arxiv: https://arxiv.org/abs/1907.11692
date: 05/29/2022

Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Abstract
- BERT는 undertrained 되어 있다 !
- BERT, BERT 이후에 나온 모델들보다 더 나은 성능을 낼 수 있음
- 설계의 중요성 !
Introduction
- ELMo, GPT, BERT, XLM, XLNet과 같은 self-training methods, 좋은 성능을 보였으나 해당 모델의 어떤 요인이 성능 향상에 기여했는지 알기 어려움
- training이 computationally expensive하기 때문에 tuning 될 수 있는 여지가 제한됨 → model 속에서 어떤 요인이 어떤 영향을 미쳤는지 측정하기 어렵
- 우리는 BERT의 Replication study를 소개한다 !
- hyperparameter tuning과 training set size의 영향을 세밀하게 분석함
- 이를 통해 우리는 BERT가 굉장히 undertrained 되어 있음을 알 수 있었음
- BERT 모델을 학습시키기 위해 더 나은 recipe를 제안하겠다 ! = RoBERTa
- main modifications
- model을 더 오래 학습, with bigger batches, over more data
- NSP(next sentence prediction) objective 없앰
- 더 긴 sequence로 학습
- masking pattern을 다이나믹하게 변화
- 새로운 대규모 데이터셋 사용 (CC-NEWS) → training set size의 영향 측정 위함
- contributions
- 좋은 task 수행력으로 이어지는 구조적 alternatives 제시 (BERT design choices, training strategies)
- CC_NEWS dataset의 사용 → pre-training에 더 많은 데이터를 쓰는 것이 좋은 task 수행력으로 이어진다 !
- MLM(masked language model) pretraining, 올바른 design choice를 한다면 (논문 저술 시기) 어떠한 다른 방법보다 더 좋은 성능을 낸다 !
Background
: brief overview of the BERT pretraining approach / training choices
-
Setup
- input, 두 segments의 묶음 (segments, 하나 이상의 문장으로 구성됨)이 한번에 들어감
- input sequence를 나눠주는 special tokens : [CLS] , [SEP] , [EOS] 등
- 먼저 unlabeled text corpus로 pretrained → task에 맞는 labeled data로 finetuned
-
Architecture
