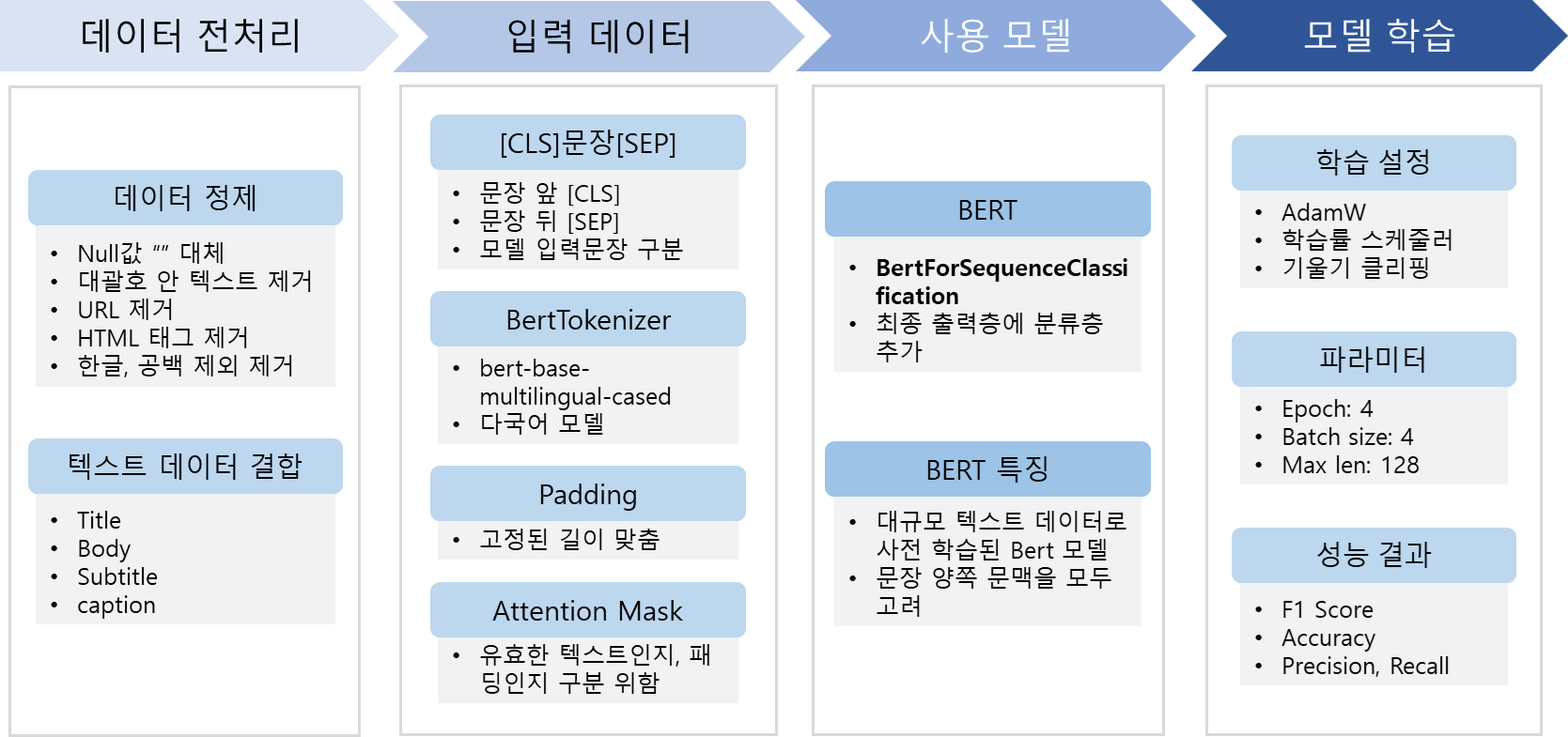
전체 학습 흐름
- 주의할 점: .py에서 진행
argparses는.ipynb에서 실행이 안됨
- 깃허브에서 풀코드 확인 가능
0. 라이브러리 불러오기
import os
import random
import time
import datetime
import torch
import argparse
import re
import pandas as pd
import numpy as np
from transformers import BertTokenizer, BertForSequenceClassification, AdamW, get_linear_schedule_with_warmup, BertConfig
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from keras.preprocessing.sequence import pad_sequences
from sklearn.metrics import classification_report1. 데이터 설명 및 전처리
- Fake News Detection: 가짜뉴스탐지 데이터셋 활용
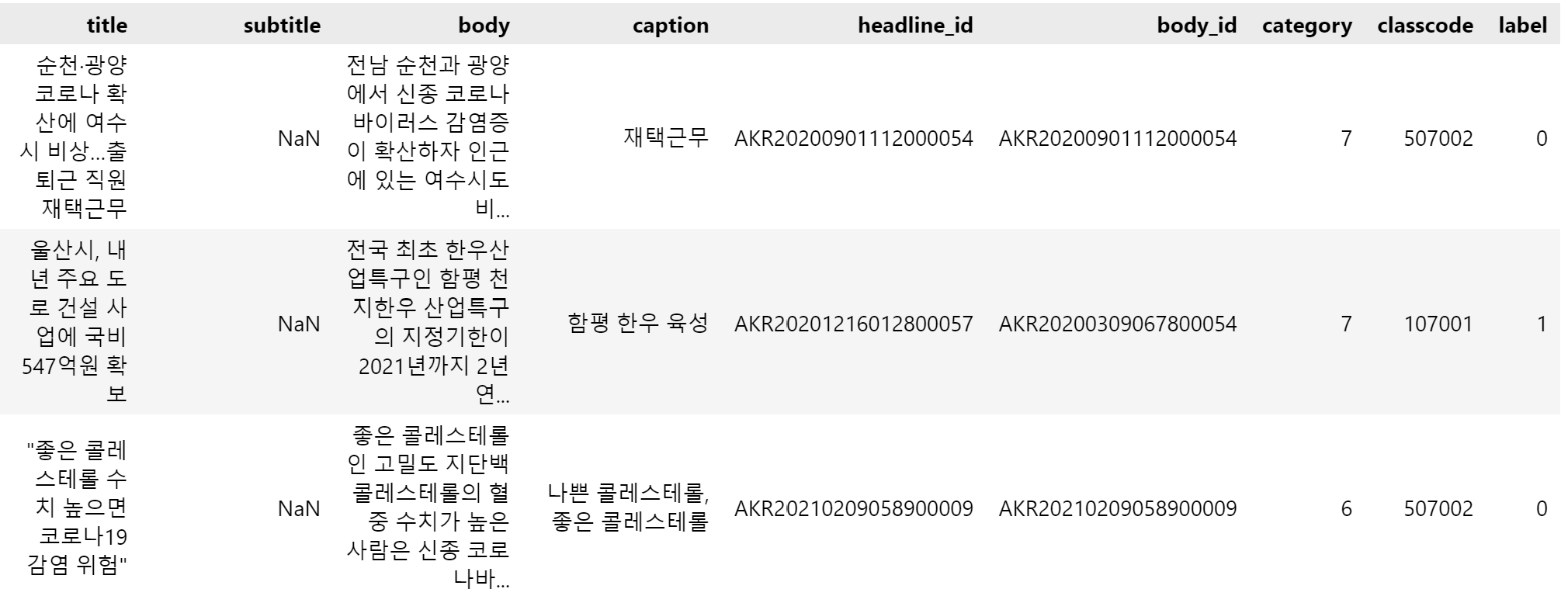
- 데이터셋 구성:
- title, subtitle, body, caption : 본문 내용
- label(0: 진짜 뉴스, 1: 가짜 뉴스) 사용
파이썬 코드
#### 데이터 로드 및 전처리
def load_data(args):
train_df = pd.read_csv(args.train_data)
val_df = pd.read_csv(args.val_data)
train_df.fillna('', inplace=True)
val_df.fillna('', inplace=True)
train_df = train_df
val_df = val_df
# 간단한 정제 함수
def clean_text(text):
text = re.sub(r'\[.*?\]', '', text) # 대괄호 안 텍스트 제거
text = re.sub(r'https?://\S+|www\.\S+', '', text) # URL 제거
text = re.sub(r'<.*?>+', '', text) # HTML 태그 제거
text = re.sub(r'[^가-힣\s]', '', text) # 한글, 공백 제외한 문자 제거
return text
train_df['cleaned_body'] = train_df['body'].apply(clean_text)
train_df['combined_text'] = train_df['title'] + ' ' + train_df['subtitle'] + ' ' + train_df['cleaned_body'] + ' ' + train_df['caption']
train_document = train_df.combined_text.tolist()
train_labels = train_df.label.tolist()
val_df['cleaned_body'] = val_df['body'].apply(clean_text)
