Consumer
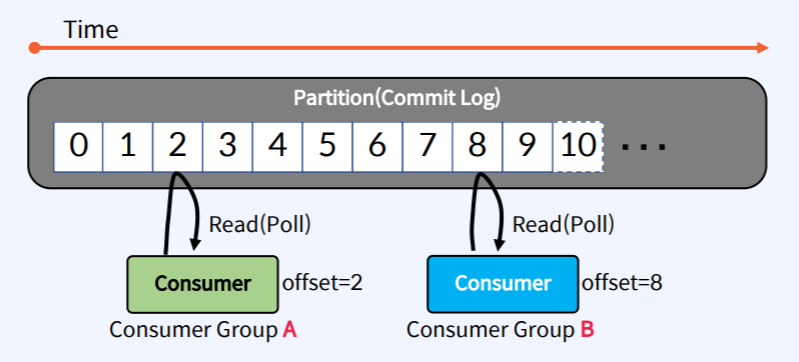
- Consumer는 Apache Kafka의 Commit Log 즉 Partition에서 Record를 Read해서 그것을 활용하는 Application 이다.
- Consumer는 각각 고유의 속도로 Commit Log로 부터 Read(Poll)를 수행한다.
- 서로 다른 Consumer Group에 속한 Consumer들은 서로 관련이 없으며 Commit Log에 있는 Record를 동시에 다른 위치에서 Read할 수 있다.
Consumer Offset
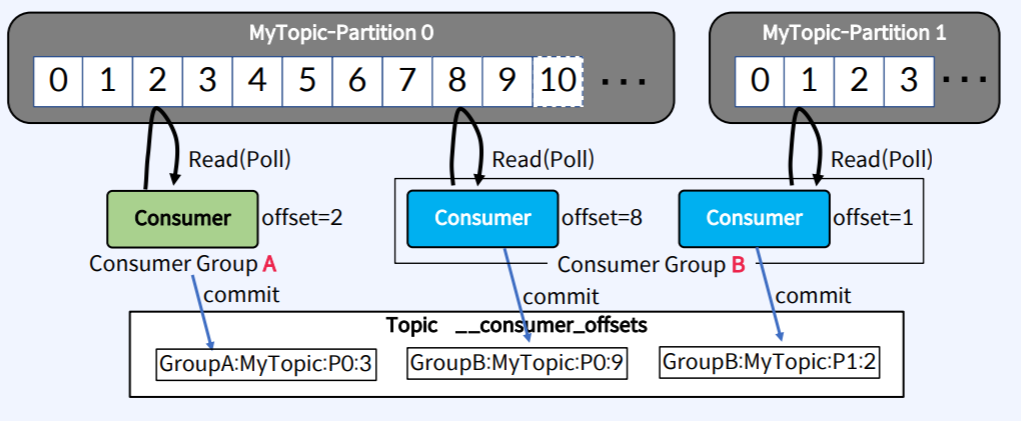
- Consumer Offset은 Consumer Group이 읽은 위치(그 다음 읽어야할 위치)를 표시한다.
- __consumer_offsets라는 Internal Topic에서 Consumer Offset을 저장하여 관리한다.
- Offset을 사용하는 이유는 Consumer가 자동이나 수동으로 읽은 위치를 Commit하면 다시 읽어가는 것을 방지하기 위해서다.
- 위의 그림을 보면 Consumer Group A는 MyTopic-Partition0에 있는 데이터 중에서 Offset이 2인 데이터를 Read(Poll) 하였다.
- Consumer Group A는 다음 읽어야 할 위치인 Offset 3을 Internal Topic인 __consumer_offsets에 저장한다.
(그룹명:토픽이름:파티션번호:Offset번호) --> GroupA:MyTopic:P0:3- 즉 Consumer가 다음 읽어야할 위치의 데이터를 가지고 있는 것이 아니라 Kafka의 내부에 있는 Topic에다가 데이터를 저장한다.
- 위의 그림에서 Consumer Group B에는 2개의 Consumer가 있고 각각의 Consumer는 MyTopic의 Partitition 0과1에서 Read(Poll)하는데
- Partition 0에서 가져오는 Consumer는 Offset 8을 Read(Poll) 해왔고 Partition 1에서 가져오는 Consumer는 Offset 1을 Read(Poll) 해왔다.
