In-Sync-Replicas(ISR)
Leader 장애시 Leader를 선출하는데 사용된다.
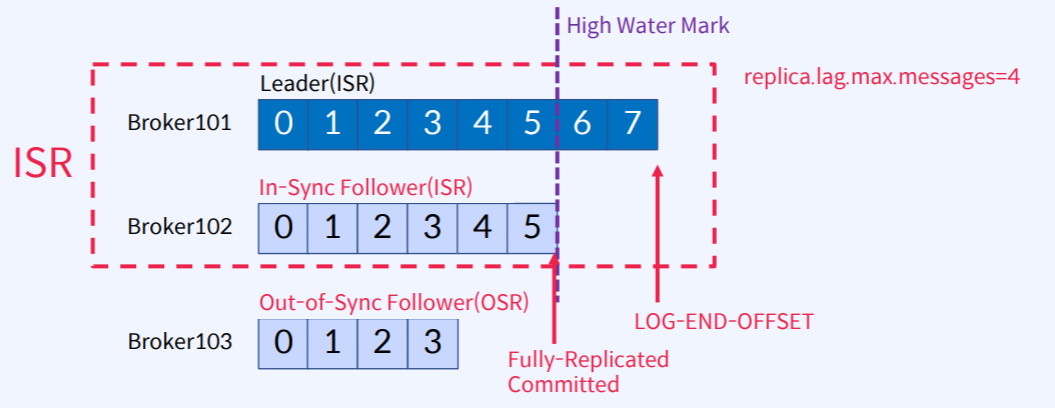
In-Sync-Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas (Leader와 Follower 모두)의 목록
- 가정 : replica.lag.max.messages=4 라고 할 때
- Leader의 LOG-END-OFFSET은 7이고 High Water Mark는 5인데 (Follower 중에 가장 잘 따라 잡는애가 Fully 복제하고 Commit까지 한 위치)
- Broker103은 Leader인 Broker101과 Offset이 4만큼 차이나기 때문에 replica.lag.max.message=4 옵션에 해당하게 된다.
- 이 때 Leader는 ISR이 되고 가장 잘 따라 잡고 있는 Follower는 In-Sync Follower(ISR)가 되고 Broker103은 Out-of-Sync Follower(OSR)이 된다.
- 이렇게 Leader와 잘 따라잡고 있는 Follower를 ISR이라고 한다.
- 이 때 Leader(Broker101)에 장애가 발생하면 ISR 중에서 새 Leader(Broker102)가 선출이 된다.
replica.lag.max.messages 사용시 문제점
메시지 유입량이 갑자기 늘어날 경우
replica.lag.max.messages로 ISR 판단시 나타날 수 있는 문제점
- 메시지가 항상 일정한 비율(초당 유입되는 메시지, 3 msg/sec 이하)로 Kafka로 들어올 때, replica.lag.max.messages=5로 하면 5개 이상으로 지연되는 경우가 없으므로 ISR들이 정상적으로 동작한다.
- 메시지 유입량이 갑자기 늘어날 경우 (초당 10 msg/sec), 지연으로 판단하고 OSR(Out-of-Sync Replica)로 상태를 변경 시킨다.
- 실제로 Follower는 정상적으로 동작하고 단지 잠깐 지연만 발생했을 뿐인데 replica.lag.max.messages 옵션을 이용하면 OSR로 판단하게 되는 문제가 발생한다. ( 운영중에 불필요한 error 발생 및 그로 인한 불필요한 retry를 유발시킨다.)
replica.lag.time.max.ms로 판단해야 한다.
- Follower가 Leader로 Fetch 요청을 보내는 Interval을 체크한다.
- ex) replica.lag.time.max.ms = 10000 이라고 한다면 Follower가 Leader로 Fetch 요청을 10000ms 내에서만 요청하면 정상으로 판단한다.
