Apache Kafka
1.Apache Kafka
Data in Motion Platform : 움직이는 데이터를 처리하는 플랫폼Event Streaming Plaform : 실시간으로 흐르는 Event Stream을 받아주고 그 데이터를 필요로하는 곳으로 전송해주는 플랫폼 비즈니스에서 일어나는 모든 일(데이터)을 의
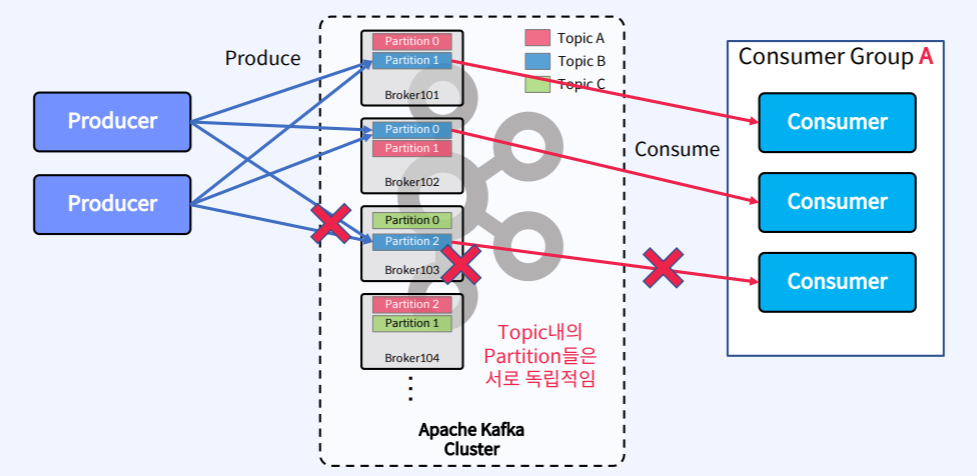
2.Apache Kafka - Topic, Partition, Segment
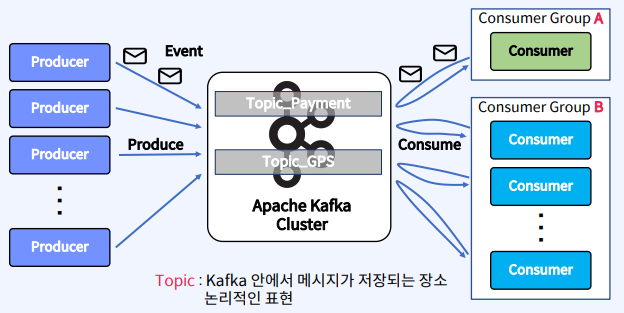
위의 그림을 보면 가운데는 Apache Kafka Cluster가 있고 그 안에 Topic이라는 것을 만든다. Topic은 Kafka내에서 전송되는 메시지가 저장되는 장소이다. Topic은 논리적인 표현으로 시스템 상에(파일, 디렉토리) 눈에 보이지 않는다. 그림 왼쪽
3.Apache Kafka - Broker, Zookeeper

Broker, Zookeeper > - Apache Kafka는 ZooKeeper라고 하는 컴포넌트들과 Cluster로 구성되어 있고 Kafka Cluster 내에는 여러개의 Broker들로 구성되어 있다. Broker > - Kafka Broker : Topic
4.Apache Kafka - Producer
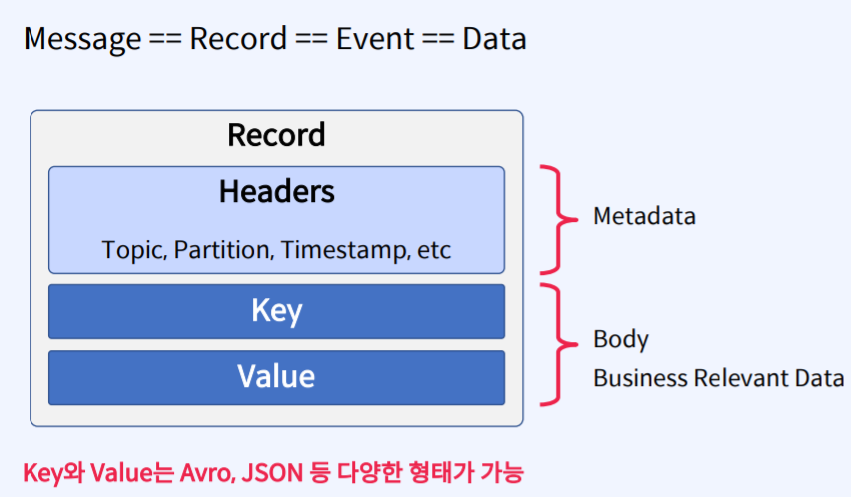
Producer : 메시지를 생산(Produce)해서 kafka의 Topic으로 메시지를 보내는 애플리케이션Consumer : Topic의 메시지를 가져와서 소비(Consume)하는 애플리케이션Consumer Group : Topic의 메시지를 사용하기 위해 협력하는
5.Apache Kafka - Consumer