val_df['combined_text'] = val_df['title'] + ' ' + val_df['subtitle'] + ' ' + val_df['cleaned_body'] + ' ' + val_df['caption']
val_document = val_df.combined_text.tolist()
val_labels = val_df.label.tolist()
return train_document, train_labels, val_document, val_labels- nan값이 존재해 "" 빈값으로 대체
clean_text 함수: 뉴스 기사 정제하는 함수combined_text: title, subtitle, body, caption 합쳐서 사용
2. 입력 데이터 처리
파이썬 코드
def add_special_token(document):
# 문장 앞 뒤에 추가해줘야 함
added = ["[CLS]" + str(sentence) + "[SEP]" for sentence in document]
return added
def tokenization(document, mode="huggingface"):
# 토큰화 진행
if mode == "huggingface":
tokenizer = BertTokenizer.from_pretrained(
'bert-base-multilingual-cased',
do_lower_case=False,
)
tokenized = [tokenizer.tokenize(sentence) for sentence in document]
ids = [tokenizer.convert_tokens_to_ids(sentence) for sentence in tokenized]
return ids
def padding(ids, args):
# 패딩(빈 공간을 채우는 작업)
ids = pad_sequences(ids, maxlen=args.max_len, dtype="long", truncating='post', padding='post')
return ids
def attention_mask(ids):
# 입력으로 받은 토큰들이 실제로 중요한 정보인지, 아니면 패딩된 토큰인지를 구분하기 위한 어텐션 마스크를 생성
masks = []
for id in ids:
mask = [float(i>0) for i in id]
masks.append(mask)
return masks-
add_special_token(document):문장 앞에[CLS], 뒤에[SEP]토큰을 추가해주는 함수.
→ BERT 모델은 문장 시작과 끝을 인식하기 위해 이 특수 토큰을 필요로 함. -
tokenization(document, mode="huggingface"): 문장을 토큰화하는 함수.
→huggingface모드를 사용해bert-base-multilingual-cased토크나이저로 문장을 토큰화하고, 토큰을 ID로 변환함.- 다국어 지원:
bert-base-multilingual-cased
- 다국어 지원:
-
padding(ids, args): 토큰 ID 시퀀스를 고정된 길이(args.max_len)로 패딩하는 함수.
→ 문장의 길이를 맞춰 모델이 일관된 입력을 받을 수 있게 함. -
attention_mask(ids): 어텐션 마스크를 생성하는 함수.