- 따라서 __consumer_offsets에 저장되는 데이터는 GroupB:MyTopic:P0:9 와 GroupB:MyTopic:P1:2가 된다.
Multi-Partitions With Single Consumer
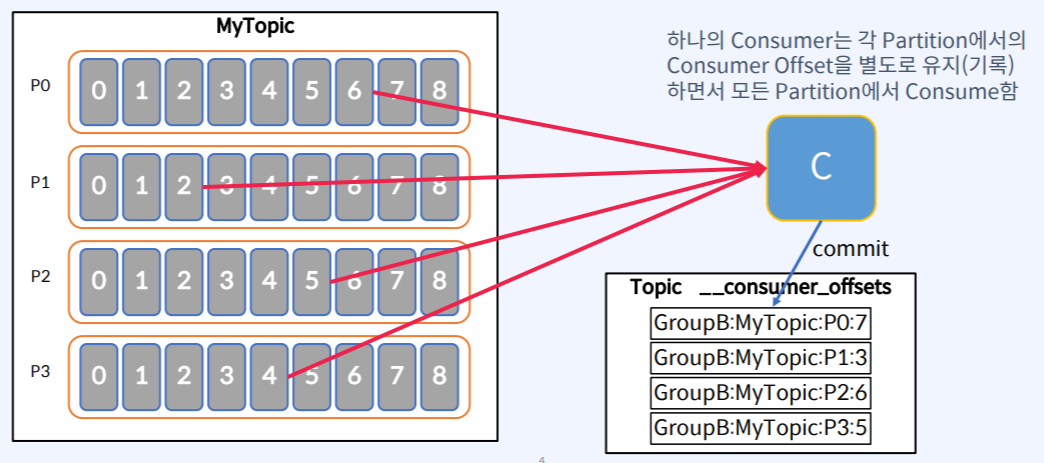
가정 : Topic의 Partition은 4개이고 Consumer는 1개일 때
- Consumer가 Topic의 Partition에 있는 모든 Record를 Consume한다.
- 이 때 Consumer는 각 Partition에서의 Consumer Offset을 별도로 유지(기록)하면서 모든 Partition에서 Consume한다.
Consuming as a Group
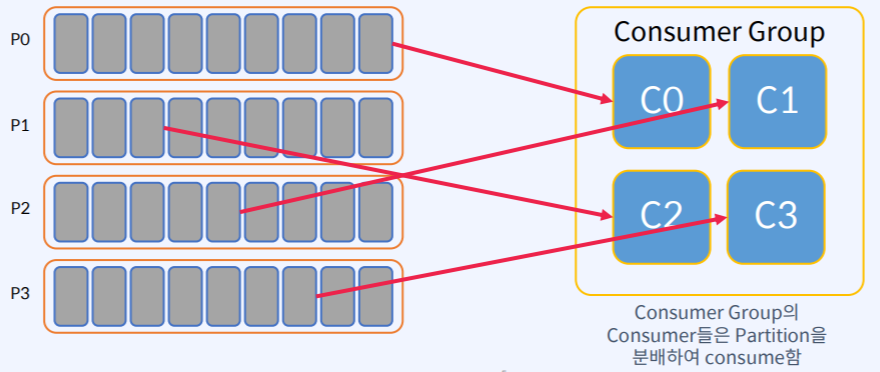
- Consumer들은 Consumer Group을 만들 수 있는데 동일한 group.id로 구성된 모든 Consumer들은 하나의 Consumer Group을 형성한다.
가정 :하나의 Topic에 Partition이 4개 있고 Consumer Group에도 Consumer가 4개 일 때
- 자동으로 Balancing해서 Partition을 나눠서 Consume 한다.
- 전제 조건 : Partition은 항상 Consumer Group 내의 하나의 Consumer에 의해서만 사용되어야 한다. Consumer는 주어진 Topic에서 0개 이상의 많은 Partition을 사용할 수 있다.