- ubiquitous transformer architecture을 씀 ( L layer의 transformer encoder stack / 각 block A개의 self-attention heads과 hidden dimension 사용 )
-
Training objectives
- MLM (masked language modeling)
- input sequence 중 랜덤한 수의 token들이 [MASK] 토큰으로 대체
- 전체 중 15% 토큰들이 masked 됨
- 그 중 80%가 [MASK] 토큰으로 대체되고
- 10%는 그대로 유지되고
- 10%는 랜덤한 다른 단어로 대체됨
- 전체 중 15% 토큰들이 masked 됨
- mask 처리 된 토큰들을 예측하는데 cross-entropy loss 활용
- BERT에서는 random masking이 처음에 한번 실행되고 training되는 동안 masked 된 결과가 유지됨
- 실제 상황에서는 데이터가 중복될 수 있기 때문에 mask가 고정된다면 문제가 발생할수도
- input sequence 중 랜덤한 수의 token들이 [MASK] 토큰으로 대체
- NSP (next sentence prediction)
- 두 문장이 이어지는지를 판단하는 binary classification
- positive examples : 텍스트 코퍼스에서 이어지는 두 문장을 가져옴
- negative examples :서로 다른 document에서 랜덤한 두 문장을 가져옴
- positive - negative examples, 동일한 확률로 샘플링됨
- 목표
- 문장 간 연관성 파악이 중요한 Natural Language Inference 등의 task에서 성능 개선
- 두 문장이 이어지는지를 판단하는 binary classification
- MLM (masked language modeling)
-
Optimization
-
BERT는 Adam을 활용해 optimized
-
parameters (learning rate, weight decay, dropout rate, minibatch size 등)은 다음과 같음

-
-
- Data
- combination of BOOKCORPUS + English WIKIPEDIA ( = 16GB of uncompressed text )
Experimental Setup
: 여러 hyperparameters에 대한 실험 진행
- Implementation
- 우선 BERT의 원래 optimization hyperparameters를 따랐음
- 그러던 중 adam optimizer의 hyperparameter 중 b2 = 0.98 일 때 보다 안정적이라는 것을 발견
- pre-train 시 최대 512 token으로 구성된 sequence를 사용하였음
- BERT의 저자들은 pre-train 시 처음 90%는 짧은 길이의 sequence를 사용하고 나머지 10%애서 full-length(512 tokens) sequence를 사용했지만, 본 논문에서는 처음부터 full-length의 sequence를 사용