→ 실제 토큰은 1, 패딩 토큰은 0으로 표시해 모델이 패딩을 무시하도록 함.
### 토큰화 진행
def train_val_data_process(args):
train_document, train_labels, val_document, val_labels = load_data(args)
train_document = add_special_token(train_document)
train_ids = tokenization(train_document)
train_ids = padding(train_ids, args)
train_masks = attention_mask(train_ids)
del train_document
val_document = add_special_token(val_document)
val_ids = tokenization(val_document)
val_ids = padding(val_ids, args)
val_masks = attention_mask(val_ids)
del val_document
return train_ids, train_masks, train_labels, val_ids, val_masks, val_labels
def build_dataloader(ids, masks, label, args):
dataloader = TensorDataset(torch.tensor(ids), torch.tensor(masks), torch.tensor(label))
dataloader = DataLoader(dataloader, sampler=RandomSampler(dataloader), batch_size=args.batch_size)
return dataloader-
train_val_data_process(args): 전체 데이터 전처리 과정을 수행하는 함수.
→load_data(args)로 데이터를 불러오고, 학습/검증 데이터를 토큰화, 패딩, 마스크 처리 후 반환함. -
build_dataloader(ids, masks, label, args): 입력 데이터, 어텐션 마스크, 레이블을 묶어서 DataLoader를 생성하는 함수.
→TensorDataset으로 데이터를 묶고,RandomSampler로 데이터를 섞어batch_size만큼 나눠줌.
3. 사용모델
def build_model(args):
model = BertForSequenceClassification.from_pretrained("bert-base-multilingual-cased", num_labels=args.num_labels)
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"{torch.cuda.get_device_name(0)} available")
model = model.cuda()
else:
device = torch.device("cpu")
print("no GPU available")
model = model
return model, devicebuild_model(args)
사전 학습된 BERT 모델을 불러와 분류 작업에 맞게 설정하는 함수.
→num_labels에 따라 분류할 클래스 수를 지정하고, GPU가 있으면 모델을 GPU로 옮김. 없으면 CPU 사용.