Multi Consumer Group
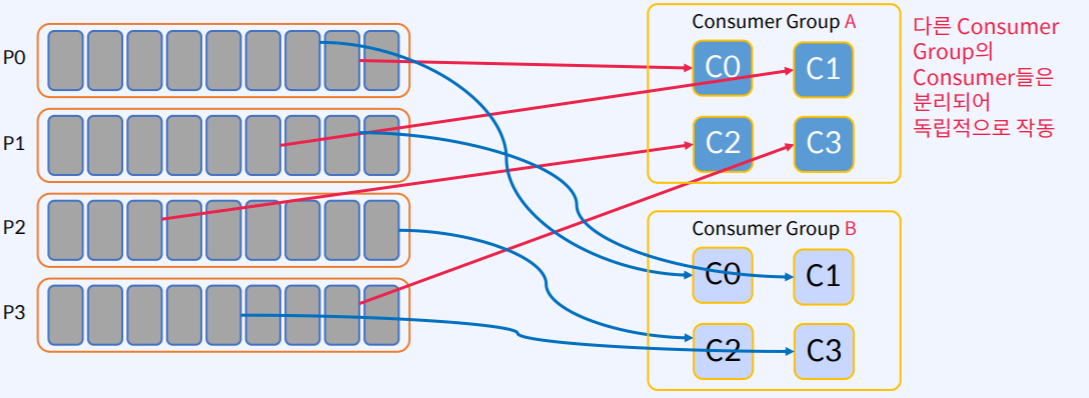
- Consumer Group의 Consumer들은 작업량을 어느정도 균등하게 분할한다.
- 동일한 Topic에서 Consumer하는 여러 Consumer Group이 있을 수 있다.
- 서로 다른 Consumer Group의 Consumer들은 분리되어 독립적으로 작동한다.
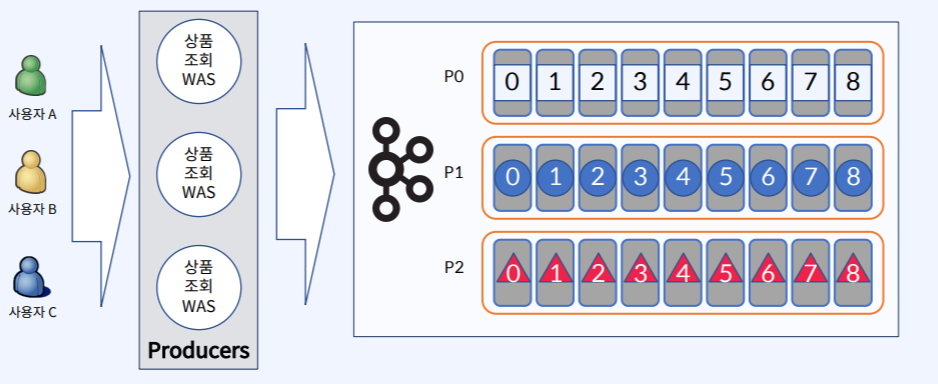
Key를 사용하면 Partition 별로 동일한 Key를 가지는 메시지 저장
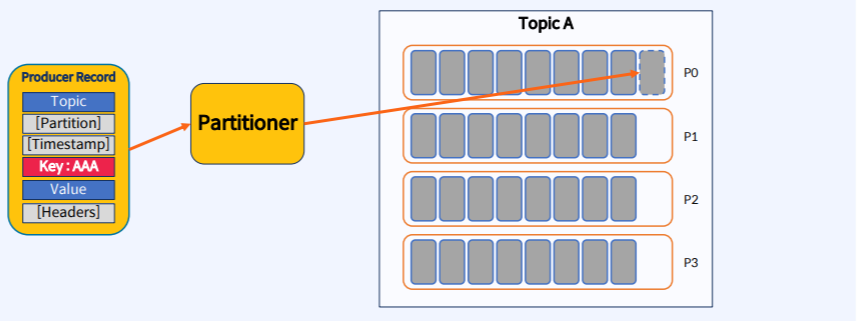
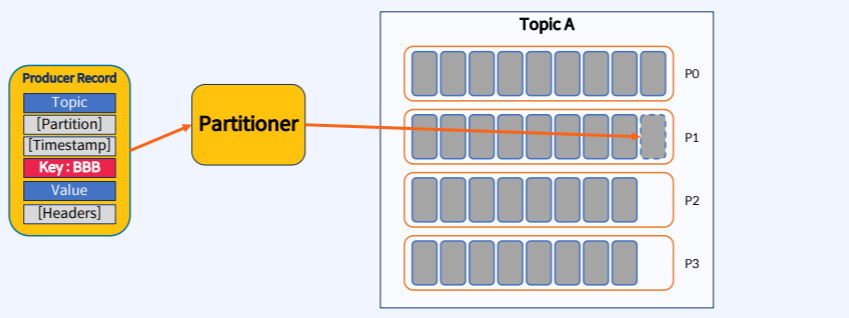
위의 사진처럼 Record를 만들 때 Key값이 AAA이면 항상 특정 Partiton(P0)에 들어가게 된다.
