arxiv: https://arxiv.org/abs/1810.04805
date: 05/28/2022

Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[Abstract]
- 새로운 language representation model BERT(Bidirectional Encoder Representations from Transformers) !
- (논문 저술 당시) language representation model들과 달리 BERT는 unlabeled data로 모델을 pre-train한 뒤, 특정 task에 맞게 fine-tuning하는 형태
- 모든 layer에서 왼쪽 / 오른쪽 문맥을 같이 고려 → 양방향 심층표현 pre-train
- pre-trained BERT 모델은 task에 맞는 하나의 output layer만 추가하면 fine-tuned 될 수 있음
- 성능 좋음 !
[Introduction]
- language model pre-training은 많은 자연어 처리 task에서 유용하다고 알려져있음
- 특히 문장 단위 task(natural language inference, paraphrasing) ; 문장을 총체적으로 분석해 문장 간 관계를 예측해야 함
- token 단위 task(aimed entity recognition, question answering) ; 모델이 token 단위에서 정밀한 결과를 도출해야 함
- 기존 pre-trained language representation 활용 방식 두 가지
- feature-based : ELMo → task에 최적화된 구조를 이용(pre-trained representations을 additional features처럼 이용)
- fine-tuning : GPT → minimal task-specific parameters을 task에 맞춰 전부 fine-tuning하는 방식
- → 두 방식 모두 pre-training시 general language representation을 학습하기 위해 unidirectional language model을 활용한다는 공통점 가짐
- 기존의 pre-train 방식은 pre-trained representations의 역량을 제한한다 !