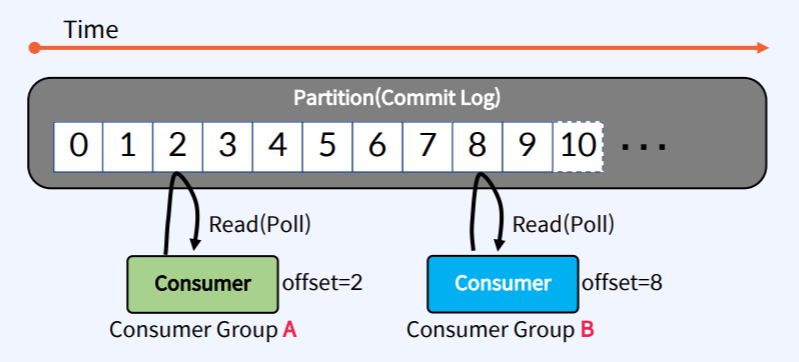
Consumer는 Apache Kafka의 Commit Log 즉 Partition에서 Record를 Read해서 그것을 활용하는 Application 이다. Consumer는 각각 고유싀 속도로 Commit Log로 부터 Read(Poll)를 수행한다. 서로 다른 C
6.Apache Kafka - Replication
장애가 발생한 Broker의 Partition들은 모두 사용할 수 없게 되는 문제가 발생한다. 물론 서비스는 정상적으로 동작하겠지만 기존 메시지는 버릴 것인가? 하는 문제가 발생한다. 왜냐하면 이미 받아놓은 기존의 데이터들은 장애가 발생한 Partition에 남아 있기
7.Apache Kafka - In-Sync-Replicas
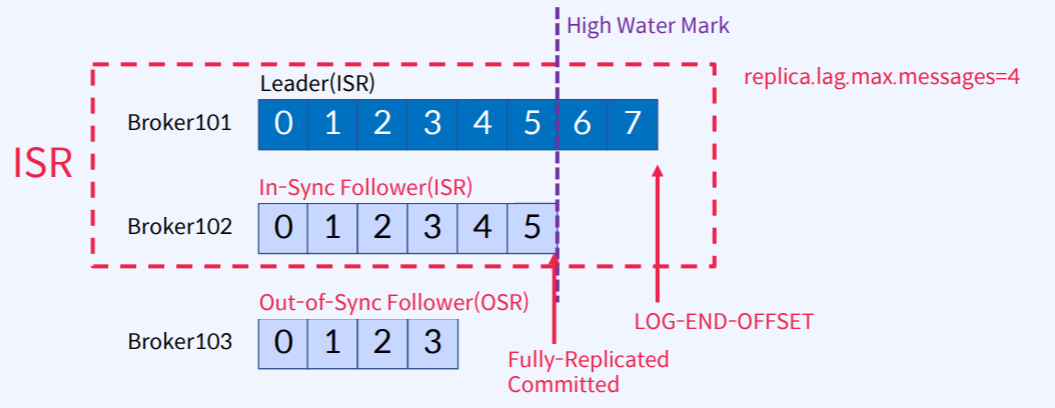
In-Sync-Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas (Leader와 Follower 모두)의 목록가정 : replica.lag.max.messages=4 라고 할 때 Leader의 LOG-END-OFFSET은
8.Apache Kafka - Producer Acks, Batch, Page Cache, Flush
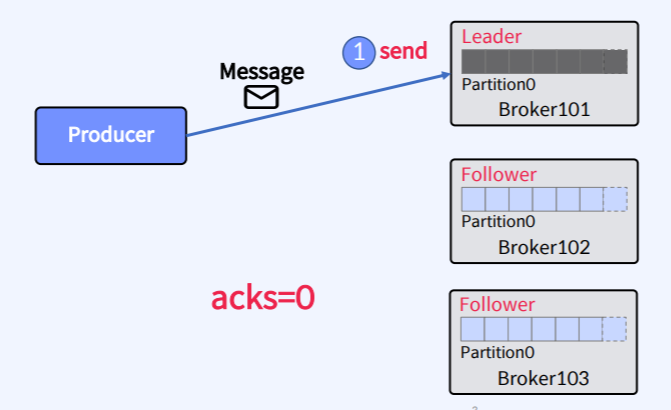
acks 설정은 요청이 성공할 때의 정의하는데 사용되는 Producer에 설정하는 Parameter다.acks=0 : ack가 필요하지 않음. 이 수준은 자주 사용되지 않는다. 메시지 손실이 다소 있더라도 빠르게 메시지를 보내야 하는 경우에 사용된다. acks=1(d
