[Paper Review] Multi-Task Deep Neural Networks for Natural Language Understanding
Introduction
텍스트를 벡터로 표현하는 Language Representation은 natural language understanding(NLU) task에 필수 요소입니다. NLU task를 수행을 위해 multi-task learning, language model pre-training 두 가지 접근 법이 주목할만 합니다. 해당 논문에서는 두 개의 접근 법을 결합하여 MT-DNN을 제안하는 것이 목적입니다.
Multi-Task Learning(MTL)
MTL은 여러 supervised task를 결합하여 하나의 모델에 모두 학습시키는 것입니다.
‘인간이 과거에 task를 수행하기 위해 배웠던 지식이 새로운 task를 수행할 때 도움이 될 것’이라는 생각으로부터 영감을 받았습니다. Representation learning에 MTL의 적용은 두 가지의 장점이 있습니다.
- Deep Neural Network의 supervised learning은 대량의 task-specific labeled 데이터가 필요한데, 비슷한 다른 task를 결합함으로써 모델이 여러 task에 걸친 데이터 셋에 대해 학습하므로 비교적 많은 데이터 셋을 확보할 수 있음
- 특정 task에 과적합을 방지할 수 있어, Regularization 효과가 있음
Language Model Pre-training
많은 양의 unlabeled 데이터를 unsupervised objectives를 사용하여 보편적인 language representation를 학습한 모델을 만드는 것입니다. 이후 NLU 여러 task에 맞게 fine-tune하여 task를 수행합니다. 대표적으로 ELMo, GPT, BERT 등이 있습니다.
저자들은 MTL과 Language Model Pre-training을 결합하여 text representation의 학습을 향상시키고 다양한 NLU task의 성능을 높이고자 합니다.
Tasks
MT-DNN 모델은 아래 4개 유형의 NLU task를 결합합니다.
- Single-Sentence Classification
- 문장이 주어지면, 모델이 사전에 학습한 class 중 하나로 분류하는 task
- CoLA: English 문장이 문법적으로 맞는지 판단
- SST-2: 영화 리뷰에 대해 긍, 부정 감성 판단
- Text Similarity
- 한 쌍의 문장이 주어지면, 모델은 두 문장 사이의 의미적 유사성을 scoring
- STS-B
- Pairwise Text Classification
- 한 쌍의 문장이 주어지면, 모델은 사전에 정의된 라벨 모음을 기반으로 두 문장의 관계 결정
- RTE, MNLI: 두 문장의 의미적 관계를 entailment, contradiction, neutral 중 하나로 판단
- QQP, MRPC: 두 문장이 의미적으로 같은지 판단
- Relevance Ranking
- Query와 answer 선택지가 주어지면, 모델은 모든 answer에 대해 query와 관련된 순서대로 ranking
- QNLI: 주어진 query에 answer가 맞는지에 대해 평가하는 task → 해당 연구에서는 모델이 query와 각 answer간 pairwise ranking task로 변환
The Proposed MT-DNN Model
MT-DNN 모델의 아키텍처입니다.
