.png)
프로세스(Process)
프로세스는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 말한다. 종종 스케줄링의 대상이 되는 작업(task)이라는 용어와 거의 같은 의미로 쓰인다. 여러 개의 프로세서를 사용하는 것을 멀티프로세싱이라고 하며 같은 시간에 여러 개의 프로그램을 띄우는 시분할 방식을 멀티태스킹이라고 한다. 프로세스 관리는 운영 체제의 중요한 부분이 되었다.
프로그램은 일반적으로 하드 디스크 등에 저장되어 있는 실행코드를 뜻하고, 프로세스는 프로그램을 구동하여 프로그램 자체와 프로그램의 상태가 메모리 상에서 실행되는 작업 단위를 지칭한다. 예를 들어, 하나의 프로그램을 여러 번 구동하면 여러 개의 프로세스가 메모리 상에서 실행된다. | 출처: 위키백과
프로세스라는 용어는 위의 설명과 같이 작업이라고 하기도 합니다. 혹은 Task, Job 이라는 용어로도 혼용되어 사용되기도 합니다. 이제 응용 프로그램과 프로세스의 차이를 어느정도 알게 되었습니다.
스케줄링(Scheduling)
실제로 많이 사용하는 개인의 스케줄 관리를 이야기할때 사용하는 스케줄과 동일합니다. 다만 이번 글에서는 컴퓨터가 처리할 일들의 진행순서를 결정하고 관리하는 일입니다.
그래서 프로세스 스케줄링이란 CPU를 사용하려고 하는 많은 프로세스들의 우선 순위를 관리하고 결정하는것이라고 생각할 수 있습니다. CPU의 높은 활용 뿐만 아니라 응답시간, 반환시간, 대기시간등 프로그램을 효율적으로 사용하기 위한 방법이라고 생각할 수 있습니다.
스케줄링 알고리즘
비선점 프로세스 스케줄링
- FCFS 스케줄링(First Come First Served Scheduling)
- SJF 스케줄링(Shortest Job First Scheduling)
- HRRN 스케줄링(Highest Response Ratio Next Scheduling)
선점 프로세스 스케줄링
- RR 스케줄링(Round Robin Scheduling)
- SRTF 스케줄링(Shortest Remaining-Time First Scheduling)
- 다단계 큐 스케줄링(Multilevel Queue Scheduling)
- 다단계 피드백 큐 스케줄링(Multilevel Feedback Queue Scheduling)
- RM 스케줄링(Rate Monotonic Scheduling)
- EDF 스케줄링(Earliest Deadline First Scheduling)
이와 같이 많은 알고리즘이 존재하며 기본적인것을 먼저 살펴봅니다.
여러개의 프로세스 중에 어떤 것을 실행시킬지? 어떤 순서로 실행시킬지? 혹은 어느 시점에 실행할지 그리고 어느 시점에 프로세스를 교체해야하는지?를 결정하기 위해서 스케줄링 알고리즘을 필요로 합니다. 다시 말해 스케줄링 알고리즘에도 목표가 있다는 말입니다.
전 포시팅을 예로들면 시분할 시스템의 목표는 프로세스의 응답 시간을 최대한 짧게 만드는 것입니다. 그리고 멀티 프로그래밍의 목표는 CPU를 최대한 활용해서 프로세스를 빨리 실행시키기 위함이고요. 이처럼 스케줄링 또한 하나의 프로그램이기 때문에 원하는 목표를 기반으로 하나의 스케줄링 알고리즘을 만들어야 합니다.
알고리즘의 기본
*기본을 이해해야하기 때문에 복잡하지 않도록 중간의 다른 작업의 개입 없이 CPU를 계속 사용한다고 가정합니다.
FIFO(First In First Out) 스케줄러
FCFS(First Come First Served)스케줄러라고 부르기도 하는 가장 간단한 스케줄러로 배치 처리 시스템과 매우 유사한 스케줄러입니다.

의미 그대로 첫 번째로 요청이 들어온 요청이 먼저 실행되고 완료되는 방법입니다. 당연히 마지막 요청은 제일 마지막에 실행이 완료되는데 마치 자료구조의 큐와 같습니다. 다시 말해 배치 처리 시스템이 해당 스케줄러를 이용해서 만들었을 것이고 그 내부 구조는 자료구조의 큐를 사용했다 라고 생각할 수 있습니다.