- 우선 BERT의 원래 optimization hyperparameters를 따랐음
- Data
- BERT 스타일의 pre-train의 경우 좋은 성능을 내기 위해서 큰 규모의 데이터셋이 필요
- 여러 시도가 있어왔지만, 사적으로 수집한 데이터셋이 쓰이는 경우도 많아서 공유가 불가한 경우가 많았음
- 데이터셋이 각기 달랐기 때문에 모델들 간 비교도 어려웠음
- 본 논문에서 시도한 여러 데이터셋 조합들
- BOOKCORPUS + ENGLISH WIKIPEDIA (Original BERT)
- CC-NEWS (본 논문 연구진이 수집)
- OPENWEBTEXT (Reddit에서 3개 이상의 좋아요가 눌린 포스트들 수집)
- STORIES (story-like style)
- Evaluation 방법
- GLUE
- SQuAD
- RACE
Training Procedure Analysis
: 어떤 choice들이 BERT의 성능을 개선하는가?
→ 다만, BERT model architecture은 고정
( BERT-base : L=12, D=768, A=12 : 110M개의 파라미터 )
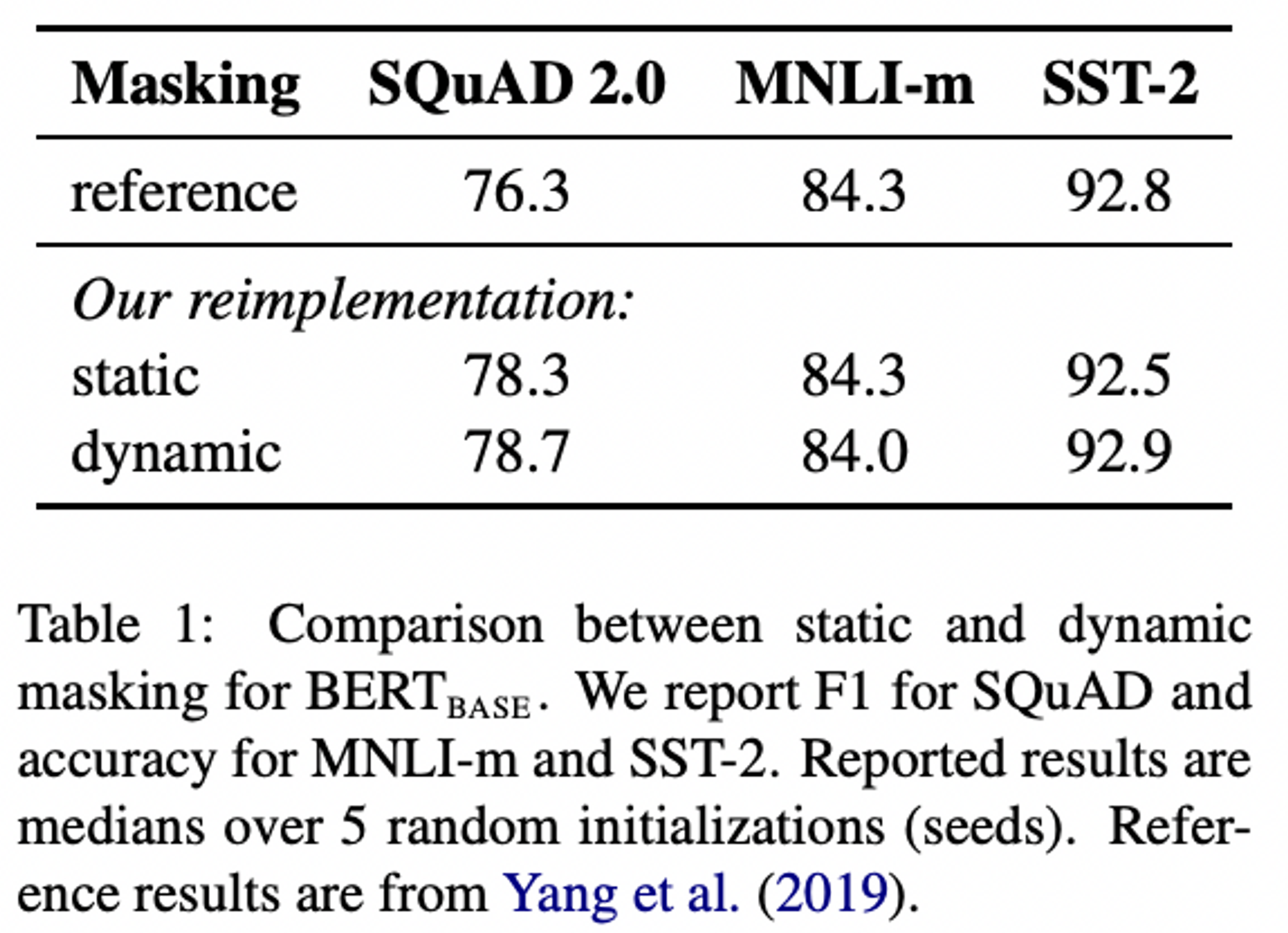
- Static vs. Dynamic Masking
- Static Masking ; BERT
- BERT는 random masking → masked token 예측하는 방식 채택
- 데이터 전처리 과정에서 masking되기 때문에 하나의 정적(static) mask 도출
- BERT는 random masking → masked token 예측하는 방식 채택
- Static Masking : Reimplementation
- training 과정 속 동일한 mask를 사용하는 것을 피하기 위해 각 sequence가 10가지 다른 방식으로 mask됨
- (40 epochs of training, 10 different ways of masking → each training sequence to be seen with the same mask 4 times during training)
- Dynamic Masking : RoBERTa
- 매 학습 epoch마다 다른 masking 진행
- 더 많은 step, 더 많은 dataset으로 pre-train할 경우 중요해짐
- 더 많은 step, 더 많은 dataset으로 pre-train할 경우 중요해짐
- 매 학습 epoch마다 다른 masking 진행
- 실험 결과
- static masking의 reimplementation version, 기존 BERT와 유사한 성능을 보임
- dynamic masking, static masking보다 성능이 살짝 더 나았음
- dynamic masking이 비교적 효용성이 높다고 판단해, 앞으로 남은 실험에서는 dynamic masking을 사용할 것 !
