In-Sync Replicas 리스트 관리
Leader가 관리함
- 메시지가 ISR 리스트의 모든 Replica(복제본)에서 수신되면 Commit된 것으로 간주한다.
- Kafka Cluster의 Controller가 모니터링하는 Zookeeper의 ISR 리스트에 대한 변경 사항은 Leader가 유지한다.
- n개의 Replica가 있는 경우 n-1개의 장애를 허용할 수 있다.
Follwer가 실패하는 경우
- Leader에 의해 ISR 리스트에서 삭제된다.
- Leader는 새로운 ISR을 사용하여 Commit 한다.
Leader가 실패하는 경우
- Controller는 Follower 중에서 새로운 Leader를 선출한다.
- Controller는 새 Leader와 ISR 정보를 먼저 Zookeeper에 Push한 다음 Local Caching을 위해 Broker에 Push 한다.
ISR은 Leader가 관리
Zookeeper에 ISR 업데이트, Controller가 Zookeeper로부터 수신
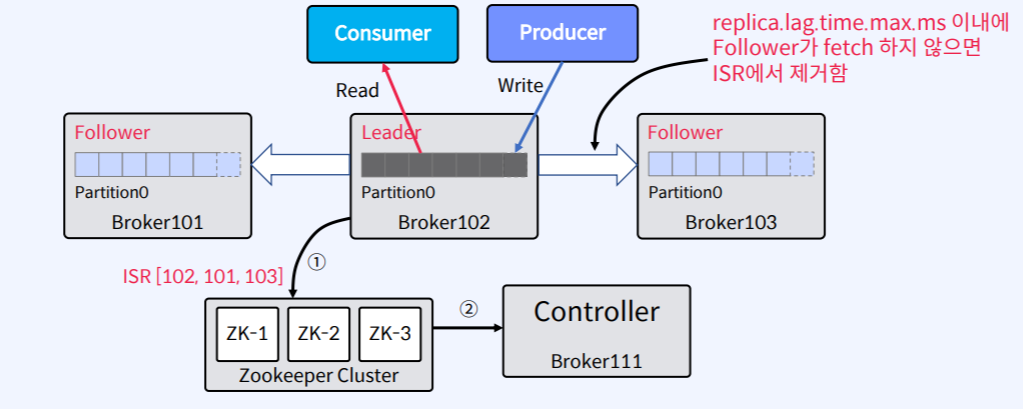
- 위의 그림을 보면 Broker가 총 3대가 있고 양쪽에는 Follwer, 가운데에는 Leader Broker가 있다.
- Client(Consumer/Producer)는 Leader Broker에 있는 Partition에 Read 하고 Write 하고 있다.
- 그런데 이 때 replica.lag.time.max.ms 이내에 Follwer가 fetch 하지 않으면 ISR에서 제거된다.
제거 되는 순서
- Follower가 너무 느리면 Leader는 ISR에서 Follower를 제거하고 Zookeeper에 Partition Metatdata에 대한 변경 사항을 알린다.
- Zookeeper는 Partition Metatdata에 대한 변경 사항을 Controller에게 알려준다.
- Controller는 Partition Metatdata에 대한 변경 사항에 대해서 Zookeeper로 부터 받는다.
- Controller가 Partition Metatdata에 대한 변경 사항을 나머지 모든 Broker들에게 알려준다.
Leader Failure
Controller가 새로운 Leader를 선출한다.
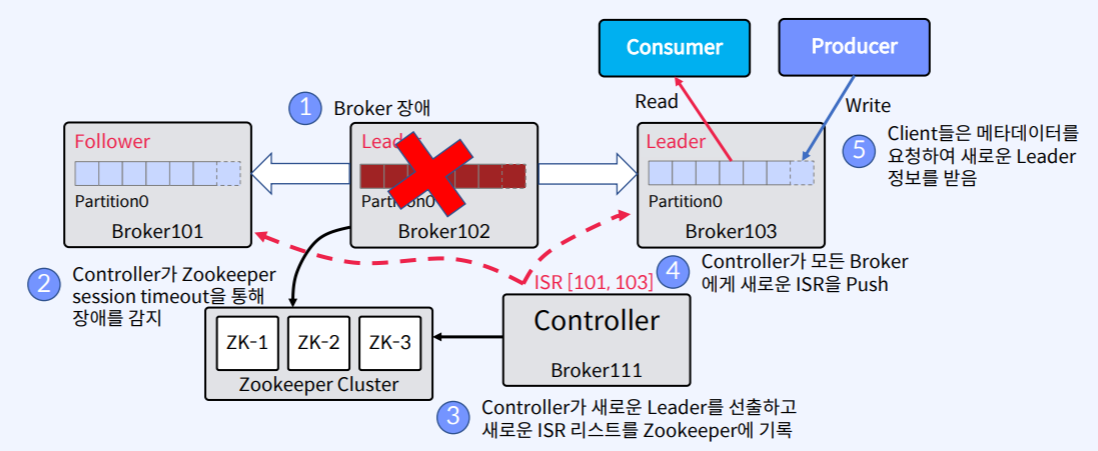
- Leader Broker에서 장애가 발생했다.