마찬가지로 Key값이 BBB면 항상 P1에 들어가게 된다.
Message Ordering(순서)
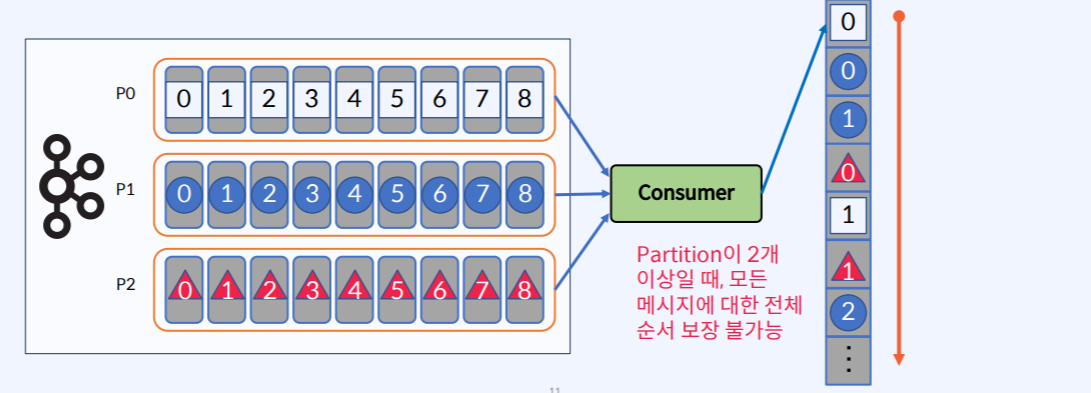
- Key를 사용해서 Record를 보내게 되면 위의 그림처럼 P0, P1, P2에 동일한 Key를 가진 Record들이 들어온다.
- 하지만 하나의 Topic에 Partition이 2개 이상인 경우 Topic 내의 모든 Record에 대한 전체 순서는 보장이 불가능하다. (섞여 버리기 때문에)
- Partition을 1개로 구성하면 Topic 내의 모든 Record에 대한 순서가 보장 가능하지만 처리량이 저하가 된다는 큰 단점이 있다.
Partition을 1개로 구성해서 순서를 보장해야 할 때?
대부분의 경우 Key로 구분할 수 있는 메시지들의 순서 보장이 필요한 경우가 많다.
Message Ordering With Key
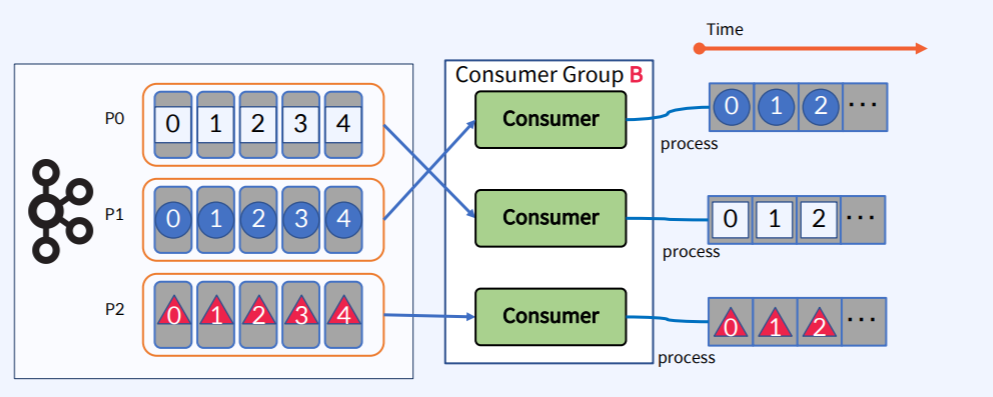
- 동일한 Key를 가진 메세지는 동일한 Partition에만 전달되어 Key 레벨의 순서가 보장 가능하다.
