
Chen, S., Zeng, Y., Cao, D., & Lu, S. (2022). Vision talks: Visual relationship-enhanced transformer for video-guided machine translation. Expert Systems with Applications, 209, 118264.
Abstract
- 기존 연구, 번역 성능 향상을 위해 비디오 전체를 활용한 바 있는데, 이게 noise로 작용할 수 있음
- Visual relationship-enhanced transformer 제안
- modality 간 연결을 위해 semantic-visual relational graph 활용
- visual semantic 간 관계 포착을 위해 GCN 활용됨
- multi-modal fusion을 하는 Transformer가 영상과 텍스트의 관계 정립
Introduction
VMT ( Video-guided Machine Translation )
: 언어쌍 간의 정렬을 위해서 부수적인 시공간적 맥락을 활용
Prior Research
: machine translation에서 어떻게 해야 video를 잘 활용할 수 있을까?
- global video features를 사용
- frame 단위로 appearance / motion feature 추출
- attention mechanism의 활용
→ 부던한 노력들에도 video modality의 도입은 일련의 문제점들을 야기함
Possible Problems of Video Modality
- Redundancy of Visual Understanding
: video에는 object, action, scene 등 여러 정보가 포함되어있는데, src txt에 연관된 것은 그 중 소수임
→ video에서 불필요한 부분을 줄이고 src sentence와 연관된 부분을 강조하는 것이 중요 - Confusion of Multi-modal Fusion
: 다양한 modality 간 fusion하는 방식에 따라 성능이 달라짐
→ 어떻게 fuse할 것 인가 ? 가 관건
Video의 structured conceptual representation = scene graph, 해당 문제들을 해결할 수 있음 !
-
graph의 형태로 표현되는 video 내 object들과 그들 간 관계, video 내의 key information을 충분히 드러낼 수 있음
→ video 내의 불필요한 정보를 걸러낼 수 있음 -
노드 간 dynamic한 관계, video의 dynamics와 닮아있음
-
graph는 textual label을 통해 연결되어있음
→ src text와 같은 modality이기에 multi-modal representation 간 간극이 보다 좁혀질 수 있음
→ scene graph를 통한 video와 source sentence의 key information 융합 제안
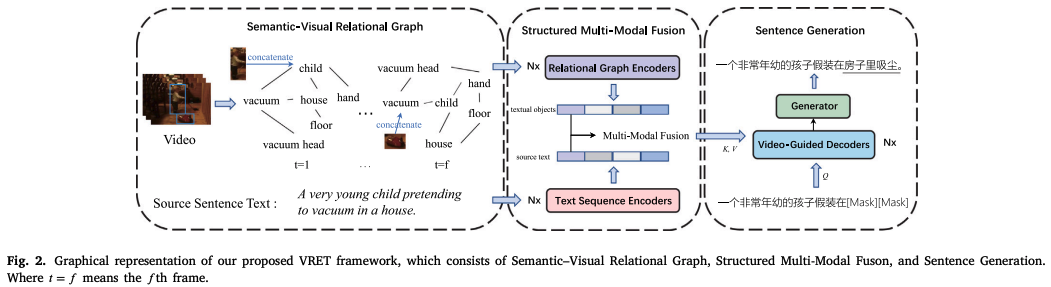
VRET ( Visual Relationship-Enhanced Transformer )
Three Modules
-
Semantic-Visual Relational Graph
a. video semantics를 visual → textual 형식으로 간결하게 추출
b. graph message propagation을 위해 object visual features를 통합
c. GCN으로 features들 간의 관계 파악 -
Structured Multi-Modal Fusion
a. multi-head residual attention → video objects와 src txt ( cross-modal information ) 융합 -
Sentence Generation
a. transformer decoder
b. fused context feature를 tgt text로 변역
Contribution
-
video 내 object를 detect하고 detect된 visual object 간 관계 파악
→ 보다 포괄적이고 간결한 visual content 추출 가능 -
visual relationship-enhanced transformer(w/ structured multimodal fusion strategy) 제안
→ modality간 의미적 연관성 제고. visual - textual modality, 적합하게 융합됨
Visual Relationship-Enhanced Networks