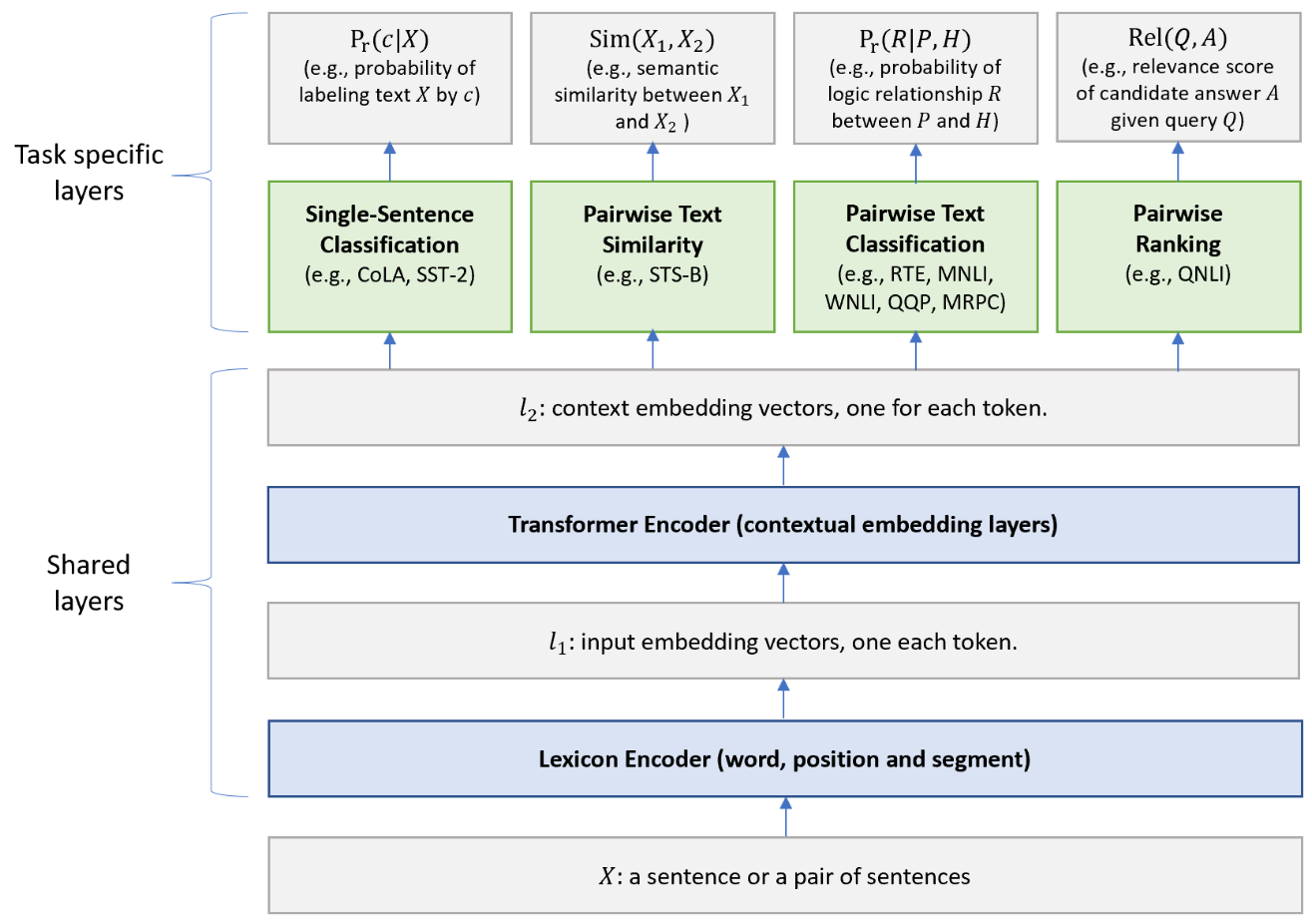
아래 부분은 모든 task에서 공통으로 사용되는 “shared layers”이고, 윗 부분은 각 task에 맞도록 결과를 출력하는 “task-specific layers”이다.
Lexicon Encoder ()
Lexicon encoder는 입력 문장을 토큰화한 뒤, 각 토큰을 벡터 공간에 임베딩하는 역할을 합니다.
- token embedding
- 첫 번째 토큰 은 항상 [CLS] 토큰으로, 분류를 위한 토큰임
- 문장 쌍 가 입력된다면, 두 문장은 special 토큰 [SEP]로 나눠서 입력
- position embedding
- 문장을 토큰화했기 때문에, 각 토큰의 문장 내 위치 정보를 표현
- segment embedding
- 문장 쌍으로 입력되었을 경우, 1번째 or 2번째 문장을 표현
Transformer Encoder ()
BERT와 동일하게 mulit-layer bidirectional Transformer encoder를 사용합니다. Transformer의 Self-Attention으로 문장 내 관계 정보를 반영하여 문맥정보가 담긴 임베딩 벡터를 생성합니다. 특히 MT-DNN은 여러 task에 대해 학습을 수행할 때, shared layers는 다양한 representation을 학습할 수 있게 됩니다.