- Static Masking ; BERT
-
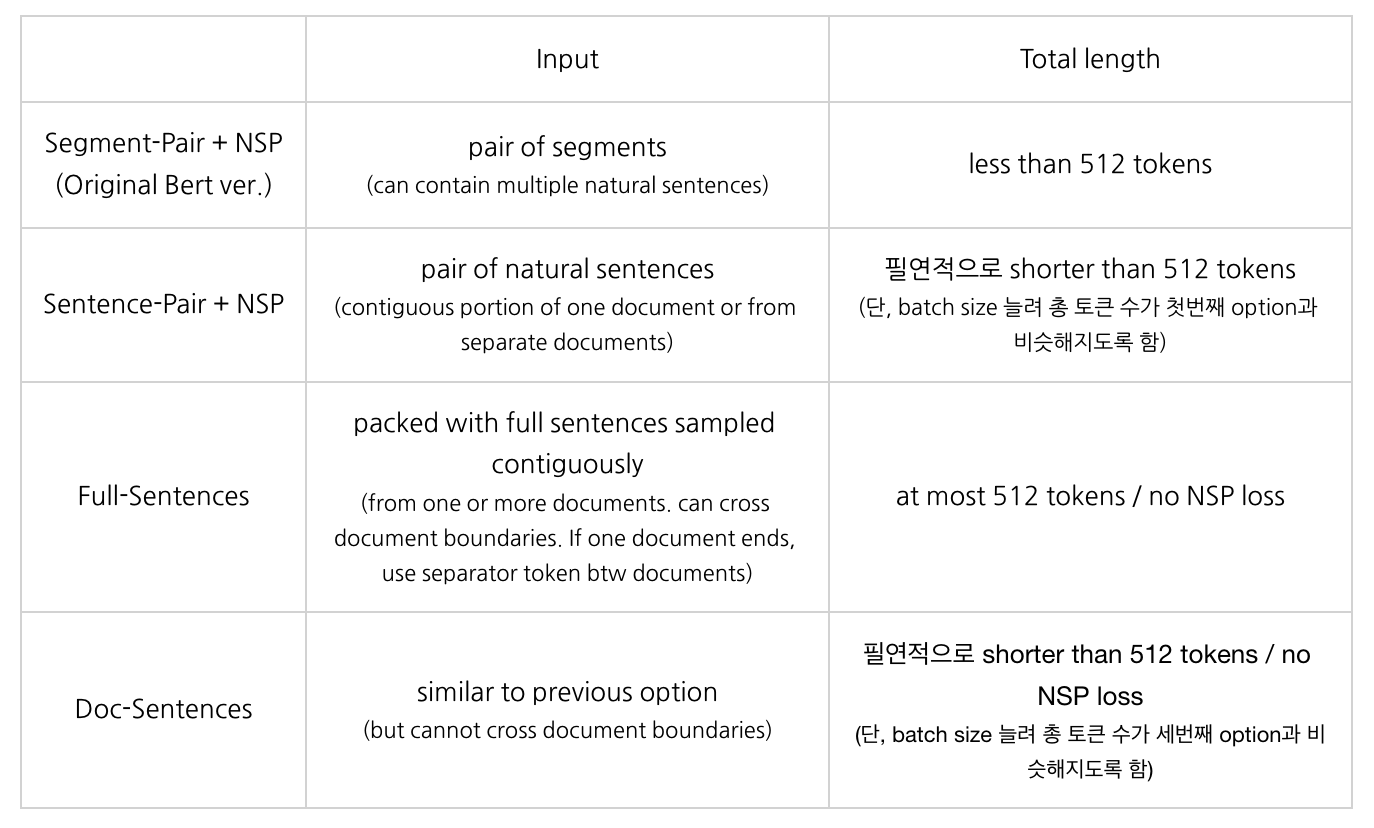
Model Input Format and Next Sentence Prediction
- Original BERT
- 모델이 두개의 segment가 실제로 이어지는 문장인가 아닌가 판단하는 binary classification인 NSP (Next Sentence Prediction) 진행
- original BERT 모델에 있어 NSP는 중요한 부분이라고 여겨져 왔음
- 실제로 그런가?
