AutoML 정의
- AutoML(Automated Machine Learning)
- 시간 소모적이고 반복적인 기계 학습 모델 개발 작업을 자동화하는 프로세스.
- 머신러닝을 위한 고급 모델 구축을 자동화할 수 있기 때문에 데이터 과학 전문 지식과 프로그래밍 스킬이 필요한 공정을 기계가 알아서 처리해서 누구나 쉽게 머신러닝을 활용할 수 있도록 도와줌.
- 많이 언급되는 라이브러리: AutoML library는 pycaret, H20, TPOT, LightAutoML
- 적용가능 분야: 분류, 회귀, 예측, 컴퓨터 비전, NLP
- 장점
- 광범위한 프로그래밍 지식없이 ML 솔루션 구현
- 시간 및 리소스 절약
- 데이터 과학 모범 사례 적용
- 신속한 문제 해결 제공
코드 적용(pycaret)
- 깃허브 주소: https://github.com/pycaret/pycaret
- 분류 알고리즘 적용
1. pycaret 라이브러리 설치
pip install pycaret
- 주의할 점: python version 3.9, 3.10 and 3.11만 가능
- 따라서 가상환경 만들 때,
conda create --name temp python=3.9로 버전에 맞게 해줘야 함.
2. 데이터 불러오기
df = pd.read_csv("your_path/data.csv")- 학습할 데이터를 불러옴.
3. AutoML 기본 세팅(분류모델)
from pycaret.classification import *
s = setup(data = df.iloc[:,:9], target='ltw', session_id=11)setup(): PyCaret에서 다른 함수를 실행하기 전에 설정 함수를 호출해야 함. 이 함수에는 data와 target이라는 두 가지 필수 파라미터. 다른 모든 파라미터는 선택 사항data: 학습 데이터셋(독립, 종속 포함한 전체 데이터)target: 종속변수session_id: seed 고정,random_state기능과 동일함.
4. AutoML 적용
best = compare_models()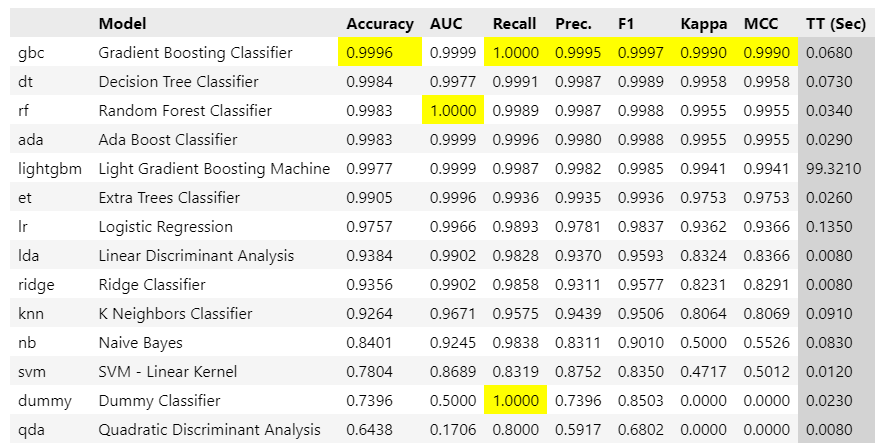
- 실행하는데 약 16분 소요됨
- 모든 것을 포함했을 때 성능이 가장 좋은 것이 best 모델이 됨.
- 여기서는 Gradient Boosting Classifier가 best model임.
- 만약,
Recall성능이 가장 좋은 모델을 고르자하면,sort = 'Recall'을 지정해주면 됨. - 분류알고리즘의 성능에 대해 여기에 정리해두었음.
best- best를 출력하면 적용한 파라미터들이 나옴.