Single-Sentence Classification Output
첫 번째 토큰인 [CLS]를 활용하여 입력된 문장을 분류합니다.

Text Similarity Output
[CLS] 토큰을 활용하여 문장 쌍의 유사성 score를 계산합니다.
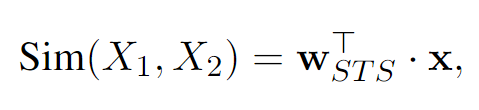
Pairwise Text Classification Output
하나의 문장 쌍(hypothesis, premise) 간에 의미 관계를 분류합니다. 해당 논문에서는 이를 위해 Stochastic Answer Network(SAN)을 사용합니다. SAN은 Multi-step reasoning을 통해 관계를 유추하는데, 입력 값들을 순차적으로 받으며 예측을 수정해나갑니다.
SAN을 사용하기에 앞서 입력 값으로 문장 H(hypothesis)와 P(premise)에 대해 transformer encoder 를 통해 연산된 embedding 값을 사용합니다. 아래 수식의 와 입니다.
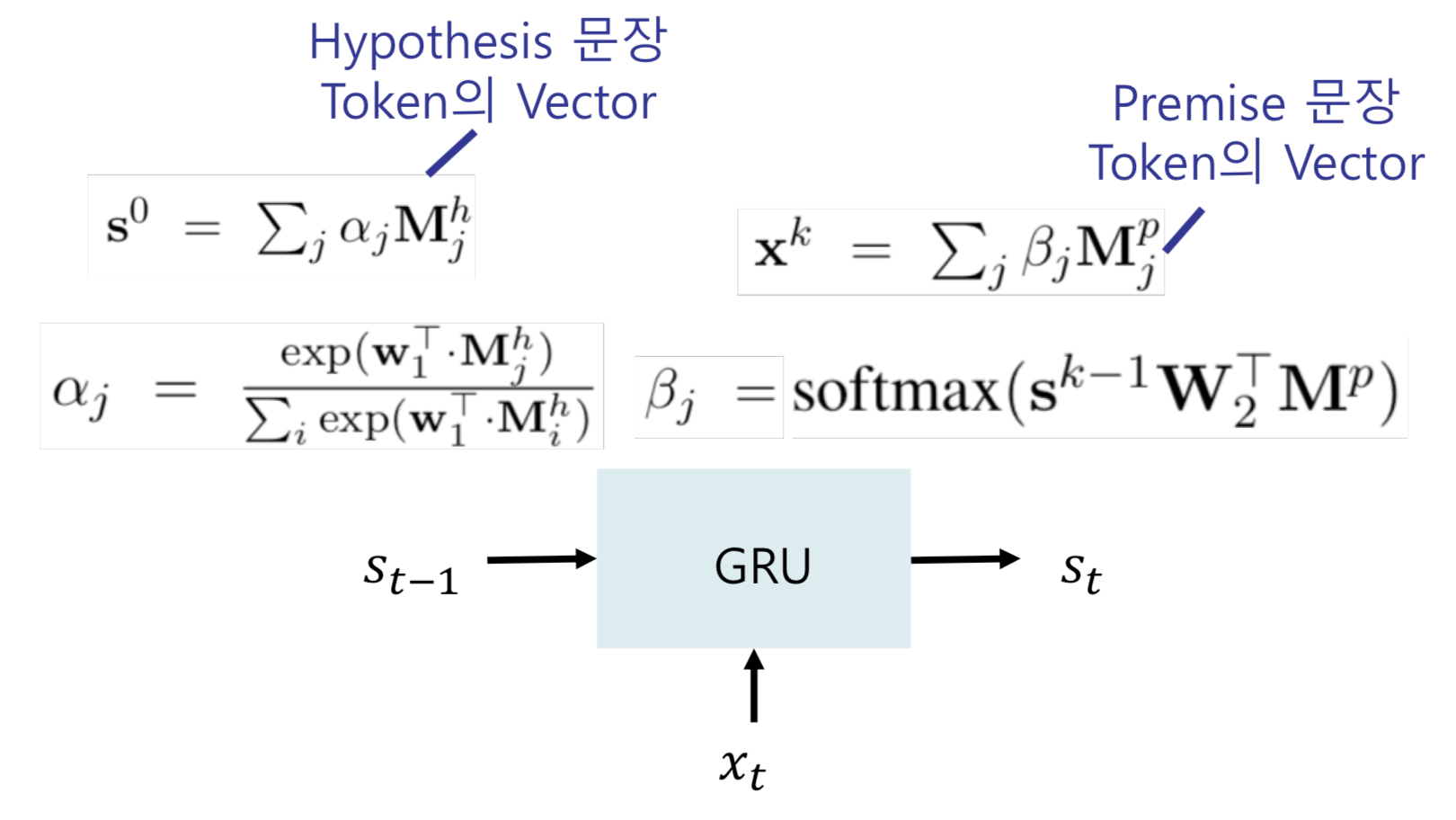
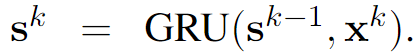
- Cell의 Input은 , hidden state는 를 받아 연산함
- 같은 방식으로 K번의 time step의 분류를 예측함
각 time step에서 분류 예측은 아래 식을 통해 진행됩니다.
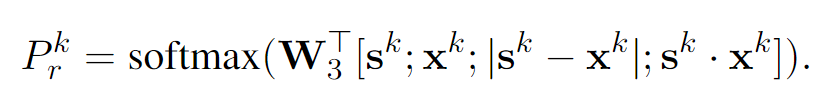
- 두 문장 각각의 embedding 벡터, 두 문장 간 거리(차의 크기)와 similarity(내적)을 결합하여 구성된 벡터를 가지고 분류
