1.데이터 전처리
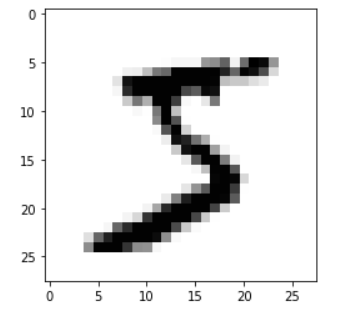
MNIST 데이터셋
0~9까지의 손글씨 이미지
70000개 글자 이미지에 0~9로 라벨링 되어 있음

위의 이미지를 밝기 정도에 따라 0~255로 등급 매김
흰색 배경:0 글씨 들어간 곳-1~255 숫자 중 하나
이미지가 행렬의 집합으로 나타남


28x28=784개의 속성을 이용해 0~9의 클래스 중 하나를 맞힘
2차원 배열->1차원 배열
28x28의 배열을 784개의 1차원 배열로 바꿔줘야 함->reshape() 사용
reshape( 총 샘플 수, 1차원 속성 수)
데이터 정규화
데이터의 폭이 클 때 적절한 값으로 분산 정도 바꿈
0~255사이의 값을 0~1사이 값으로 변환
정규화를 위해 255로 나눠주려면 실수형 변환이 선행돼야 함

원-핫 인코딩
다중 분류 문제에서 필요함
0~9의 클래스값을 가짐->0,1로 이루어진 벡터로 변환
ex) [5]->[0,0,0,0,0,1,0,0,0,0]
np_tils.to.categorical(클래스, 클래스의 개수 ) 함수 사용

2. 딥러닝 기본 프레임 만들기
모델 설계 및 컴파일
 모델 설계
모델 설계
입력층: 노드 512개, 입력값은 784개 속성값, 활성화 함수-렐루함수
출력층: 출력값은 10개의 클래스, 활성화 함수-소프트맥스 함수
모델 컴파일
오차함수: 범주형 교차 엔트로피 함수 (다중 분류문제)
활성화 함수: 아담 함수
accuracy를 매 에포크마다 표시함
모델 저장 / 학습 자동 중단
(4) 모델들을 저장할 폴더 경로 지정
(9) 모델명을 에포크-테스트셋 오차값으로 저장 (확장자는 hdf5)
(10) 테스트셋 오차값을 모니터하여 해당 값이 개선되는 모델만 저장
(12)테스트셋 오차값이 10번이내로 개선되지 않으면 멈춤
모델 실행
샘플 200개를 30번 실행
테스트셋으로 모델의 성능을 측정해 출력함
verbose=0 //진행 사항 출력x
verbose=1 //진행 사항 간략히 출력

그래프 그리기 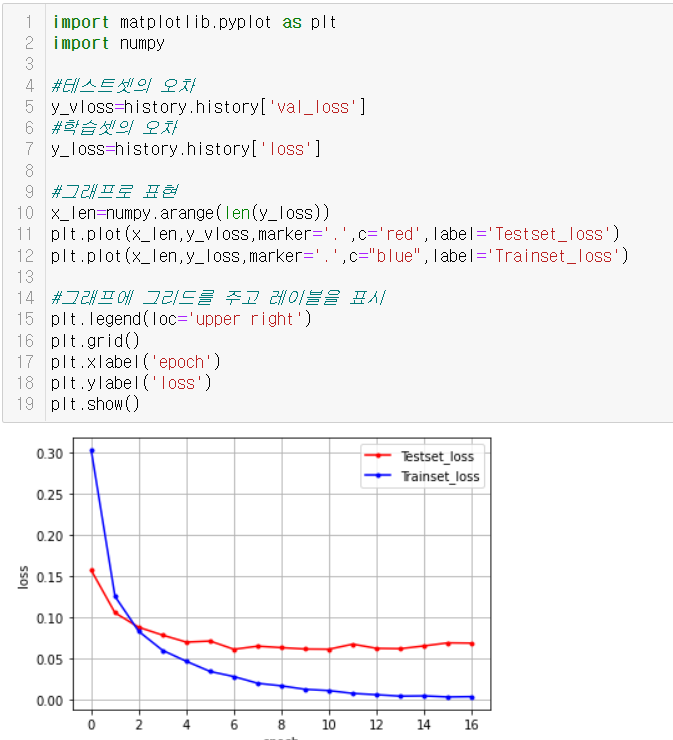
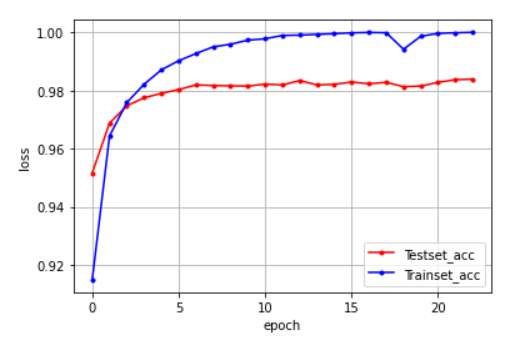
(+)정확도 그래프 추가하는 방법
val_accuracy: 테스트셋 정확도/ accuracy: 훈련셋 정확도