5. 결과 확인
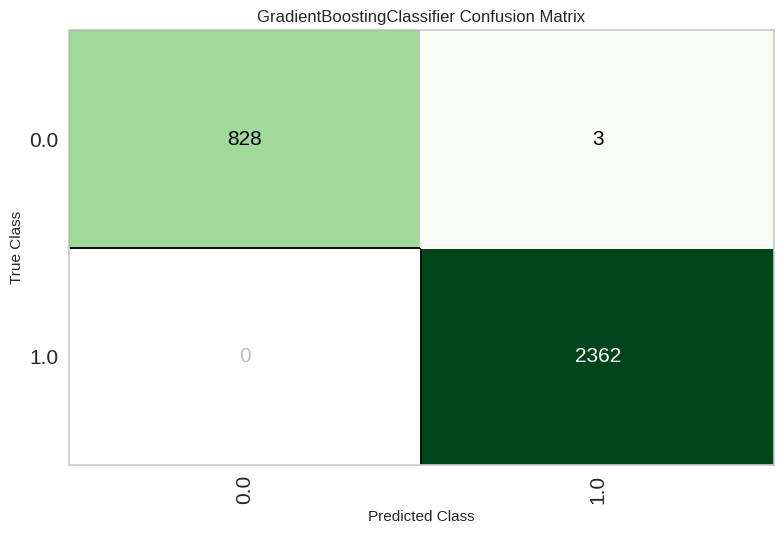
# 분류 결과값 확인
plot_model(best, plot = 'confusion_matrix')- pycaret 라이브러리에 plot_model이 있으며, plot에 보고싶은 결과를 적으면 됨.
# 변수 중요도 확인
plot_model(best, plot = 'feature')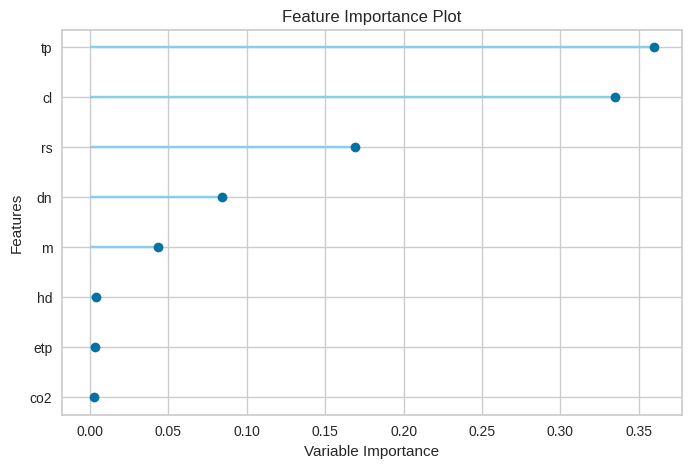
6. 예측 성능 확인
prediction = predict_model(best, data =test_df.iloc[:,:8])
predictionpredict_model(model, test_data)순으로 작성하면 됨.
- test데이터에 예측값 prediction_label(예측값)과 prediction_score(예측 성능)가 추가로 나옴
# 실제 데이터와 비교 (f1_score, accuary_score)
from sklearn.metrics import f1_score, accuracy_score
f1_score(prediction['prediction_label'], test_df.iloc[:,9])
accuracy_score(prediction['prediction_label'], test_df.iloc[:,9])- f1_score: 0.986
- accuracy_score: 0.983
- 테스트 결과도 성능이 좋게 나온 것을 확인할 수 있음.
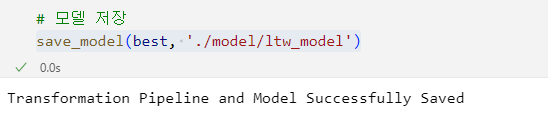
7. 모델 저장 및 불러오기
save_model(best, './model/ltw_model')- save_model(모델, 저장위치/모델이름)
- pkl를 작성하지 않아도 .pkl로 저장됨.
# 저장한 모델 불러오기
load = load_model('./model/ltw_model')
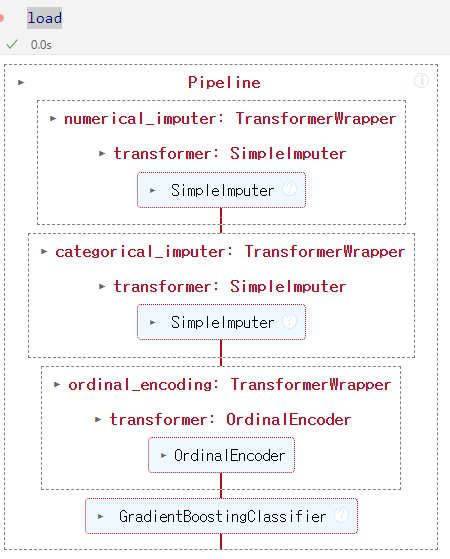
저장한 모델의 파라미터 확인
load['trained_model']
- load로만 불러오면 파이프라인만 출력됨.
- 세세한 것을 보고싶다면
load['trained_model']로 설정해야 함.

데이터분석/데이터사이언스/코딩