- 따라서 멀티 Partition이 사용가능하기 때문에 처리량 또한 증가하게 된다.
- 하지만 운영중에 Partition 개수를 변경하게 되면 Hash 알고리즘의 값이 달라지기 때문에 Key 값또한 달라진다. 그러므로 순서 보장이 불가능하게 된다.
Cardinality
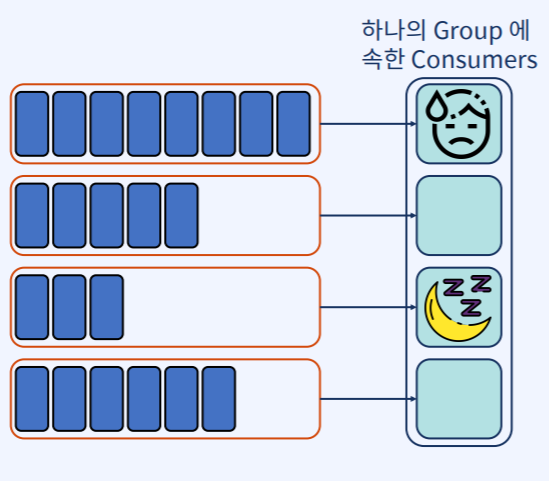
- 특정 데이터 집합에서 유니크한 값의 개수
- Key Cardinality는 Consumer Group의 개별 Consumer가 수행하는 작업의 양에 영향을 끼친다.
- 따라서 Key 선택이 잘못되면 작업 부하가 고르지 않을 수 있다.
- Key는 Integer, String 등과 같은 단순한 유형일 필요가 없다.
- Key는 Value와 마찬가지로 Avro, JSON 등 여러 필드가 있는 복잡한 객체일 수도 있다.
- 따라서 Partition 전체에 Record를 고르게 배포하는 Key를 만드는 것이 중요하다.
Consumer Failure
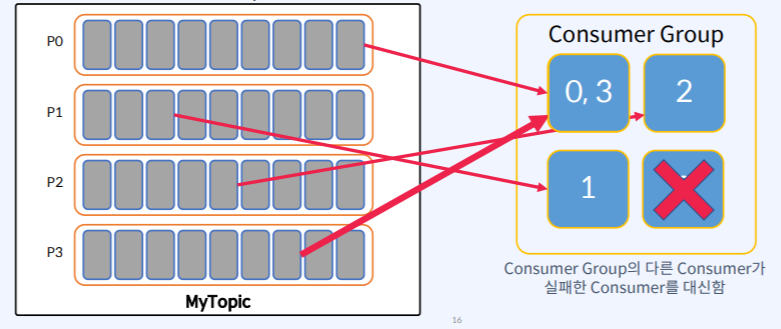
- Consumer에서 장애가 발생하면 Consumer를 Rebalancing해서 장애가 일어났던 Consumer의 Partition을 멀쩡한 다른 Consumer가 Consuming 할 수 있도록 한다.
- Partition은 항상 Consumer Group 내의 하나의 Consumer에 의해서만 사용된다.
- Consumer Group 내의 다른 Consumer가 실패한 Consumer를 대신하여 Partition에서 데이터를 가져와서 처리한다.
요약
- Consumer가 자동이나 수동으로 데이터를 읽은 위치를 Commit하여 다시 읽음을 방지한다.
- __consumer_offsets 라는 Internal Topic에서 Consumer Offset을 저장하여 관리한다.
- 동일한 group.id로 구성된 모든 Consumer들은 하나의 Consumer Group을 형성한다.
- 서로 다른 Consumer Group의 Consumer들은 분리되어 독립적으로 작동한다.
- 동일한 Key를 가지는 메시지는 동일한 Partition에만 전달되어 Key 레벨의 순서를 보장할 수 있다.
- Key 선택이 잘못되면 작업 부하가 고르지 않을 수 있다.
- Consumer Group 내의 다른 Consumer가 실패한 Consumer를 대신하여 Partition에서 데이터를 가져와서 처리한다.

현시깁니다