Preliminaries
Problem Statement
: 개의 단어로 구성된 source language sentence , source language sentence를 묘사하는 video clip 가 있다고 할 때,
기본적으로 src language sentence 을 개의 단어로 구성된 corresponding tgt language sentence 로 번역하는 task라는 점에서 기존의 machine translation과 동일하나, video 정보 가 추가된다는 점에서 차별성
Semantic-visual relational graph
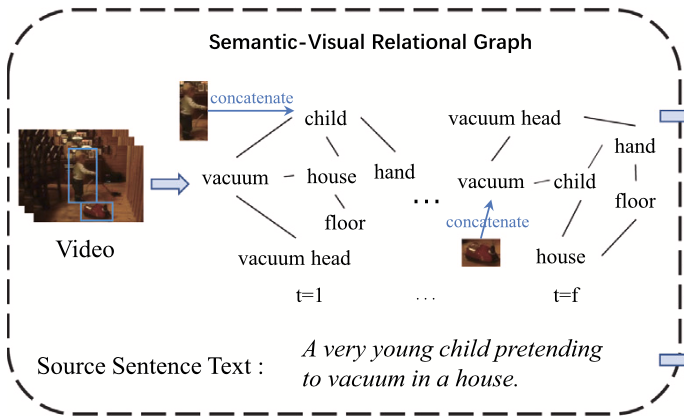
: video semantic을 visual data에서 textual data로 전환
-
objects와 그들의 relationship 포함
-
이후 graph message propagation 위해 object visual feature 통합됨
→ video 전체 정보를 cover -
Semantic-visual relational graph
-
각 frame의 objects, object labels, object relationships로 구성
- = 각 frame
- = 번째 frame의 i, j번째 구역 ( objects )
- = 에 대응하는 label
- = 간 시각적 관계
-
object 와 object label 얻기 위해서 object feature extractor (masked R-CNN 기반) 활용
- object , 4096-D vector로 represented
- object label , 300-D glove vector로 represented
-
각 frame의 visual relationship 을 추출해내기 위해서 scene graph generation이 사용됨
→ k개의 노드에 대한 edge들 생성
-
Structured multi-modal fusion
-
Semantic-visual relational graph의 textual objects feature를 video modality의 structured conceptual representation으로 간주 → video modality 와 text modality 간 간극 ↓
-
textual objects feature (video)과 source text feature (text)이 융합됨
→ GCN + positional encoding 기반의 relational graph encoder 제시 + multi-modal fusion 단계 구축
text sequence encoder

-
encoding layer, 토큰들의 sequence 를 feature representation 로 매핑
-
구조
a. token-level learned embedding
b. fixed positional encoding layer
c. stack of N identical layers : self-attention module과 fully-connected feed-forward network (2개의 sublayer가 residual connection으로 연결, layernorm 수행)으로 구성
relational graph encoders
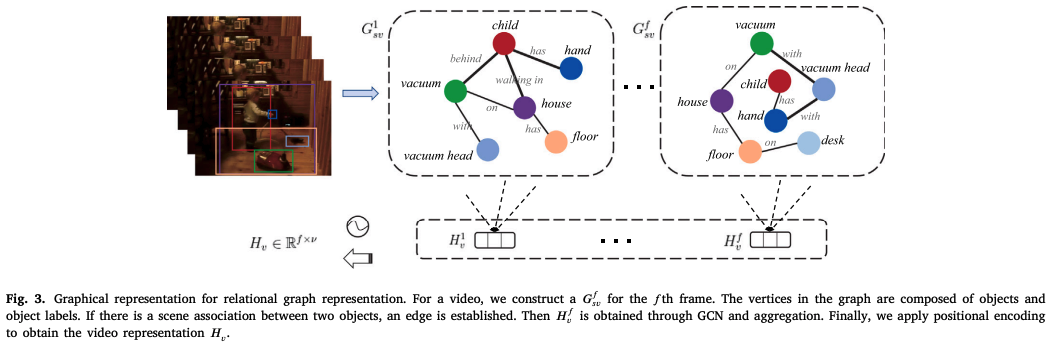
video representation 의 생성
-
각 video segment, f개의 frame으로 구성
semantic-visual relational graph 생성 이후cf. ; (= frame f에 해당하는 nodes(object labels)) 간 관계 나타냄
-
Positional encoding
: video frame들의 순차적인 정보를 얻기 위해 positional encoding 수행 -
N개의 spatial graph convolution layer을 통해 각 frame에 있는 object 간 공간적 관계를 얻음
( = f번째 frame의 l번째 layer의 노드 representation, = f번째 frame의 l번째 layer의 가중치 matrix, = f번째 그래프의 degree matrix , = f번째 그래프의 adjacency matrix )
-
Averaging Operation
: f번째 frame의 각 노드의 feature들을 통합하기 위함 → 각 feature가 하나의 feature vector 로 represented -