- Experiment setting
- Original BERT
-
실험 결과
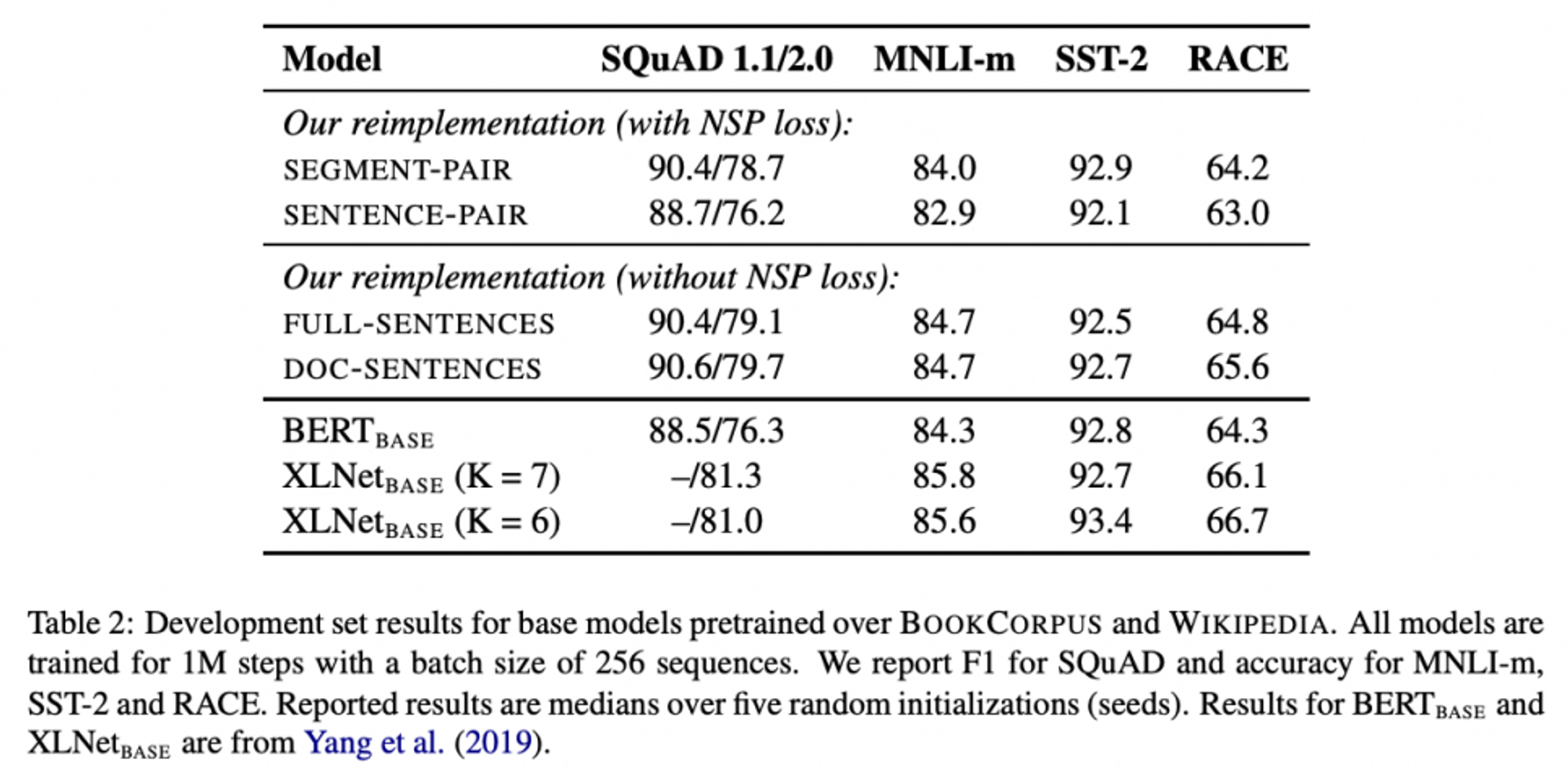
- 결과적으로 DOC-SENTENCES > FULL-SENTENCES > SEGMENT-PAIR > SENTENCE-PAIR 순으로 성능이 좋았음
- 개별 sentence(짧은 input 단위) 쓰는 것이 실제 task에 있어 좋지 못한 성능을 초래 !
- NSP 과정을 제거하는 것이 실제 task에 있어 성능 개선을 야기 !
- 여러 document을 input으로 쓰는 것보다 하나의 document 내 문장들을 input으로 쓰는 방식이 성능을 개선시킨다 !