- 특히 unidirectional model을 활용하다보니 pre-training 시 architecture 선택에 제약이 있을 수 밖에 없음
- 이러한 제한으로 인해 sentence 단위 task에 있어 성능 저하를 야기할 가능성이 큼. sentence 단위 task의 경우 앞뒤 문맥 모두가 중요하기 때문.
- BERT는 이런 제약 사항을 다 개선했다 !
- unidirectional constraint → MLM(masked language model) 사용
- MLM : input의 일부를 랜덤하게 masking하고 masked token을 문맥에 기반하여 예측하도록 함. 이를 통해 deep bidirectional transformer 학습 가능
- unidirectional constraint → MLM(masked language model) 사용
- BERT의 주요 contrubutions
- bidirectional pre-training이 중요하다 !
- pre-trained representations이 heavily-engineered task-specific architecture의 필요성을 감소시킨다.
- BERT 성능 짱좋음
[Related Work]
pre-training general language representation의 긴 역사〰
- Unsupervised Feature-based Approaches
- ELMo, LSTM
- Unsupervised Fine-tuning Approaches
- OpenAI GPT
- Transfer Learning from Supervised Data
- 큰 dataset을 사용하는 supervised tasks의 경우 효과적인 transfer learning
[BERT]

-
개괄
- 두가지 step
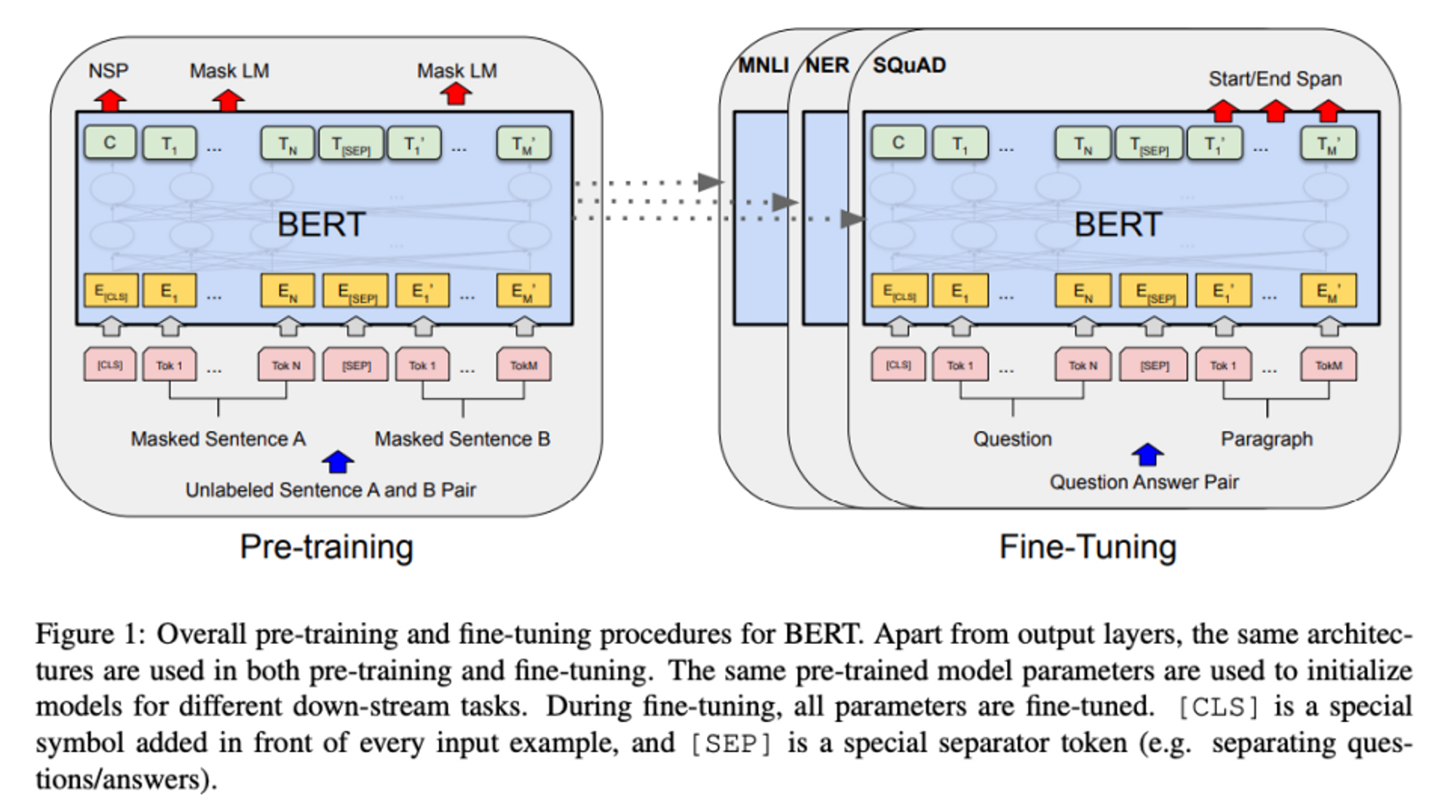
- pre-training
: unlabeled data로 train됨 - fine-tuning
: pre-trained parameters로 시작, 모든 parameters가 labeled data로 train되며 task에 맞게 fine-tuned
- pre-training