K번의 multi-step reasoning을 통해 예측했다면, 아래 식과 같이 K번의 결과들을 평균내어 최종 결과를 예측합니다.
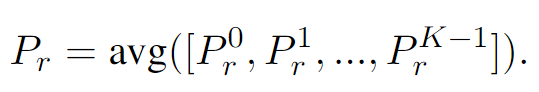
Relevance Ranking Output
Question과 Answer 문장을 하나씩 relevance score를 아래 식과 같이 계산하고, 가장 높은 점수를 보이는 answer가 주어진 question과 관련이 있다고 판단합니다.
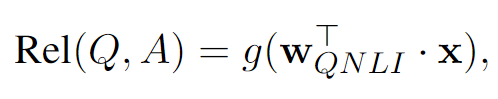
The Training Procedure
MT-DNN은 pretraining과 multi-task learning 두 단계의 training을 수행합니다.
Pretraining 단계에서는 MLM, NSP 두 개의 unsupervised objectives를 사용하여 Lexicon encoder와 Transformer encoder의 파라미터를 학습시킵니다(BERT와 동일).
Multi-task learning 단계에서는 mini-batch SGD를 사용하여 shared layers, task-specific layers의 파라미터를 학습시킵니다. 각 epoch에서 mini-batch는 9개의 GLUE task 중 무작위로 하나의 task를 선택하고 해당 데이터셋으로 구성한 뒤, 학습을 수행합니다.

추가로 본문에 classification, similarity, relevance ranking task별 MTL 학습에 사용된 objectives도 제시되어 있습니다.
