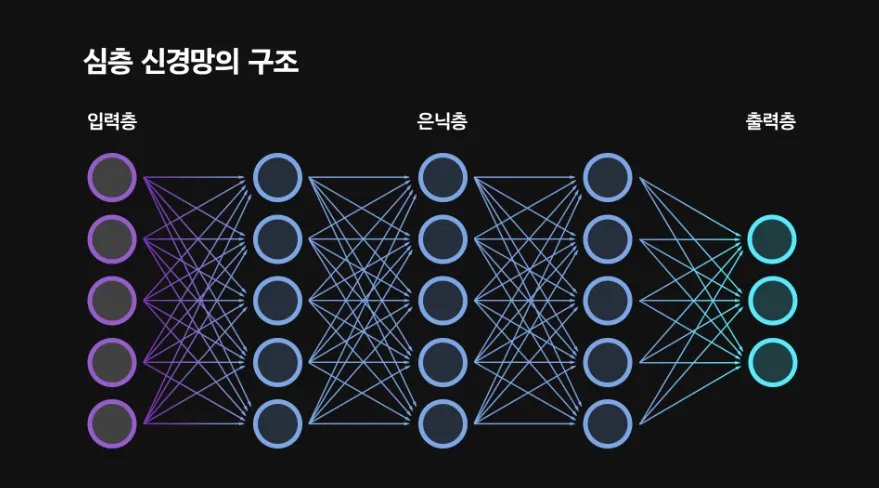
입력층(Input Layer)
입력층은 신경망에 데이터를 제공하는 첫 번째 층이다. 이 층은 외부로부터 데이터를 받아 신경망의 내부로 전달하는 역할을 한다.
예를들어, X값이 3개면 입력층 노드는 3개이다.
은닉층 (Hidden Layer)
은닉층은 데이터의 패턴이나 특징을 학습하는 층이다. 각 은닉층은 이전 층으로부터의 입력값을 받아 처리하고 다음 층으로 결과를 전달한다. 이 과정에서 각 입력값에 특정 가중치를 곱하여 중요한 특징을 더 잘 인식할 수 있게 한다. 은닉층의 수는 문제의 복잡성, 데이터의 양, 그리고 모델의 성능 요구 사항에 따라 다르게 설정된다.
출력층 (Output Layer)
출력층은 신경망의 마지막 층으로 결과나 예측을 나타낸다. 출력층에서는 가능한 답들의 확률을 계산해, 가장 높은 확률을 가진 답을 최종적으로 선택한다.
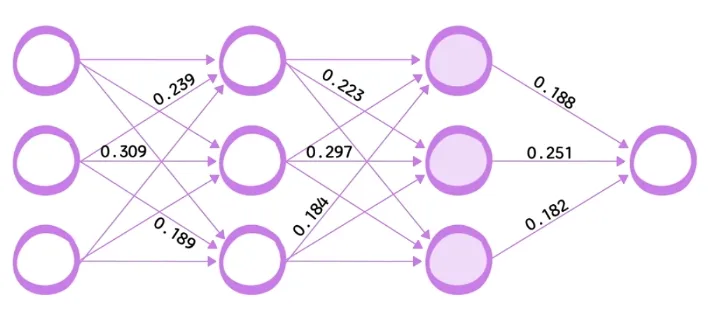
- Y = WX + B
✔W(가중치)와 B(편향)는 처음엔 랜덤값!
✔학습(Training)하면서 오차(Error)를 줄이는 방향으로 W와 B를 수정
✔손실 함수(Loss)로 오차를 계산하고, 경사 하강법(Gradient Descent)으로 조금씩 조정
✔반복하면 W와 B가 점점 정답에 가까워져서 좋은 모델이 됨!
02. pytorch, tensorflow 80% 20%
🔹 1. PyTorch란?
💡 PyTorch는 딥러닝 모델을 쉽게 만들고 학습할 수 있도록 도와주는 프레임워크입니다.
✔ 파이썬(Python) 기반으로 사용하기 편함
✔ 동적 연산(Autograd) 지원 → 즉시 실행 가능
✔ GPU 지원으로 빠르게 계산 가능 ⇒ cpu, gpu ⇒ cuda
✔ 연구자와 개발자가 많이 사용 → 최신 모델 적용 용이
2. PyTorch 기본 문법
✅ 2-1. PyTorch 설치하기
먼저, PyTorch를 설치해야 합니다.
👉 공식 사이트에서 환경에 맞는 설치 방법을 확인하세요.

