
Calixto, I., Liu, Q., & Campbell, N. (2017). Incorporating global visual features into attention-based neural machine translation. arXiv preprint arXiv:1701.06521.
Abstract
- attention-based multi-modal Neural Machine Translation model들을 제안한다 !
- 세가지 모델을 제시할건데, encoder - decoder의 각기 다른 영역에서 visual features들이 통합됨 ~ → global image feature이 pre-trained CNN을 이용해서 추출되고
- src sentence의 단어와 통합되거나
- encoder hidden state을 initialize하는데 사용되거나
- decoder hidden state을 initialize하는데 사용되는 형태
- 어떤 방식이 가장 좋은 성능을 내는지 볼거임 !
- 세가지 모델을 제시할건데, encoder - decoder의 각기 다른 영역에서 visual features들이 통합됨 ~ → global image feature이 pre-trained CNN을 이용해서 추출되고
+ synthetic multi-modal, multilingual data(augmented data)가 multimodal model의 성능에 어떤 영향을 미치는지도 볼 것임
Introduction
- 본 논문의 main goal, 기존의 attention-based NMT 모델을 기반으로 visual features를 통합시키는 end-to-end MMT 모델의 구축
🤸🏻 Contributions
- encoder - decoder의 각기 다른 영역에서 visual features들이 통합되는 attention-based NMT 모델 구축
- synthetic multi-modal & multilingual data가 MMT 모델에 미치는 영향 탐구
- image가 NMT 모델에 유용한 정보로 작용한다는 점을 밝혔다 ~
Attention-based NMT
Text-only attention-based NMT
Problem Statement
NMT model, source sentence 와 그 번역문 이 주어졌을 때 를 학습함으로써 X를 Y로 번역하고자 함

Architecture
- encoder ; bidirectional RNN with GRU
-
forward RNN : src sequence를 순차적으로 읽어들이고 각 encoder time step별로 forward annotation vector () 생성
-
backward RNN : src sequence를 역방향으로 읽어들이고 각 encoder time step별로 backward annotation vector () 생성
-
마지막 annotation vector, forward annotation vector과 backward annotation vector을 통합한 형태
→ 결과적으로 각 src sentence, annotation vector의 sequence 로 encoded
-
- decoder ; 기존에 산출된 target word와 src sentence 기반, attention mechanism으로 계산
- 각 time step t에 대해 time-dependent context vector 계산
: annotation vectors , decoder의 이전 hidden state , 이전 time step에서 산출된 target word 기반으로 계산 - alignment model : single-layer feed-forward network으로 decoder의 time 에서의 정보가 encoder time 에서의 정보와 얼마나 연관성이 있는지 score을 계산
-
encoder time step 에서의 source annotation vector 과 decoder의 이전 hidden state 을 활용, expected alignment 계산
-
아래 수식을 거쳐 alignment score이 정규화되고 확률화 됨
( = 모델의 attention weights )
-
time-dependent context vector 계산
-
활용, decoder의 hidden state 계산
( = decoder의 이전 hidden state, = 이전 time step에 산출된 word embedding, = updated time-dependent context vector)
-
single-layer feed-forward network으로 decoder의 hidden state 초기화 + encoder의 forward RNN()과 backward RNN()의 마지막 hidden state를 융합한 값을 feed
( 모두 model parameters)
- RNN, 고질적인 장기의존성 문제 → decoder hidden state 초기화할 때 첫번째-마지막 토큰 representation을 강하게 강조하는 등의 방법을 쓰려고 한다 ~
-
- 각 time step t에 대해 time-dependent context vector 계산
Multi-modal NMT (MMT)
attention-based NMT framework의 연장선 + image feature을 통합하기 위해 visual component 추가
extracting image features
- pretrained VGG19 network에 image feed → image feature 추출
incorporating images into the attentive NMT framework ; 3 methods
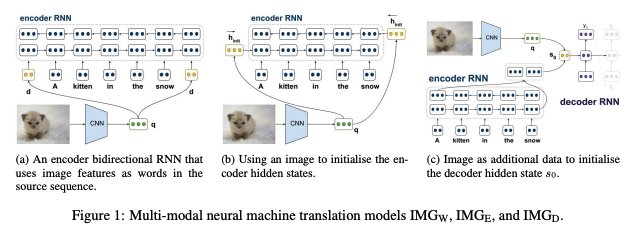
-
images as source words :
: using an image as words in the source sentence-
image를 문장의 첫번째 및/혹은 마지막 단어처럼 취급하여 model에 feed하고 attention model로 하여금 언제 image를 참고해야하는지 학습하도록 함
-
global image feature 에 대해,
( = image transformation matrices,
= bias vectors, = source words vector space dimensionality)
-
그렇게 산출된 d를 src word로 사용