(그치만 DOC-SENTENCE 사용할 때 batch size가 들쭉날쭉해지기 때문에 FULL SENTENCE 옵션을 앞으로의 남은 실험 과정에서 활용하겠다!)
- 결과적으로 DOC-SENTENCES > FULL-SENTENCES > SEGMENT-PAIR > SENTENCE-PAIR 순으로 성능이 좋았음
-
Training with large batches
- previously,
- 과거 연구들에서 learning rate가 적당히 클 때, 대규모의 mini-batch를 활용하면 optimization speed와 성능이 높아진다는 결과들이 나온 바 있음.
- BERT도 large batch training을 쓸 때 성능이 좋다더라~
- 실제로 그런가?
- 실험 결과
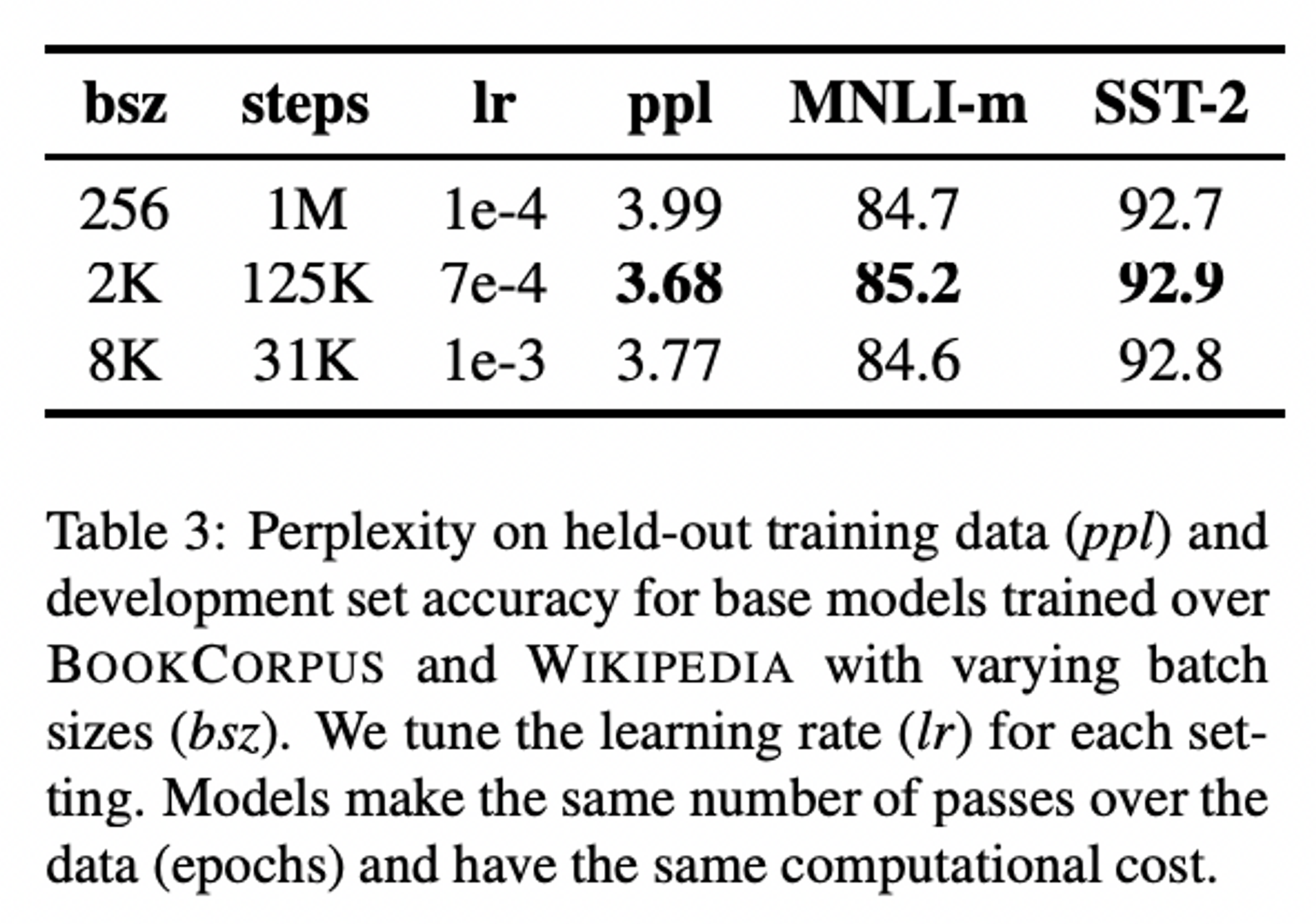 → training 시 batch size가 커지면 커질수록 perplexity, task 성능 모두 향상됨
→ training 시 batch size가 커지면 커질수록 perplexity, task 성능 모두 향상됨
- previously,
- Text Encoding
- BPE(Byte-Pair Encoding), word 단위와 character 단위 중간 쯤에 있는 text encoding 방식
- full word가 아닌 subwords 단위를 대상으로 하는데, 이는 큰 학습 코퍼스의 통계치에 의해 결정됨
- BERT, 사이즈 30K의 character-level BPE vocabulary 를 전처리해서 사용