✅ 2-2. PyTorch 텐서(Tensor)
PyTorch의 기본 데이터 구조는 텐서(Tensor) 입니다.
👉 텐서는 행렬(Matrix)과 비슷하지만, 더 높은 차원의 데이터를 표현할 수 있음.
텐서는 숫자를 담을 수 있는 상자
이 상자는 숫자(데이터)를 저장하고 계산할 수 있는 형태
쉽게 말하면, 텐서는 넘파이 배열(Numpy Array)과 비슷하지만, GPU에서도 빠르게 연산할 수 있는 것!
✅ 텐서 생성 예제

✅ 2-3. 텐서 연산 (Numpy와 유사)
PyTorch 텐서는 넘파이(Numpy)와 유사한 연산이 가능함.

03. LSTM
- LSTM이란?
LSTM을 한 줄로 요약하면?
✔ LSTM은 기억력이 좋은 RNN!(시계열, 시퀀스모델) ✔ 오래된 정보도 기억하면서 중요한 것만 골라 학습하는 모델! ✔ 텍스트, 주가 예측, 날씨 예측, 센서 데이터 같은 "연속된 데이터"에서 강력한 성능을 발휘!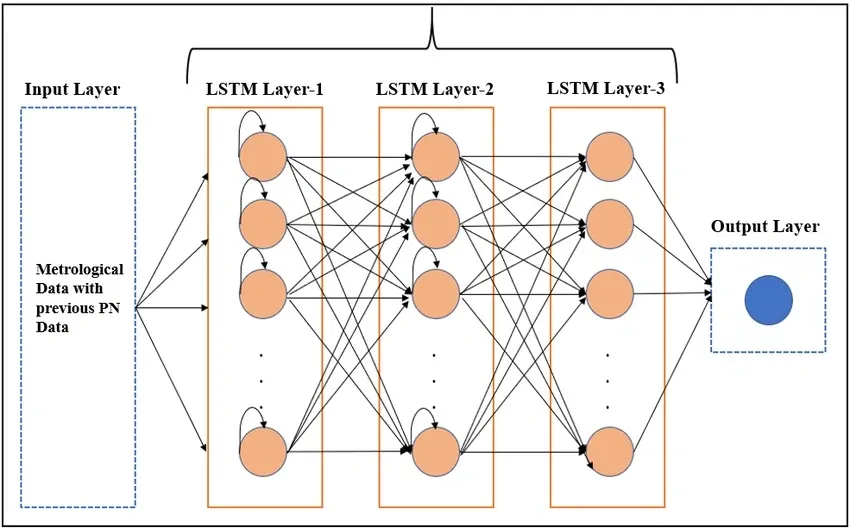
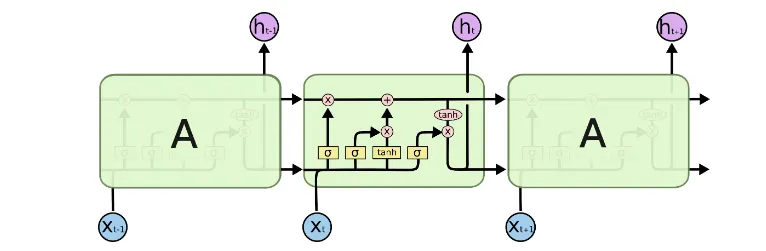
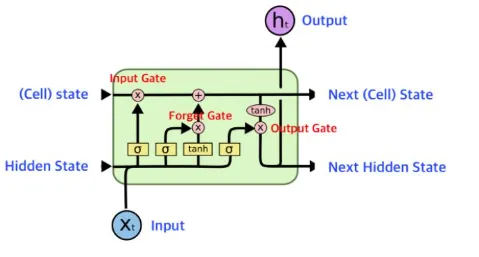
📖 LSTM을 ‘공부하는 학생’으로 비유하기
한 학생이 수업을 듣고 시험을 본다고 가정하자.
이 학생(LSTM)은 단순히 수업 내용을 받아 적는 것이 아니라, 중요한 것만 기억하고 불필요한 내용은 지운다.