- Confluent에서는 replica.lag.time.max.ms 옵션만 제공한다.(복잡성 제거)
ISR은 Leader가 관리
Zookeeper에 ISR 업데이트, Controller가 Zookeeper로부터 수신
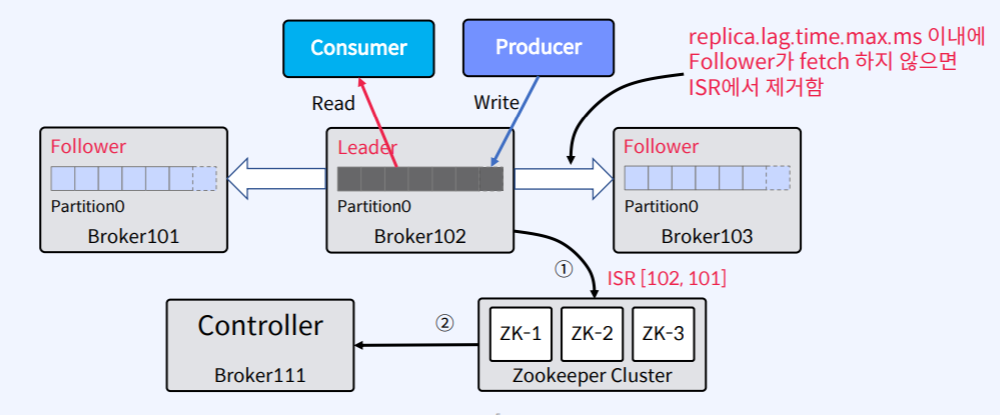
- ISR은 해당 Partition의 Leader가 떠있는 Broker가 관리한다.
- 이 때 replica.lag.time.max.ms 이내에 Follower가 fetch 하지 않으면 ISR에서 제거된다.
- Follower가 너무 느리면 Leader는 ISR에서 Follower를 제거하고 Zookeeper에 Partition Metadata에 대한 변경 사항을 알려준다.
- Zookeeper는 Broker중에 하나인 Controller라고 하는 곳으로 변경 사항을 다시 보내준다.
- Controller는 Partition Metadata에 대한 변경 사항에 대해서 나머지 Broker들에게 알려준다.
Controller
- Kafka Cluster 내의 Broker 중 하나가 Controller가 된다.
- Controller는 Zookeeper를 통해 Broker Liveness를 모니터링 한다.
- Controller는 Leader와 Replica 정보를 Cluster 내의 다른 Broker들에게 전달한다.
- 전달하는 이유 : Controller는 Zookeeper에 Replicas 정보의 복사본을 유지한 다음 더 빠른 엑세스를 위해 클러스터의 모든 Broker들에게 동일한 정보를 캐시한다.
- Controller가 Leader 장애시 Leader Election을 수행한다.
- Controller가 장애가 나면 다른 Active Broker들 중에서 재선출된다.
Consumer 관련 Position들
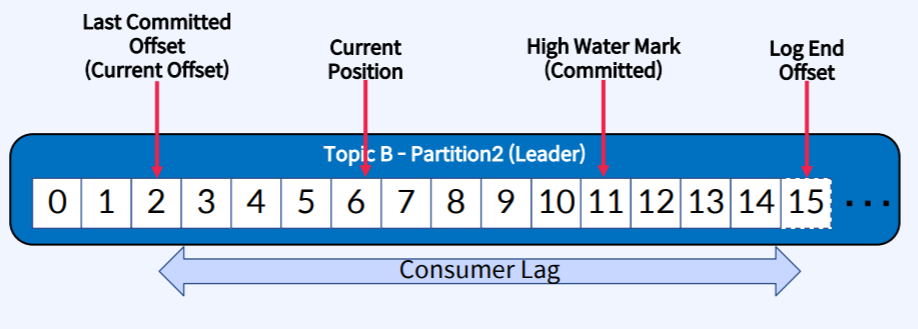
- Last Committed Offset(Current Offset) : Consumer가 최종 Commit한 Offset
- Current Position : Consumer가 읽어간 위치(처리중, Commit 전)
- High Water Mark(Committed) : ISR(Leader-Follower)간에 복제된 Offset
- Log End Offset : Producer가 메시지를 보내서 저장된 로그의 맨 끝 Offset
Committed의 의미
ISR 목록의 모든 Replicas가 메시지를 받으면 "Committed"
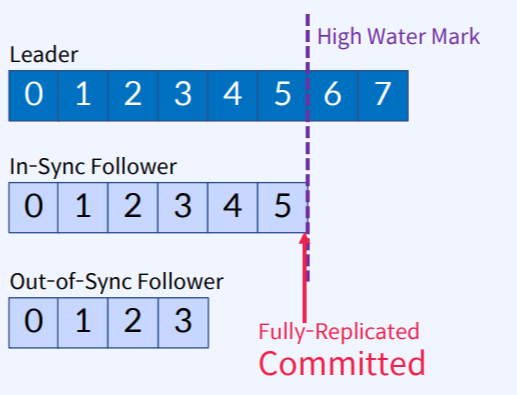
- ISR 목록의 모든 Replicas가 메시지를 성공적으로 가져오면 "Committed"
- Consumer는 Committed 메시지만 읽을 수 있다.