최단 작업 우선(SJF | Shortest Job First) 스케줄러
해당 스케줄러는 의미 그대로 프로세스의 실행시간이 가장 짧은 프로세스부터 먼저 실행 시키는 알고리즘입니다.
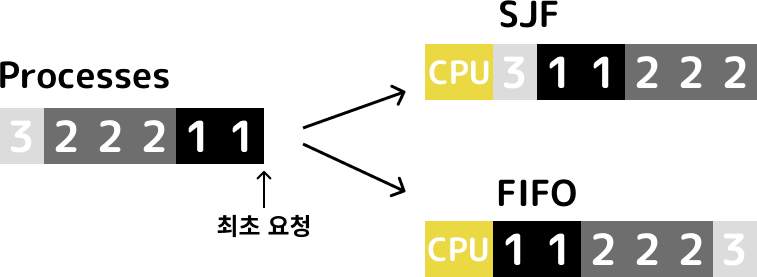
동일한 시간으로 나누어진 프로세스들의 요청이 들어온다고 가정했을때 FIFO 와 SJF의 차이는 위의 그림과 같습니다.
SJF는 프로세서들의 요청이 들어오면 각각의 실행시간을 미리 확인하여 가장 짧은 순서로 실행을 하는 방법이지만 일반적인 운영체제에서 각각의 프로세스들의 실행시간을 예측하기는 어렵습니다. 그렇기 때문에 이상적인 알고리즘을 생각했다고 할 수 있습니다.
FIFO 스케줄링 방법보다 응답 시간을 짧게 할 수 있다는 장점이 있지만 사실상 실행시간을 미리 예측하기가 어렵다는 단점이 있습니다.
사전 지식
- RealTime OS(RTOS): 응용 프로그램 실시간 성능 보장을 목표로 하는 OS
- 특정한 프로그램이 정확하게 언제 시작할지 언제 완료할지 정확한 시간을 보장하는 방법
- 시간에 민감한 프로그램들이 동작해야 하는 프로세스들은 RTOS를 사용한다.
- Hardware RTOS, Software RTOS 등 시간에 민감한 프로세스를 동작해야하는 환경에서 사용
- General Purpose OS(GPOS): 프로세스 실행시간에 많이 민감하지 않고 일반적인 목적으로 사용되는 환경에서 사용한다.
- ex) Windows, Linux 등과 같은 일반적인 운영체제
우선순위(Priority-Based) 기반 스케줄러
- 프로세스에 우선 순위를 미리 정해 놓는다. 즉, 우선 순위가 높은 순서대로 CPU에 실행 시킨다.
- 정적 우선순위를 매길 수 있다. 프로세스마다 우선순위를 미리 지정
- 사용자가 자주 사용하는 혹은 필요로 하는 프로세스를 빨리 실행시킬 수 있게 지정이 가능하지만 모든 프로그램에 지정을 하는것이 오히려 번잡해질 수 있다.
동적 우선순위
- 스케줄러가 상황에 따라 우선순위를 동적으로 변경할 수 있습니다.
.png)
위 그림과 같이 괄호안에 우선순위가 있을 경우 해당 우선순위를 기준으로 요청을 합니다.
우선순위 숫자의 기준은 높은 것일 수도 있고 낮은 것일 수도 있습니다. 해당 우선순위 숫자의 기준은 높은 숫자가 더 높은 우선순위입니다.
라운드 로빈 스케줄러 | Round Robin 스케줄러
라운드 로빈 스케줄러, 줄여서 RR이라고 이야기 하기도 합니다. 해당 스케줄러는 시분할 시스템을 생각한다면 쉽게 이해할 수 있습니다.
시분할 시스템을 위해 설계된 스케줄링 중 하나이며, 프로세스들의 우선순위를 신경쓰지 않습니다. 다만 시분할 시스템처럼 최초 요청부터 순서대로 프로세서들에게 일정한 시간단위로 공평하게 CPU를 할당해줍니다.
순서대로 공평하게 CPU를 할당해주기 때문에 할당해준 시간으로 프로세스가 완료되지 않을 경우 다시 뒤로 배치가 되서 차례를 기다립니다.
이처럼 많은 스케줄링 알고리즘이 있는 이유를 먼저 알아야합니다. 처음에도 이야기했지만 다양한 알고리즘을 목표에 맞게 사용해야 프로그램을 보다 효율적으로 사용할 수 있습니다.