- 본 논문에서는 50K 사이즈의 보다 큰 byte-level BPE vocabulary 활용. 전처리 과정 없음 → parameters의 증대 야기
- 이전 논문들에서 byte 단위가 character 단위에 비해 다소 좋지 않은 결과를 보였지만, 본 논문에서는 universal encoding의 이점을 믿고 남은 실험들에서 byte 단위 사용키로.
- BPE(Byte-Pair Encoding), word 단위와 character 단위 중간 쯤에 있는 text encoding 방식
RoBERTa
: RoBERTa : Robustly optimized BERT approach
- 위 실험들에서 나온 최적의 option들만을 채택해 최선의 모델을 만들어봤다 !
- dynamic masking
- FULL-SENTENCES without NSP loss
- large minibatches
- larger byte-level BPE
- + pretraining에 쓰이는 data / number of training passes 까지도 신경썼음 !
- basic settings
- BERT-Large architecture 사용하였음 ( L = 24, H = 1024, A = 16, 355M parameters )
- pretrain steps = 100K
- BOOK-CORPUS plus WIKIPEDIA dataset 사용
- 결과
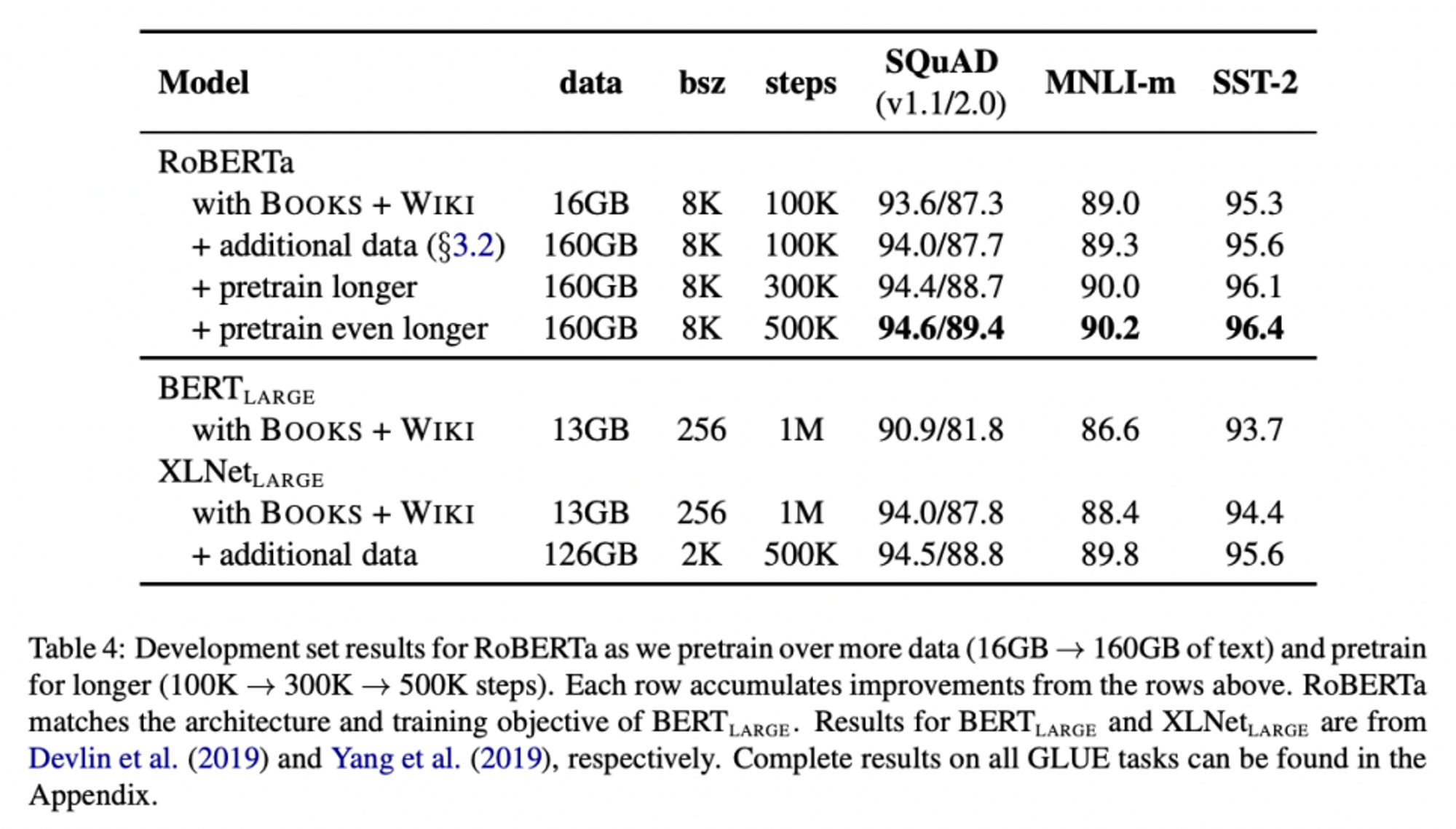
- RoBERTa, 기존 BERT-large보다 더 나은 성능을 보임