- Leader는 메시지를 Commit할 시기를 결정한다.
- Committed 메시지는 모든 Follower에서 동일한 Offset을 갖도록 보장한다.
- 즉 어떤 Replica가 Leader인지에 관계없이(장애가 발생하더라도) 모든 Consumer는 해당 Offset에서 같은 데이터를 볼 수 있다.
- Broker가 다시 시작할 때 Committed 메시지 목록을 유지하도록 하기 위해 Broker의 모든 Partition에 대한 마지막 Committed Offset은 replication-offset-checkpoint라는 파일에 기록된다.
Replicas 동기화
High Water Mark
- 가장 최근에 Committed 메시지의 Offset 추적
- replication-offset-checkpoint 파일에 체크포인트를 기록한다.
Leader Epoch
- 새 Leader가 선출된 시점을 Offset으로 표시한다.
- Broker 복구 중에 메시지를 체크포인트로 자른 다음 현재 Leader를 따르기 위해 사용된다.
- Controller가 새 Leader를 선택하면 Leader Epoch를 업데이트하고 해당 정보를 ISR 목록의 모든 구성원들에게 보낸다.
- leader-epoch-checkpoint 파일에 체크포인트를 기록한다.
Message Commit 과정
Follower에서 Leader로 Fetch만 수행
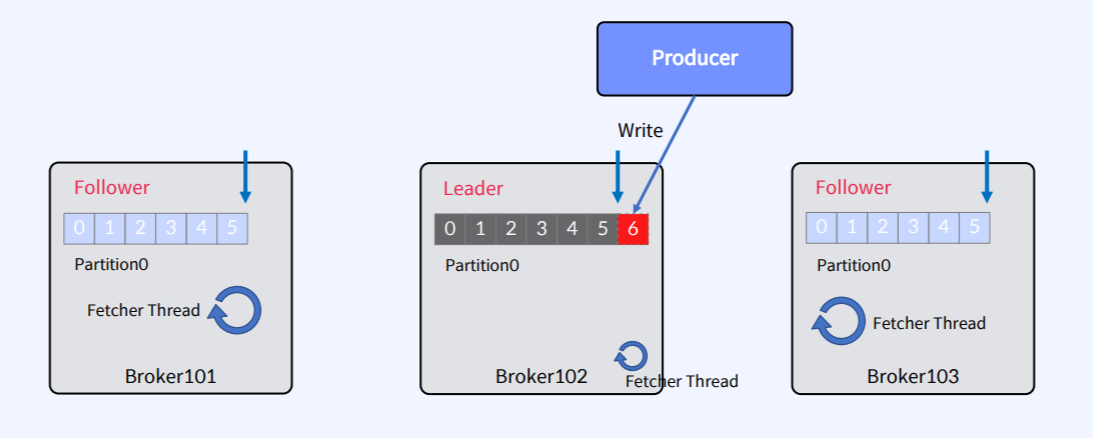
- Offset 5까지 복제가 완료되어 있는 상황에서 Producer가 메시지를 보내면 Leader가 Offset 6에 새 메시지를 추가한다.
- 각 Follower들의 Fetcher Thread가 독립적으로 fetch를 수행하고 가져온 메시지를 Offset 6에 메시지를 Write한다.
- 각 Follwer들의 Fetcher Thread가 독립적으로 다시 fetch를 수행하고 null을 받는다. Leader는 High Water Mark를 이동시킨다(5->6).
- 각 Follower들의 Fetcher Thread가 독립적으로 다시 fetch를 수행하고 High Water Mark를 받는다.
요약
- In-Sync-Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas(Leader와 Follower 모두)의 목록
- High Water Mark(Committed) : ISR(Leader-Follower)간에 복제된 Offset
- Consumer는 Committed 메시지만 읽을 수 있다.
- Kafka Cluster 내의 Broker 중 하나가 Controller가 된다.
- Controller는 Zookeeper를 통해 Broker Liveness를 모니터링 한다.

현시깁니다