9.Apache Kafka - Replica Failure
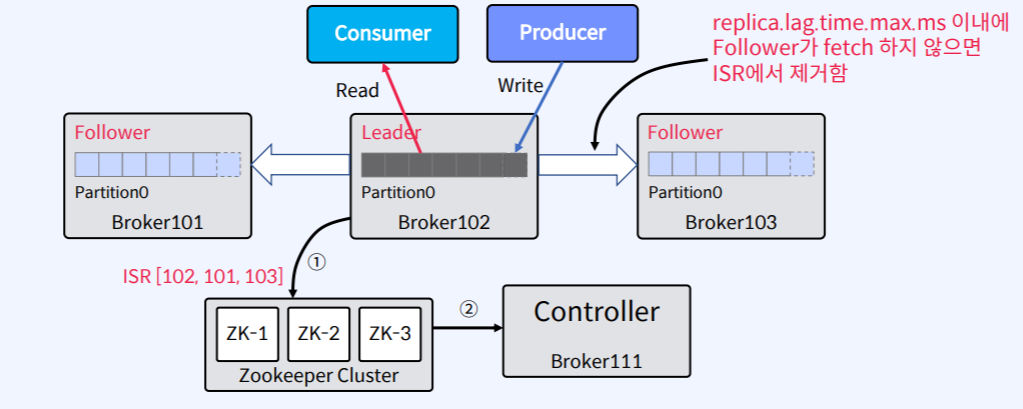
메시지가 ISR 리스트의 모든 Replica(복제본)에서 수신되면 Commit된 것으로 간주한다.Kafka Cluster의 Controller가 모니터링하는 Zookeeper의 ISR 리스트에 대한 변경 사항은 Leader가 유지한다. n개의 Replica가 있는 경우
10.Apache Kafka - Replica Recovery

위의 그림은 Partition이 하나 있고 Replica가 3개로 구성되어있고Leader X, Follower Y, Follower Z는 모두 ISR리스트에 들어가 있고Producer는 메시지(M1,M2,M3,M4)를 보낼 때 acks=all, retires=MAX_I
11.Apache Kafka - Consumer Rebalance
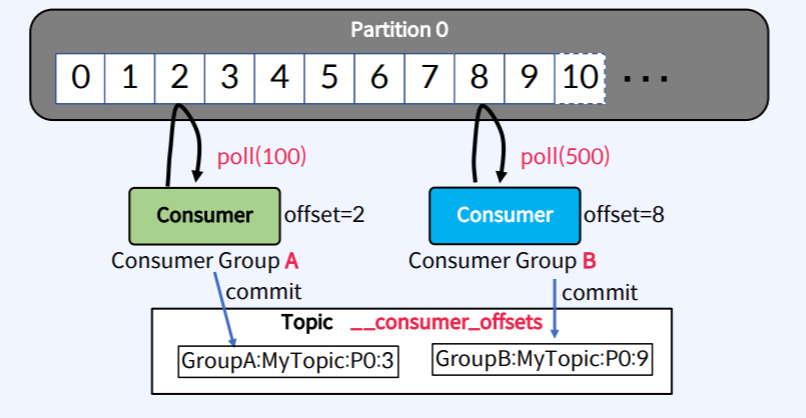
Consumer는 메시지를 가져오기 위해서 Partition에 연속적으로 Poll한다.가져온 위치를 나타내는 offset 정보를 \_\_consumer_offsets Topic에 저장하여 관리한다.동일한 group.id로 구성된 모든 Consumer들은 하나의 Cons
12.Apache Kafka - Partition Assignment Strategy
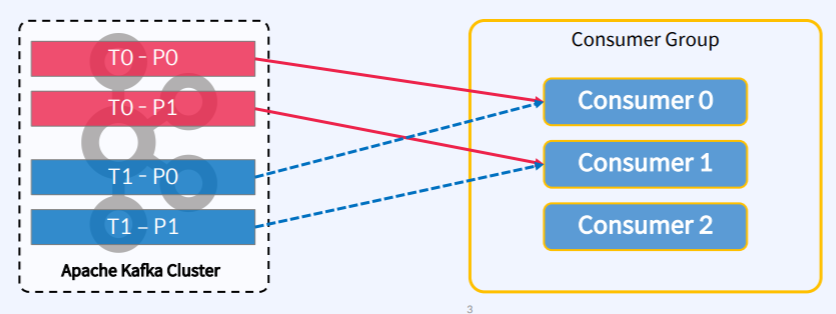
Conumser의 설정 파리미터 중에서 partition.assingment.strategy로 할당 방식을 조정할 수 있다.org.apache.kafka.clients.consumer.RangeAssginor : Topic별로 작동하는 Default Assignoror