🔹 LSTM의 핵심 구조
- 입력 게이트 (Input Gate) → 새로운 정보 받아들이기
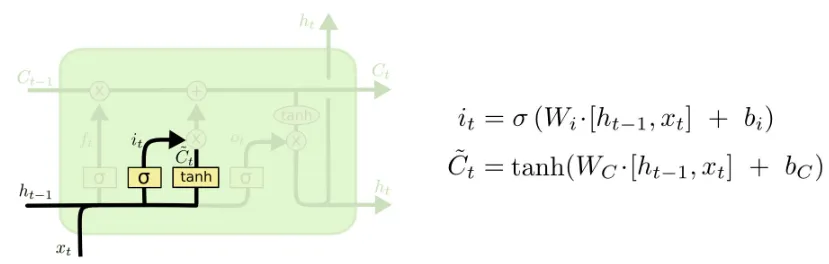
- 새로운 내용을 배울 때 어떤 정보가 중요한지 판단한다. (현재 들어온 새로운 정보를 기억해야 할지 결정)
- 예시: "오늘 배운 개념 중 시험에 나올 확률이 높은 내용을 기억해야겠다."
- 망각 게이트 (Forget Gate) → 불필요한 정보 지우기
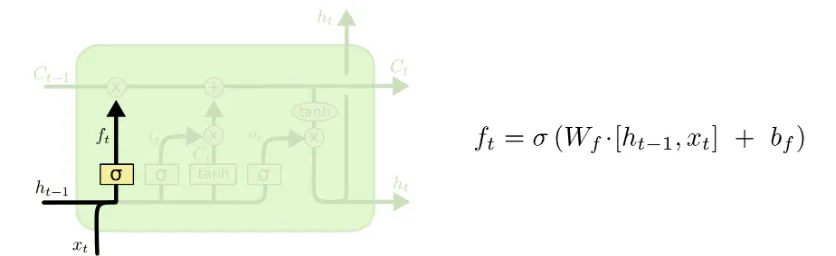
- 기억할 필요 없는 내용을 걸러낸다. (과거의 정보 중에서 현재 필요 없는 정보는 지워버려)
- 예시: "지난 시험에 안 나온 개념들은 굳이 외우지 않아도 되겠다."
- 셀 상태 (Cell State) → 기억 유지하기
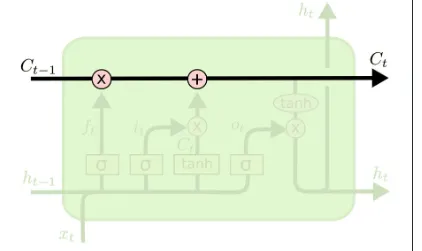
- 장기 기억을 저장하는 역할을 한다.
- 예시: "중요한 공식과 개념들은 머릿속에 계속 저장해 두자."
- 출력 게이트 (Output Gate) → 다음 단계로 전달할 정보 선택하기
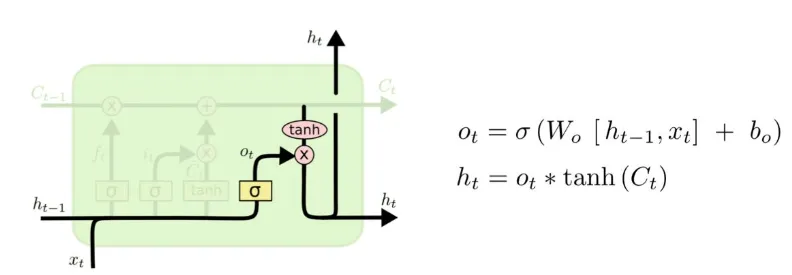
- 시험을 볼 때 필요한 정보만 꺼내서 사용한다(현재 상태에서 예측을 할 때, 어떤 정보를 사용할지 결정해)
- 예시: "시험 문제를 읽고 필요한 개념만 떠올려서 답을 작성하자."
✅ 1️⃣ 필요한 라이브러리 불러오기