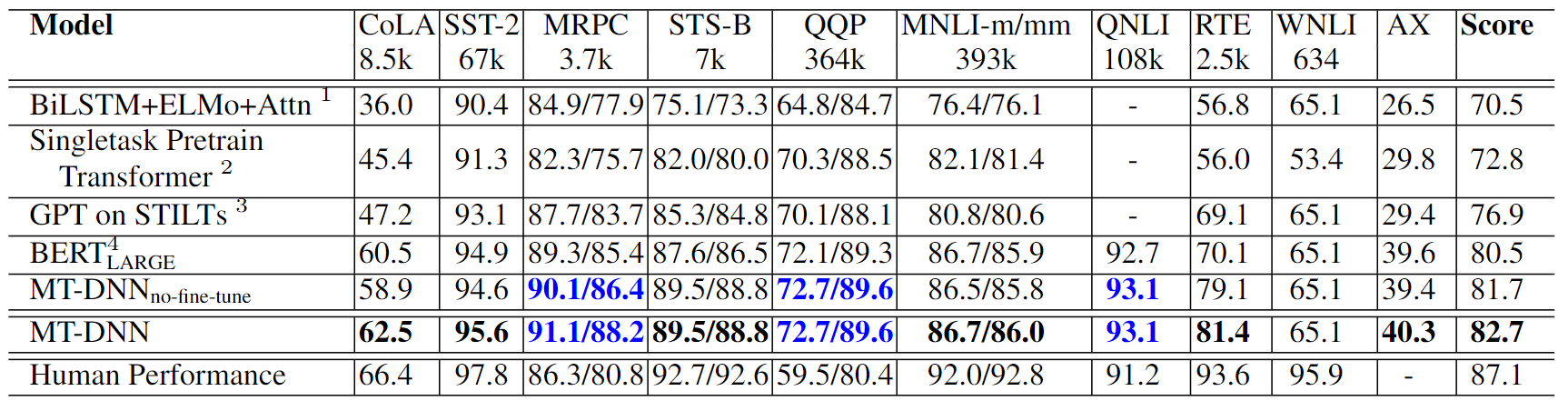
GLUE Main Results
GLUE에 대한 성능 결과(Accuracy/F1-score)입니다.
- MT-DNN
- 사전학습된 BERT_LARGE 모델을 초기 shared layers로 사용하고, MTL을 통해 2차 학습한 뒤 각 GLUE task에 대해 fine-tuning
- 9개의 task 중 8개의 task에서 SOTA 달성
- MRPC, RTE 등 데이터 셋이 적은 경우에 더 높은 성능 향상을 보여줌
- MTL을 통한 shared layer 학습이 효과가 있음을 입증

- ST-DNN
- 사전학습된 BERT 모델을 shared layers로 사용하지만 MTL을 통해 2차 학습은 수행하지 않음
- BERT와 달리, pairwise text 분류 task에서 출력 모듈을 다르게 설정(SAN, Relevance ranking)
- MNLI, QQP, MRPC, RTE를 SAN을 적용한 task인데, 기존의 BERT_LARGE보다 큰 성능 향상이 없음
- QNLI는 Relevance Ranking으로 변환하여 실험했었는데, 기존 BERT보다 큰 성능 향상을 보여주었음 → Query와 모든 문장에 대해 쌍으로 결과를 예측하고 점수를 scoring하기 때문
Domain Adaptation Results on SNLI and SciTail
GLUE와 동일하게 이번에는 SNLI, SciTail task에 MT-DNN을 적용했을 경우의 성능을 측정해 보았습니다. Training 데이터를 0.1%, 1%, 10%, 100%로 바꿔보며 실험을 수행했습니다.
