BERTGEN: Multi-task Generation through BERT

Mitzalis, F., Caglayan, O., Madhyastha, P., & Specia, L. (2021). BERTGEN: Multi-task Generation through BERT. arXiv preprint arXiv:2106.03484.
Abstract
- BERTGEN, decoder-only model이자 generative한 model
- VL-BERT(multimodal pretrained model)와 M-BERT(multilingual pretrained model)을 융합함으로써 BERT를 확장시킨 형태
- auto-regressively trained : 이전 token들의 정보를 보고 현재 timestep에 등장할 token 예측하는 방식으로 학습 (단방향, language generation에 특화된 학습 방식)
- language generation task에 특화된 모델 (image captioning, machine translation, multimodal machine translation)
Introduction
Prior Research
- pretrained language model, natural language understanding(NLU) 분야에 비약적인 발전을 불러옴
-
특히 BERT같이 masked language modelling(MLM) 방식으로 학습된 모델, multimodality를 다룰 수 있는 가능성을 열어줌
→ 주로 pre-trained model을 task-specific fine-tune 하는 방식으로 접근
-
- 그러나 pretrained MLM model을 natural language generation(NLG) 분야에 활용한 경우는 적었음
→ pretrained MLM model은 양방향 인코딩을 수행하는 auto-encoding(AE) 방식으로 학습되었기 때문에, language generation task에는 적합하지 않다는 의견이 대다수였음
BERTGEN
우리는 BERT를 generative하게 확장시킨 BERTGEN을 선보이겠다~
- 하나의 generator로 구성
- 다수의 input modality 처리 가능 + 다국어 생성 지원
: SOTA pretrained model인 VL-BERT(multimodal pretrained model)와 M-BERT(multilingual pretrained model)로부터 그 기능을 받아옴 - BERTGEN을 다양한 task(image captioning, machine translation, multimodal machine translation)에 대해 학습시켰고, 다국어 데이터로 학습시킴
🤸🏻 결과적으로 BERTGEN,
- 다국어 unimodal & multimodal translation에 능했고
- zero-shot setting에서도 잘했고
- 다른 SOTA 모델에 비해 parameter efficient !
Method
Model
Initialization
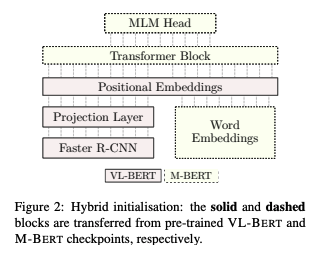
- VL-BERT(multimodal pretrained model)와 M-BERT(multilingual pretrained model)의 융합
- VL-BERT의 checkpoint 활용
- M-BERT로 word embedding + Transformer weight + MLM head initialize
- cf. VL-BERT : 영어 단일 언어로 된 image captioning corpora로 사전학습, M-BERT : 104개의 언어의 wikipedia data로 학습 → 119K WordPiece vocabulary 지원 )
Input Configuration
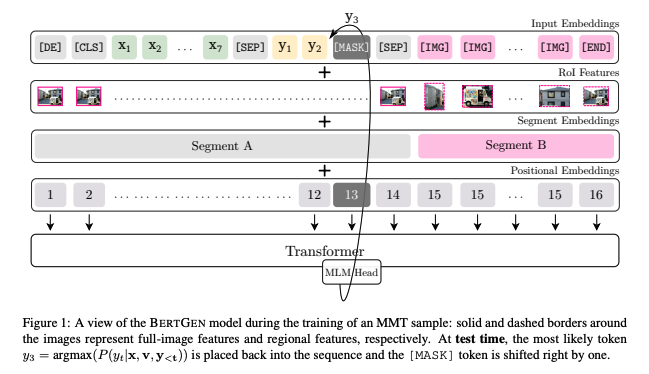
- BERTGEN은 다양한 generation task에 쓰일 수 있겠지만, 우리는 다음 세 task에 집중했다-
- machine translation (MT)
- multimodal MT (MMT)
- image captioning (IC)
- task에 따라 input configuration 다를 수 있음
- default
- source sentence embedding
- target sentence embedding
- regional visual features
- MMT
- input =
- MT
- input =
- IC
- input =
- default
Visual Embeddings
VL-BERT의 방식 채택 → 이미지를 k개의 features 의 합으로 표현
( feature vector 의 합과 geometric embedding의 합 )
- non-visual position (text data)을 encoding할 땐 전체 이미지에 대한 ROI feature vector가 동일하게 반복됨
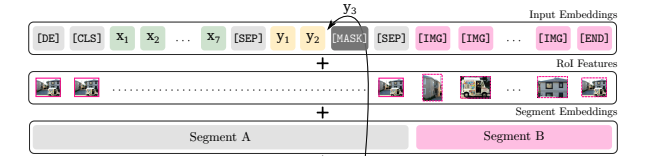
- training 시 object detector fine-tune 안 함
Sequence Unrolling
대다수의 seq2seq model이 encoder-decoder 구조로 이루어져 있는데 반해, BERTGEN은 encoder-decoder 구분이 명확하지 않음
→ MLM framework을 이용해서 encoding과 generation 둘 다 정립했기 때문
- e.g. MMT task
- input data : (단, 는 n개의 token으로 구성)
- maximum log-likelihood objective
- ( 일반적인 seq2seq model에서는 동일한 training example을 forward pass하는 과정에서 각 log probability가 decoder에 의해 계산됨 )
- BERTGEN, training example을 n번 unroll → n개의 training example 도출 : sequence 내 토큰 하나하나 차례로 masking하면 n개의 training example이 생기니까 결과적으로 sequence unrolling은 data augmentation 효과가 있음
(D개의 예시 문장으로 이루어진 training 코퍼스의 경우 target sentence의 평균 길이를 곱한 만큼 data 증강이 되는 셈)
+ encoder - decoder가 결합된 형태의 모델이기 때문에 파라미터 수가 반으로 줄어듦
→ BERTGEN이 parameter efficient한 이유
Self Attention
기존 Transformer는 encoder-decoder 구조로 되어있음
→ BERTGEN의 sequence unrolling, self-attention에도 영향을 미침