✅ 2️⃣ 더미 시계열 데이터 생성

배치 크기(Batch Size)란?
👉 한 번에 학습하는 데이터 샘플 개수
- 일반적으로 배치 크기가 크면 학습 속도가 빠르지만 메모리 사용량이 증가
- 너무 크면 학습이 불안정해지고, 너무 작으면 학습이 느림
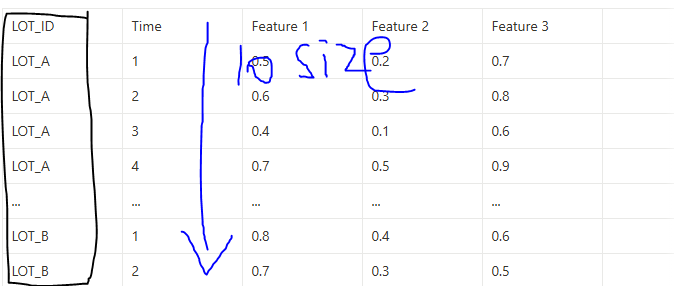
시퀀스 길이(Sequence Length)란?
👉 하나의 입력 데이터가 몇 개의 시간 단계(Time Steps)를 포함하는지
- 시계열 데이터에서는 과거 n개의 데이터를 사용하여 미래를 예측
- 공정 데이터(LOT 단위)에서는 각 LOT마다 연속된 여러 개의 측정값을 하나의 입력으로 사용 가능
📌 예제
- Sequence Length = 10 → 한 번에 과거 10개의 데이터를 보고 예측
- Sequence Length = 30 → 한 번에 과거 30개의 데이터를 보고 예측
1️⃣ 배치 크기 설정
✅ 배치 크기 = 32 → 한 번에 32개의 LOT 데이터를 학습
✅ 배치 크기 = 100 → 한 번에 100개의 LOT 데이터를 학습
2️⃣ 시퀀스 길이 설정
✅ Sequence Length = 10 → 한 LOT에서 연속된 10개의 시간 데이터를 사용하여 예측
✅ Sequence Length = 20 → 한 LOT에서 연속된 20개의 시간 데이터를 사용하여 예측
3️⃣ LOT별로 시퀀스 데이터 생성 (Sliding Window)

4️⃣ PyTorch 텐서 변환

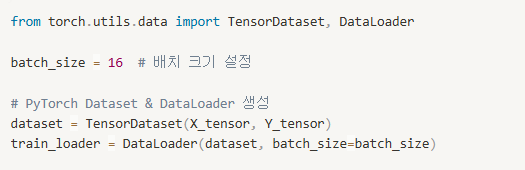
5️⃣ DataLoader를 사용하여 배치 단위로 학습 데이터 생성
3️⃣ LSTM 모델 만들기

4️⃣ 손실 함수 & 옵티마이저 설정
criterion = nn.MSELoss() # 손실 함수 (MSE, 회귀 문제)
optimizer = optim.Adam(list(lstm.parameters()) + list(fc.parameters()), lr=0.01) # Adam 옵티마이저
✅ 손실 함수 (criterion) → 모델이 얼마나 틀렸는지 계산
회귀 문제
- MSELoss (Mean Squared Error, 평균제곱오차) : 예측값과 실제값의 차이를 제곱해서 평균을 내는 손실 함수
- L1Loss (Mean Absolute Error, 평균절대오차) : L1 Loss는 예측값과 실제값의 차이의 절댓값을 평균 내는 손실 함수
분류 문제
CrossEntropyLoss (다중 클래스 분류) : 여러 개의 클래스 중 하나를 예측할 때 사용
✅ 옵티마이저 (optimizer) → 모델이 더 정답에 가까워지도록 학습
Adam (Adaptive Moment Estimation)
- Adam(Adaptive Moment Estimation)은 SGD보다 더 똑똑한 학습 방법
- 가중치를 업데이트할 때, 과거의 기울기(Gradient) 정보도 함께 사용
- 이전의 기울기(Gradient) 값을 참고하여 업데이트
- 즉, 이전 방향을 고려해서 매끄럽게 학습
✅ lstm.parameters() + fc.parameters() → LSTM + FC 레이어의 가중치를 같이 학습!
즉, "손실 함수로 오차를 계산하고, 옵티마이저로 점점 더 정답에 가까워지도록 학습하는 과정!
5️⃣ 학습 루프 (Training Loop)
1. num_epochs = 100 ⇒ early stop 일찍 끝내는거 학습을 했는데 안좋아졌거나 별 개선이안된다? 그러면 멈춰라 50
👉 100번 반복하면서 학습한다는 뜻 (epoch는 전체 데이터셋을 한 번 학습하는 주기)
2. optimizer.zero_grad()
👉 이전 epoch에서 계산된 기울기(gradient)를 지워줘
👉 안 지우면 이전 값이 남아 있어서 이상한 학습이 될 수도 있어
3. 순전파(Forward Propagation)
입력 데이터를 모델에 넣어서 예측값을 계산하는 과정
신경망의 각 층을 거치면서 연산을 순차적으로 수행
4. 역전파 (Backward Propagation)
순전파에서 계산된 예측값과 실제값을 비교하여, 오차를 줄이기 위해 가중치를 업데이트하는 과정
손실 함수(Loss Function)를 기준으로 기울기(Gradient)를 계산 하고, 가중치를 수정함