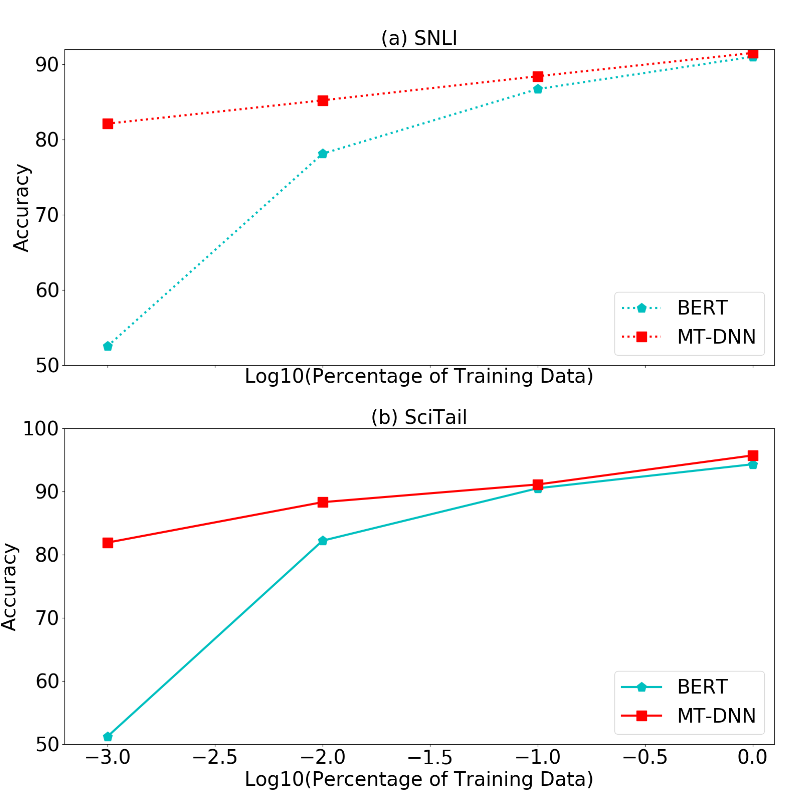
- MT-DNN이 BERT보다 더 높은 성능을 보여줌
- 특히 MT-DNN은 작은 양의 training 데이터로도 높은 성능을 보여줌 → MT-DNN을 통한 학습이 도메인 적응을 더 효과적으로 수행함을 의미
각 task 도메인의 모든 학습 데이터를 사용하여, 이전의 모델들과 성능을 비교해보았습니다.
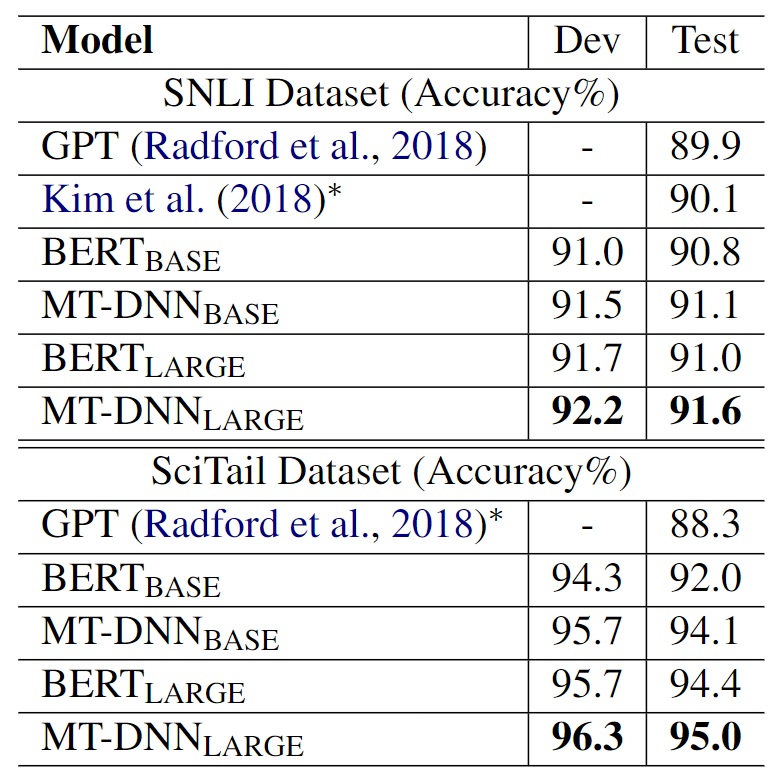
- MT-DNN_LARGE 모델이 SOTA 달성
- MT-DNN이 도메인 적응에 효과적인 성능을 보여준다는 것을 입증 !
Conclusion
- Multi-task learning과 Language model pre-training의 장점을 결합
- MT-DNN은 도메인 적응에 효과적인 것으로 나타남
Opinion
- 성능향상이 비약적으로 증가하진 않은 점이 아쉬움
- 데이터가 상대적으로 부족할 때 성능향상을 어떻게 이끌어낼지, 처음 영감받은 아이디어가 인상적이었음 ('스키를 잘 타는 사람은 스케이트도 잘 탈 것이다')
Reference)
[MT-DNN 논문 Review] Multi-Task Deep Neural Networks for Natural Language Understanding