4. 훈련
def train(train_dataloader, test_dataloader, args):
model, device = build_model(args)
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=len(train_dataloader)*args.epochs)
random.seed(args.seed_val)
np.random.seed(args.seed_val)
torch.manual_seed(args.seed_val)
torch.cuda.manual_seed_all(args.seed_val)
model.zero_grad()
for epoch in range(0, args.epochs):
model.train()
total_loss, total_accuracy = 0, 0
print("-"*30)
for step, batch in enumerate(train_dataloader):
if step % 500 == 0 :
print(f"Epoch : {epoch+1} in {args.epochs} / Step : {step}", time.strftime('%Y.%m.%d - %H:%M:%S'))
batch = tuple(index.to(device) for index in batch)
ids, masks, labels, = batch
outputs = model(ids, token_type_ids=None, attention_mask=masks, labels=labels)
loss = outputs.loss
total_loss += loss.item()
pred = [torch.argmax(logit).cpu().detach().item() for logit in outputs.logits]
true = [label for label in labels.cpu().numpy()]
accuracy = accuracy_score(true, pred)
total_accuracy += accuracy
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
model.zero_grad()
avg_loss = total_loss / len(train_dataloader)
avg_accuracy = total_accuracy/len(train_dataloader)
print(f" {epoch+1} Epoch Average train loss : {avg_loss}", time.strftime('%Y.%m.%d - %H:%M:%S'))
print(f" {epoch+1} Epoch Average train accuracy : {avg_accuracy}", time.strftime('%Y.%m.%d - %H:%M:%S'))
acc = test(test_dataloader, model, device)
os.makedirs("results", exist_ok=True)
f = os.path.join("results", f'epoch_{epoch+1}_evalAcc_{acc*100:.0f}.pth')
torch.save(model.state_dict(), f)
print('Saved checkpoint:', f)
# 모델 저장
output_dir = './bert_saved_model' # 모델을 저장할 경로 지정
model.cpu() # 모델을 저장하기 전에 CPU로 이동
model.save_pretrained(output_dir)-
train(train_dataloader, test_dataloader, args): BERT 모델을 학습하는 함수.
→ 모델과 디바이스를 초기화하고, 옵티마이저(AdamW)와 학습률 스케줄러를 설정함. 랜덤 시드를 고정해 재현성을 보장. -
학습 루프 :
args.epochs만큼 학습을 반복하며 각 에폭(epoch)마다 손실(loss)과 정확도(accuracy)를 계산.
→ 500 스텝(step)마다 진행 상황 출력, 손실 값으로 역전파(backpropagation) 후 그래디언트 클리핑(1.0) 적용. -
정확도 평가 및 체크포인트 저장 :
각 에폭이 끝날 때마다test()함수를 통해 검증 데이터셋 성능을 평가하고, 모델 체크포인트를results폴더에 저장. -
최종 모델 저장 :
모든 에폭이 끝난 후 모델을 CPU로 옮기고./bert_saved_model경로에 최종 모델 저장.
5. 테스트 결과
### 테스트 결과
def test(test_dataloader, model, device):
model.eval()
total_accuracy = 0
all_preds = []
all_labels = []
for batch in test_dataloader:
batch = tuple(index.to(device) for index in batch)
ids, masks, labels = batch
with torch.no_grad():
outputs = model(ids, token_type_ids=None, attention_mask=masks)
# 예측값 추출
preds = torch.argmax(outputs.logits, dim=1).cpu().detach().numpy()
true_labels = labels.cpu().numpy()
# 정확도 계산을 위해 리스트에 저장
all_preds.extend(preds)