- 두가지 step
-
BERT의 독특한 특성 = 서로 다른 task를 관통하는 통합된 architecture !
: pre-trained architecture과 fine-tuned architecture 크게 다르지 않음 -
Model Architecture
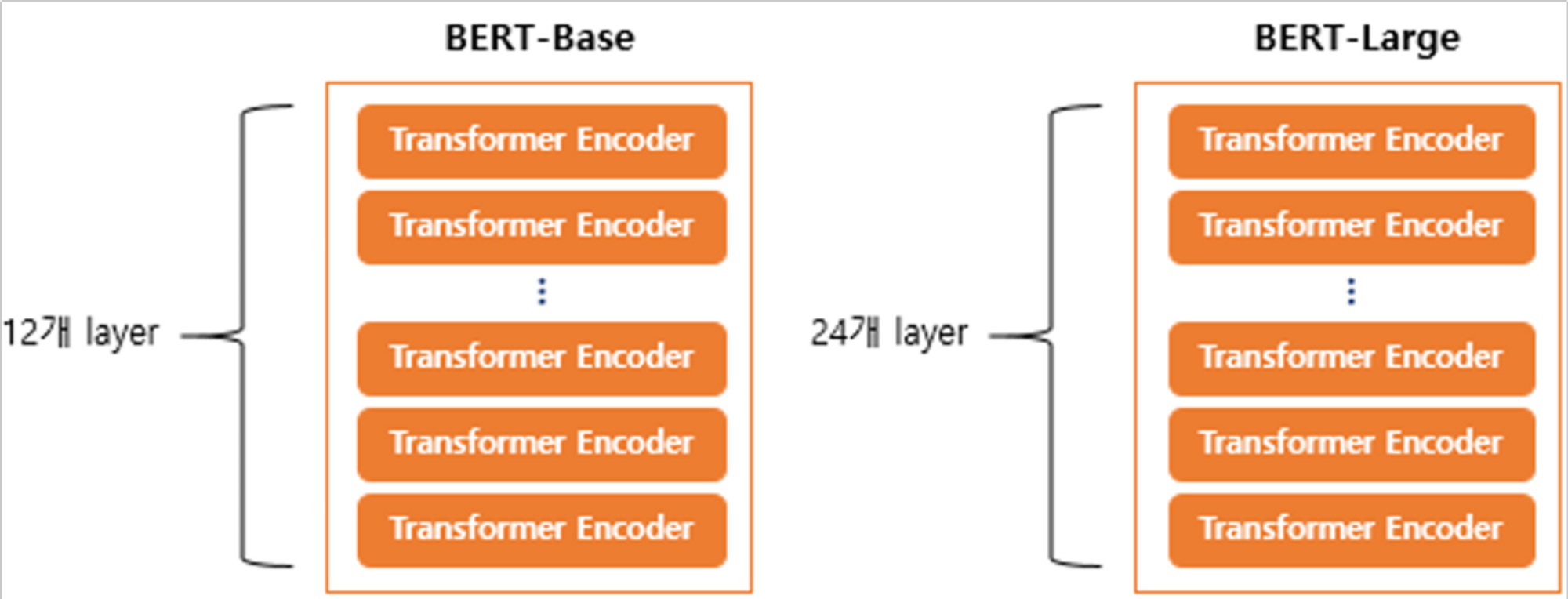
- multi-layer bidirectional transformer encoder을 여러 개 쌓아서 구성
- two model sizes ( 트랜스포머 인코더 층의 수 =L, d_model의 크기 =D, 셀프 어텐션헤드의 수 =A )
- BERT-base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
- Input/output representations
- BERT의 input, 하나의 문장일 수도 있지만 두 개의 문장이 묶인 것 일 수도(ex. Q&A)
- '문장'이 한 문장을 의미한다기 보다, 연속적 텍스트의 집합이라고 보는 것이 더 맞을 듯
- 두 개의 문장이 묶인 경우에도 하나의 input으로 들어감
- BERT의 input, 하나의 문장일 수도 있지만 두 개의 문장이 묶인 것 일 수도(ex. Q&A)
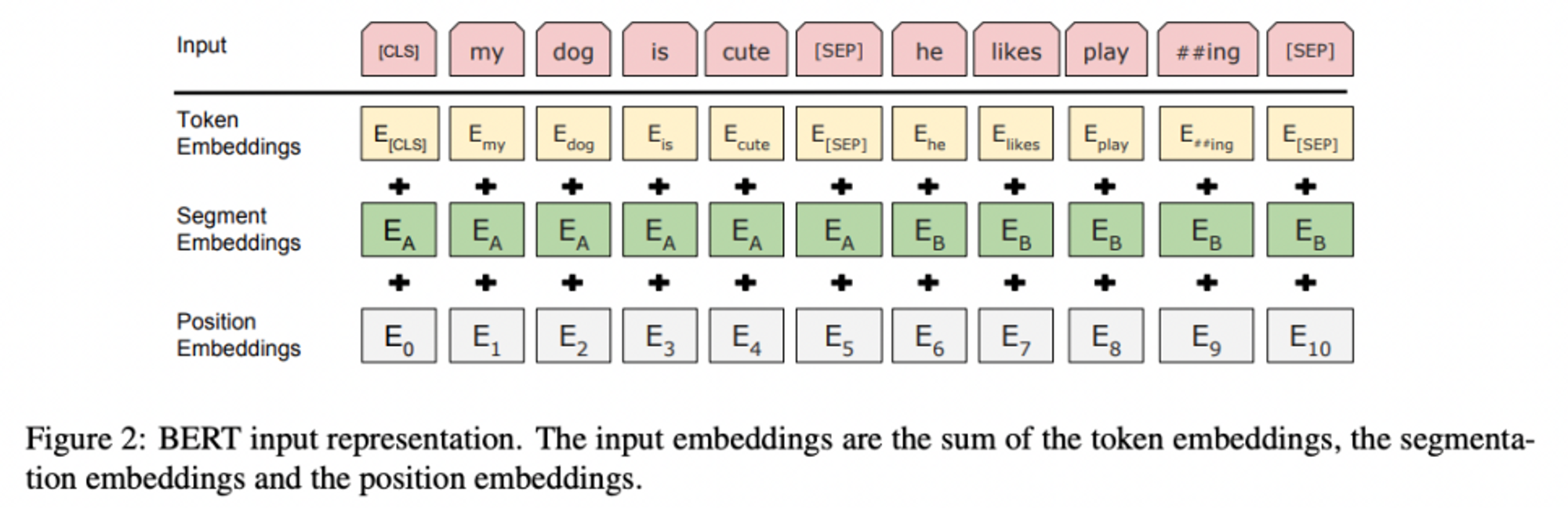
-
DetailWordPiece embedding 사용
: 모든 시퀀스의 첫번째 토큰은 [CLS]문장과 문장 사이에는 [SEP]라는 토큰을 두어 서로 다른 문장임을 드러냄 (문장 pair를 다룰 때 잘 작동할 수 있게끔) + 토큰이 어떤 문장에 해당하는지를 알려주는 토큰을 추가 -
최종 input : 3가지 임베딩 값의 합
- Token embedding
: WordPiece embedding with a 30,000 token vocab - Segment embedding
: 토큰이 어떤 문장에 해당하는지 embedding - Position embedding
: transformer에서 활용했던 것과 같은 embedding
- Token embedding
-
Pre-training BERT
- BERT, 두 종류의 unsupervised tasks를 통해 pre-train 된다 !