시간적 정보를 얻기 위해 각 frame에 대한 positional embedding 적용
: video representation 얻음( k = 의 길이, = j번째 graph의 i번째 노드 feature, = 의 형태 matrix로의 병합 )
Encoder
-
N-layer stacked encoders
-
self-attention module
-
connection module (w/ residual connection)
-
normalization layer
( = n번째 encoder layer의 self-attention module, = parameter matrices )
→ 일련의 과정을 통해 video에서 textual objects representation 추출 가능
multi-modal fusion
: 서로 다른 modality 간 상호연관성을 구축하기 위해 multi-modal fusion 수행
→ Scaled Dot-Product Attention 활용
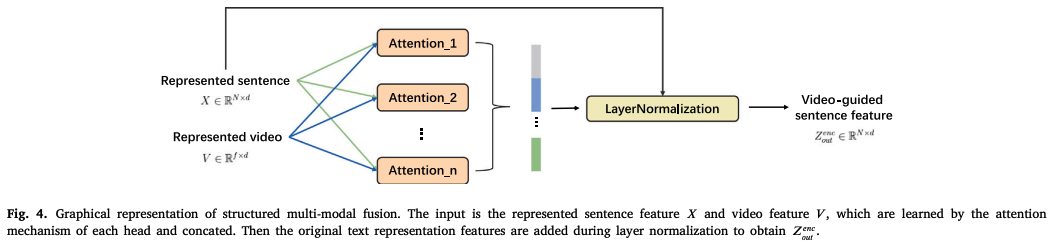
- input으로 sentence feature X 와 video feature V가 들어감
: 각 단어 에 대해 video features 에 대한 attention weights 계산( = layer-specific trainable parameter matrices )
+ 으로 두 개의 modality에 대한 feature 융합
-
residual network으로 와 융합
: original text feature이 없어지는 것 + 기울기 소실 방지 -
layernorm
: fused matrix 도출
Sentence generation
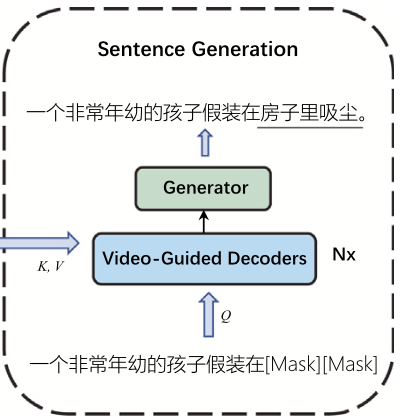
: video guided decoders + generator로 구성
→ fused matrix 으로 학습 ↣ target language sentence 생성하는 역할
-
video guided decoders
process
- video-guided sentence feature와 target text feature 간의 잠재적 의미관계 찾음
- positional encoding과 N-layer stacked coding layer로 output sequence 생성
: 과 offset target sequence 이 주어졌을 때 positional layer + decoding layer을 통해 output sequence 도출
decoder layer
: 하나의 decoder, 3개의 sub-layers로 구성.
각 sub-layer는 residual connection + layernorm으로 연결되어있음- self-attention module
- multi-head attention module
- fully connected feed-forward network
- 각 decoder layer, offset target sequence 에 대한 sequential representation 에 대해 self-attention
- Multimodal fusion과 target language sentence representation 융합을 위해 multi-head attention network 활용
-
generator
-
linear layer + softmax function으로 예측
-
inference 시
a. validation → greedy search ( 전체 문장 예측 )
b. test → beam search ( + token-level decoding )
-
Results
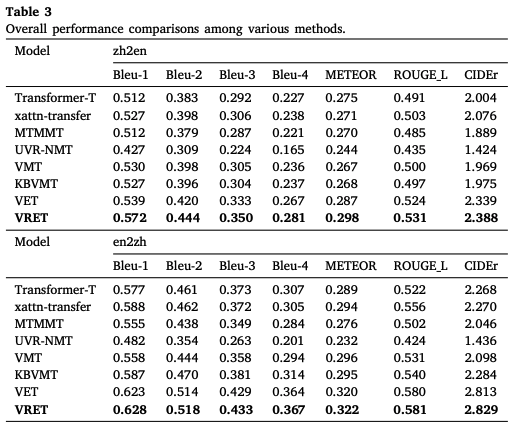
- (논문 저술 시점) SOTA !
- VRET, video의 불필요한 정보 제대로 걸러내고 txt-video 간 의미관계를 잘 반영해냄 !
- graph 활용하는 방식, 좋은 multimodal fusion method이다 !
Conclusion
- VMT에서의 visual relationship-enhanced transformer network 제안 !
- global video / keyframe 쓰는 방식 대신 semantic–visual relational graph 사용하는 방식 채택
→ 좋은 multimodal fusion 방식 !
- global video / keyframe 쓰는 방식 대신 semantic–visual relational graph 사용하는 방식 채택