- unrolled example에 대해, 모든 토큰들은 서로를 참조함 (attention 자체가 bi-directional 하기 때문)
- 각 unrolled example들이 독립적이기 때문에, example 별로 이전 position의 self-attentive representation이 새로 계산됨
( 각 unrolled case에 대해 unrolling 과정 중 하나씩 추가되는 [mask] token 이전의 self-attentive represetation이 새로 계산된다는 의미 ! ) - output이 하나의 stream으로 표현되고, shared self-attention을 거치며 encoding 되는 과정에서 multimodal & multilingual 한 모델로 이행하기 위해 inductive bias를 강화시킴
Target language specifiers
- generation 시 언어를 선택하기 위해 input sequence가 special target language specifiers로 시작됨
- special target language specifiers, task들을 관통하여 사용됨
( e.g., specifier [DE] : 독일어로 이미지 캡셔닝할 때, 독일어로 번역할 때 모두 사용됨 )
- special target language specifiers, task들을 관통하여 사용됨
Training & Hyperparameters
-
VL-BERT의 base configuration을 확장시킴
- 12개의 self-attention layers와 12개의 head로 구성된 Transformer
- model dimension = 768 / feed-forward dimension = 3072
-
hyperparameters
hyperparameter content optimizer AdamW base lr 1.3 X 10^-5 weight decay 10^-4 -
training
- positional embedding update
→ VL-BERT pre-training에서 다루지 못한 new positions 학습해야 하기 때문
- positional embedding update
-
final model
- ~89.3M parameters ( word embedding 제외 )
Decoding
- masked position 에 대해 most-likely prediction 추가
→ [mask] token 한칸씩 오른쪽으로 옮기면서 진행 - beam search 대신 greedy search 활용
→ self-attentive representation이 새로 계산되는 과정에서 너무 시간이 많이 소요될 수 있기 때문
Results and Findings
(MMT 위주로 리뷰할 예정)
Multimodal Machine Translation
-
Multi30K dataset 활용, EN↔DE & EN↔FR task에 대해 학습 ( test set, 2016 flickr set )
-
result

→ ( 논문 저술 당시 ) SOTA model 보다 성능 좋음 !
- adversarial evaluation
- image data가 모델 성능에 아무런 영향을 미치지 않은 것 아님 ?
→ {image, source text} mapping을 랜덤으로 섞어 image가 text에 상응하지 않도록 함
- BLEU 및 METEOR 점수에서 유의미한 하락. image feature가 제대로 활용되었음을 알 수 있음
- image data가 모델 성능에 아무런 영향을 미치지 않은 것 아님 ?
- zero-shot performance
- task에 대한 direction이 없는 zero-shot 상황에서도 모델 성능 좋음
→ 다른 MMT / NMT model들과 비교했을 때 월등한 zero-shot performance
- task에 대한 direction이 없는 zero-shot 상황에서도 모델 성능 좋음
- adversarial evaluation
-
+ a
- 기존 BERT 계열 모델들과 달리 BERTGEN, 특정 MT corpus에 fine-tuned 되지 않음
- 그럼에도 multi-lingual, multi-modal한 generation task 수행 가능
Conclusion
🤸🏻 generative, decoder-only model인 BERTGEN을 제안한다 !
- multimodal pre-trained model과 multilingual pre-trained model 융합
- 다양한 generative task에 쓰일 수 있고 일반화가 용이한 모델이다~