- Zookeeper에서 Session Timeout을 통해 Leader Broker에 장애가 발생한 사실을 감지한다.
- Zookeeper가 이 사실을 Controller에게 알려준다.
- Controller는 새로운 Leader를 선출하고 새로운 ISR 리스트를 Zookeeper에 기록한다.
- 그리고나서 Controller는 모든 Broker에게 새로운 ISR 정보를 Push한다.
- Client(Consumer/Producer)들은 Metadata를 요청하여 새로운 Leader 정보를 받는다.
Broker Failure
Broker 4대, Partition 4, Replication Factor가 3일 경우를 가정
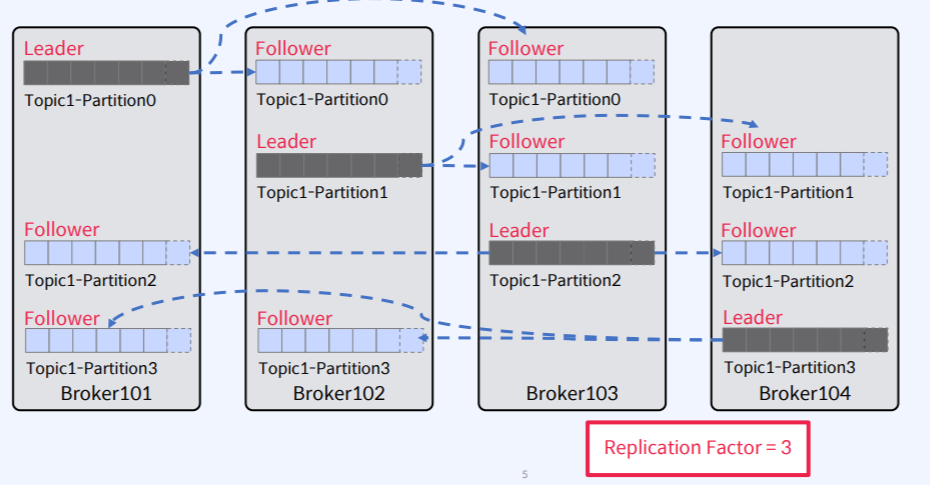
- Partition 생성 시 Broker들 사이에서 Partition들이 분산하여 배치된다.
- Replication Factor가 3이므로 Partition 1개 당 Leader(1) + Follower(2)로 구성되어 있다.
이 때 Broker 4에 장애가 발생하면??
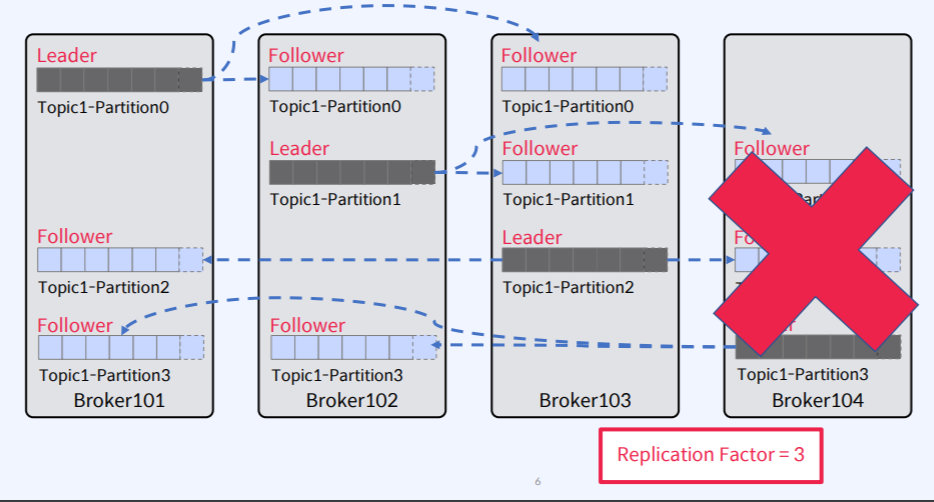
- Partition 0은 아무런 타격이 없다.
- Partition 1과 2는 Follower를 하나 잃었을 뿐 그대로 있는다.
- Partition 3은 Leader가 죽었기 때문에 Broker 101또는 102에 있는 Partition3 중에 하나가 Leader로 선출이 되면서 Leader(1) + Follower(1) 형태를 갖추게 된다.
Partition Leader가 없으면
- Leader가 선출될 때 까지 해당 Partition을 사용할 수 없게 된다.
- Producer의 send()는 retires 파라미터가 설정되어 있으면 재시도한다.
- 만약 retires=0 이면 NetworkException이 발생한다.
요약
- Follower가 실패하는 경우 Leader에 의해 ISR 리스트에서 삭제되고 Leader는 새로운 ISR을 사용하여 Commit 한다.
- Leader가 실패하는 경우 Controller는 Follower 중에서 새로운 Leader를 선출하고 Controller는 새 Leader와 ISR 정보를 먼저 Zookeeper에 Push 한 다음 Local Caching을 위해 모든 Broker에 Push 한다.
- Leader가 선출될 때 까지 해당 Partition은 사용할 수 없게 된다.

현시깁니다