- 첫번째 단어로만 취급하여 학습시키는 경우
- 첫번째, 그리고 마지막 단어로 취급하여 학습시키는 경우
-
intuition
- 이미지를 첫번째 단어 취급 → forward RNN을 적용시켰을 때 source sentence와 이미지 융합
- 이미지를 마지막 단어 취급 → backward RNN을 적용시켰을 때 source sentence와 이미지 융합
-
-
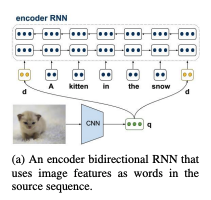
images for encoder initialization :
: using an image to initialize the source language encoder-
기존의 NMT model, encoder의 hidden state, zero vector로 초기화
→ 이 대신 두개의 새로운 single-layer feed-forward neural network로 forward RNN과 back RNN의 initial hidden state 계산하고자 함 -
global image feature 에 대해,
( = image transformation matrices,
= bias vectors, = source words vector space dimensionality)→ 단, 이 때 는 d를 encoder의 hidden state 차원과 맞춰줌
-
그렇게 계산된 d를 기반으로, 두 개의 새로운 single-layer feed-forward neural network로 forward RNN과 back RNN의 initial hidden state 계산
( = multimodal projection matrices : image feature d를 encoder의 forward hidden states 및 backward hidden states의 차원으로 변환해주는 역할, = bias vectors )
-
-
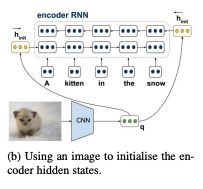
images for decoder initialization :
: using an image to initialize the target language decoder-
decoder hidden state initialization (originally)
: encoder의 forward RNN ()과 backward RNN ()의 마지막 hidden state () concat하는 방식
-
decoder hidden state initialization 시 image feature 추가
( = multimodal projection matrices : image feature d를 encoder의 forward hidden states 및 backward hidden states의 차원으로 변환해주는 역할 )
-
global image feature 에 대해,
( = image transformation matrices,
= bias vectors, = source words vector space dimensionality)→ 단, 이 때도 는 d를 decoder의 hidden state 차원과 맞춰줌
-
Dataset
- Flickr30K dataset → 30K images과 각 이미지 별 5개의 영문 description으로 이루어져 있음
- image split
( train : val : test = 29K : 1014 : 1K ) - 영문 description 변역한 dataset :
: 한 개의 영문 description을 전문 번역가가 독일어로 번역. 이미지 당 한 개의 EN:GR pair로 구성
: 영문 description과 독립적인 독일어 description 수집. 이미지 당 5개의 EN:GR pair로 구성
- image split
- Train 시 전체 training set 사용
- + 여분의 데이터가 모델에게 미치는 영향 연구하기 위해 NMT baseline model에 text 데이터만 feed해 번역기 학습 → 이를 back-translation에 활용 → text 데이터를 back-translation하여 데이터 증강 ( en → gr → en )
Experimental Setup
Setup
- model architecture
- encoder
- bidirectional RNN with GRU
( one 1024D single-layer forward RNN + one 1024D single-layer backward RNN )
- bidirectional RNN with GRU
- decoder
- RNN with GRU
( + attention mechanism )
- RNN with GRU
- encoder
- word embedding
- src word & tgt word 모두 620D
- dropout = 0.2
- image features
- pretrained VGG19 + penultimate fully-connected layer FC7
- dropout = 0.5
- hyperparameters
- optimizer = SGD with Adadelta
- batch size = 40
Result
multi30k
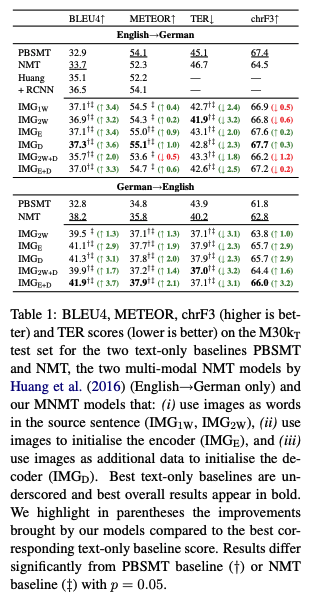
-
이외 모든 모델이 기존 MMT 모델보다 성능이 좋음
- encoder - decoder 모두에 image feature 융합하는 것이 생각보다 좋지 못한 성능을 냈다. encoder - decoder 중 하나에만 image feature 넣는 게 오히려 좋음
additional back-translated data
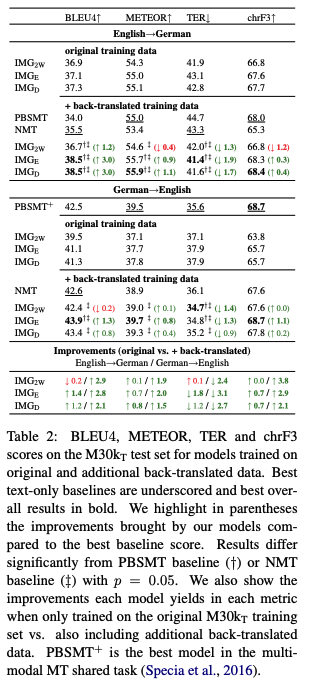
- back translation을 통해 증강된 데이터의 효용
- GR → EN : 모델 성능만 개선
- EN → GR : 모델 성능 개선
Conclusions
🤸🏻 (논문 저술 시점) SOTA NMT model에 이미지 정보를 통합해봤다 ~
- 기존 text-only 기계번역 모델보다 성능 좋더라 ~
- 이미지를 단어처럼 취급하는 방식()보다 encoder - decoder 단에서 통합하는 방식()이 성능 더 좋았다 ~
- 그렇다고 해서 encoder - decoder 모두에 image feature 융합하는 건() 또 성능이 별로임
- MMT model, back-translated data 쓰면 성능을 보다 개선시킬 수 있다 ~