→ 모델 디자인의 중요성 ! - RoBERTa, BERT에 비해 pretrain에 더 다양하고 많은 데이터를 활용했음(160GB. cf, BERT : 16GB), 실제 task에 있어서 뛰어난 성능 도출
→ 데이터 사이즈와 다양성의 중요성 ! - RoBERTa, BERT에 비해 더 오랫동안, pretraining steps를 더 증가해가며 pretrain 시켰음 (100K → 300K → 500K), overfitting X, 실제 task에 있어서 뛰어난 성능 도출
→ 오랫동안 training하는 것이 성능 개선에 도움이 된다 !
- RoBERTa, 기존 BERT-large보다 더 나은 성능을 보임
Conclusion
- BERT 구조 하 pre-training 모델 디자인은 이렇게 했을 때 가장 좋은 성능을 보였음. 그걸 모아서 디자인한 게 바로 RoBERTa.
- dynamic masking
- FULL-SENTENCES without NSP loss
- large minibatches
- larger byte-level BPE
- 더 많은 양의 데이터를 더 큰 batch size로 학습에 사용했을 때, 모델을 더 오랫동안 학습시켰을 때, NSP를 없앴을 때, 더 긴 sequence를 input으로 하였을 때, masking pattern에 dynamic한 변화를 주었을 때 모델의 성능은 증대된다 !
Reference
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- https://baekyeongmin.github.io/paper-review/roberta-review/