- Masked LM (MLM)
- problem
: standard conditional language models, left-to-right or right-to-left으로 밖에 train 시킬 수 없음 ( bidirectional conditioning이 language model에게 cheat sheet을 보는 것 같은 결과를 도출할 수도 있기 때문 ) - solution : BERT, 일정 비율의 token을 mask
- 해당 논문에서는 전체 토큰의 15%를 랜덤하게 mask
- [MASK] token들의 final representation을 단어 차원으로 매핑되게 하고, 그것에 softmax를 거치게 해 단어들에 대한 확률분포로 변환 → 실제 토큰과 비교하여 loss 구하고 weight update
- fine-tuning 과정에서는 [MASK] 토큰을 사용하지 않기 때문에 이러한 방식은 pre-traing하는 과정에서는 매우 효과적일 수 있지만, 다른 task 수행 시 문제가 발생할수도 → 이 간극을 완화하기 위해 늘 mask된 단어를 [MASK] 토큰으로 교체하지는 않음
- 이런 방식 채택
- 80%의 경우 : token을 [MASK]로 바꿈 ( my dog is hairy -> my dog is [MASK] )
- 10%의 경우 : token을 random word로 바꿔줌 ( eg., my dog is hairy-> my dog is apple )
- 10%의 경우 : token을 원래의 단어로 그대로 놔둠 (실제 관측된 단어에 대한 표상을 bias해주기 위함 )
- 이런 방식 채택
- 해당 논문에서는 전체 토큰의 15%를 랜덤하게 mask
- problem
- Next Sentence Prediction (NSP)
- Question-answering(QA), Natural Language Inference(NLI)등의 task는 두 문장 사이의 관계를 이해해야 하는 task
- 문장 사이의 관계는 language modeling을 통해서 학습하기 어렵기 때문에, NSP라는 task에 대해서도 함께 학습을 진행
- 해당 논문에서의 NSP task, 어떤 두 개의 sentence가 실제로 이어진 문장인가 아닌가 판단하는 binary classification
- 학습 과정에서 모델은 두 문장 A, B를 입력으로 제공받음
- 50% : sentence A, B가 실제 이어진 두 문장
- 50% : sentence A, B가 random으로 뽑힌(관계가 없는) 두 문장
- 매우 단순한 task 같아 보이지만, QA와 NLI task의 성능 향상에 큰 도움이 됨 !
- 학습 과정에서 모델은 두 문장 A, B를 입력으로 제공받음
-
Fine-Tuning BERT
- Downstream task에 따라 적절한 입력을 만들어 fine tuning, 하나의 layer만 위에 쌓으면 어떠한 task도 해결할 수 있음
- 2가지 sentence가 어떤 관계를 가지는가를 설명하는 것 가능
- A 다음에 나오는 문장이 자연스러운 관계(문맥상 흐름)를 가지는가? 의미상으로 유사한가? 분류
- 하나의 문장을 넣고, 감성이 긍정이냐 부정이냐 중립이냐를 분류하는 것 가능
- QA task: Question에 정답이 되는 paragraph의 substring을 뽑아내는 것.
- [SEP] token 이후의 token들에서 Start/End Span을 찾아내는 task를 수행
- Named Entity Recognition(NER), 형태소 분석 같이 single sentence에서 각 토큰이 어떤 class를 갖는지에 대해 classifier 적용하여 정답을 찾아내는 것도 가능
- 2가지 sentence가 어떤 관계를 가지는가를 설명하는 것 가능
- Downstream task에 따라 적절한 입력을 만들어 fine tuning, 하나의 layer만 위에 쌓으면 어떠한 task도 해결할 수 있음
-
- Feature-based Approach with BERT
- BERT, 기본적으로 pre-train → fine-tuning하는 방식을 취함
- pre-train BERT로부터 뽑아낸 representation vector를 하나의 feature vector로 task-specific한 다른 모델에 input으로 넣어주는 feature-based approach로도 효과적으로 작동한다. (fine-tuning 방법들만큼은 아니나 준수한 성능)
- Feature-based Approach with BERT
[Conclusion]
- rich, unsupervised pre-training이 language understanding system에 중요하다는 건 알려져왔음
- 이러한 결과들은 low-source task들에서까지 deep unidirectional architecture의 효용이 있음을 보여줌
- 본 논문에서는 이를 deep bidirectional architecture로까지 발전시켰고, pre-trained model이 더 넓은 범주의 NLP task들을 성공적으로 다룰 수 있게 하였음 !
[Reference]
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- https://velog.io/@changdaeoh/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-BERTpre-training-of-deep-bidirectional-transformers-for-language-understanding-2018