all_labels.extend(true_labels)
# 배치별 정확도 계산
accuracy = accuracy_score(true_labels, preds)
total_accuracy += accuracy
avg_accuracy = total_accuracy/len(test_dataloader)
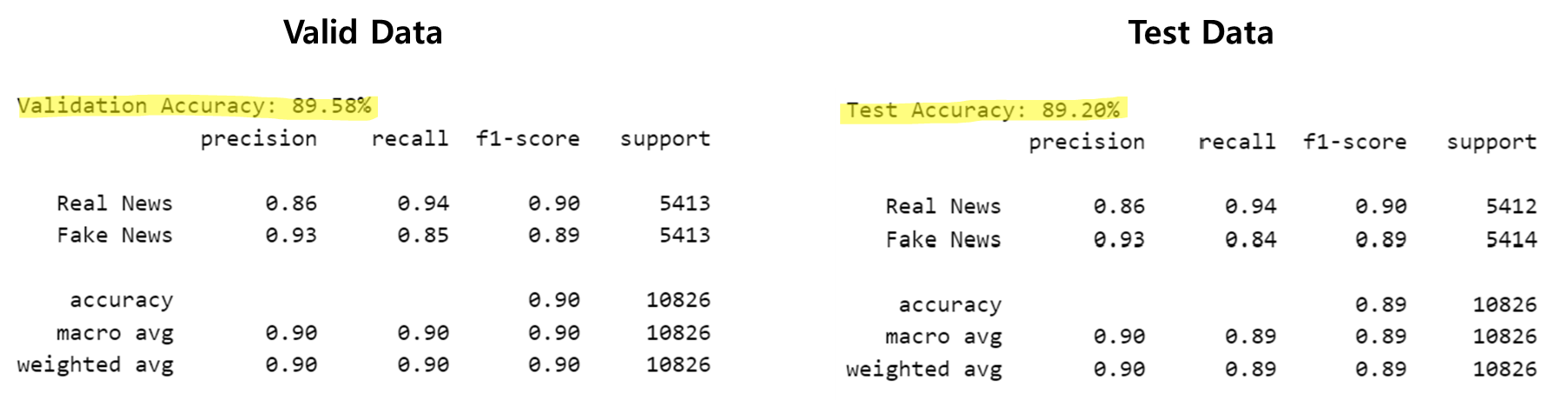
report = classification_report(all_labels, all_preds, target_names=['Real News', 'Fake News'])
print(f"Validation Accuracy: {accuracy * 100:.2f}%")
print(report)
print(time.strftime('%Y.%m.%d - %H:%M:%S'))
filename='evaluation_results.txt'
# 결과를 텍스트 파일로 저장
with open(filename, 'w') as f:
f.write(f'Validation Accuracy: {accuracy * 100:.2f}%\n\n')
f.write(report)
return avg_accuracy-
test(test_dataloader, model, device): 모델을 평가하는 함수
→ 모델을 평가 모드(model.eval())로 설정하고, 테스트 데이터에 대해 예측을 수행함. -
예측 과정 :
배치 단위로 입력 데이터를device로 이동시킨 후,with torch.no_grad()를 사용해 그래디언트 계산 없이 예측 수행.
→torch.argmax(outputs.logits, dim=1)을 사용해 가장 확률이 높은 클래스를 예측. -
정확도 및 리포트 생성 :
accuracy_score를 사용해 배치별 정확도를 계산하고,classification_report를 통해 분류 성능을 자세히 출력.
→ 레이블이['Real News', 'Fake News']로 설정됨. -
결과 저장 :
평가 결과를 출력 후,0925_evaluation_results.txt파일에 정확도 및 분류 리포트를 저장.
→ 최종적으로 평균 정확도(avg_accuracy)를 반환.
6. 실행
def run(args):
train_ids, train_masks, train_labels, test_ids, test_masks, test_labels = train_val_data_process(args)
print('data loader start', time.strftime('%Y.%m.%d - %H:%M:%S'))
train_dataloader = build_dataloader(train_ids, train_masks, train_labels, args)
test_dataloader = build_dataloader(test_ids, test_masks, test_labels, args)
print('data loader end', time.strftime('%Y.%m.%d - %H:%M:%S'))
train(train_dataloader, test_dataloader, args)run(args): 전체 학습 파이프라인을 실행하는 메인 함수.
→train_val_data_process(args)로 데이터를 전처리하고,build_dataloader()로 학습/검증용 DataLoader를 생성한 후train()함수를 호출해 모델 학습 시작.
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-train_data", default="/mnt/d/LLM/data/[Data 3] Kor - Fake News Detection/train.csv")
parser.add_argument("-val_data", default="/mnt/d/LLM/data/[Data 3] Kor - Fake News Detection/valid.csv")
parser.add_argument("-max_len", default=128, type=int)
parser.add_argument("-batch_size", default=32, type=int)
parser.add_argument("-num_labels", default=2, type=int)
parser.add_argument("-epochs", default=4, type=int)
parser.add_argument("-seed_val", default=42, type=int)
args = parser.parse_args()
run(args)-
if __name__ == "__main__":: 스크립트를 직접 실행할 때만 아래 코드를 실행하도록 설정.
→argparse.ArgumentParser()를 사용해 명령줄 인자(argument)를 받아 설정값을 정의. -
명령줄 인자 설명
-train_data: 학습 데이터 경로.-val_data: 검증 데이터 경로.-max_len: 입력 시퀀스의 최대 길이(128).-batch_size: 배치 크기(32).-num_labels: 분류할 클래스 수(2, 즉 이진 분류).-epochs: 학습 반복 횟수(4회).-seed_val: 랜덤 시드 값(42).
-
args = parser.parse_args():
명령줄에서 입력받은 인자들을args에 저장하고run(args)로 전체 프로세스를 실행.
7. 결과 확인