Introduction
지난 10년 간, 비전 인식 task는 SIFT 혹은 HOG를 사용하여 수행되었다. 이후 역전파를 통한 SGD 학습 방법이 등장하면서 Convolutional neural network를 효과적으로 학습할 수 있게 되었다.
당시의 CNN을 통한 ImageNet 좋은 분류 성능을 PASCAL VOC 객체 감지에 어떻게 연결지을지가 고민이었고, 저자들은 CNN을 사용해 객체 감지를 시도했다. Deep network로 object를 localization하고, 적은 양의 label 데이터로 모델을 학습시킨다.
본 논문에서는 recognition using regions를 통해 CNN의 localization 문제를 해결한다. 입력받은 이미지에 대해 약 2000개의 region proposal을 생성하고 CNN으로 보내 feature를 추출한 뒤, SVM을 통해 영역을 분류한다. 다만, CNN은 고정 길이의 이미지만 받을 수 있기 때문에, affine image warping을 사용한다.
Object detection task의 경우 labeled된 데이터가 부족할 때의 문제를 해결하기 위해, 대규모 ILSVRC 데이터 셋에 대해 supervised 학습을 수행한 뒤, 도메인에 해당하는 소규모 PASCAL 데이터 셋을 fine-tune한다.
논문에서 제시한 핵심 아이디어만 간략하게 정리해봅니다.
Object detection with R-CNN
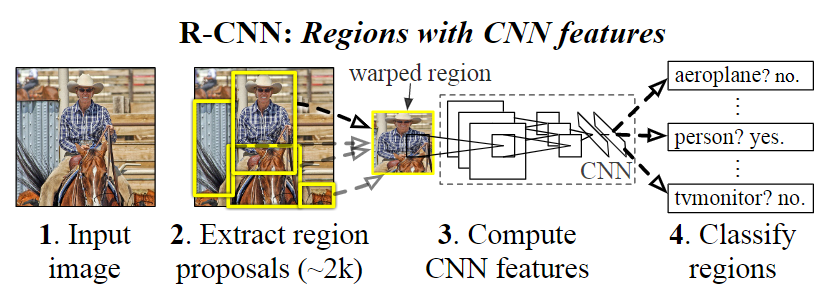
제안하는 Object detection은 3개의 과정으로 이루어진다.
- category-independent region proposals 를 생성
- CNN을 통한 feature 추출
- class별 선형 SVM을 통한 분류
아래 그림을 통해 직관적으로 이해할 수 있다.
Region proposals.

R-CNN에서는 selective search를 사용하여 입력된 이미지에 대해 object가 있을 만한 후보군들을 뽑아낸다. Selective Search는 입력된 이미지에 대해 segmentation을 수행 (seed 설정 개수만큼)한 뒤, 후보군들을 적절하게 통합하여 object가 있을만한 부분들을 제안하는 알고리즘이다.
Feature extraction
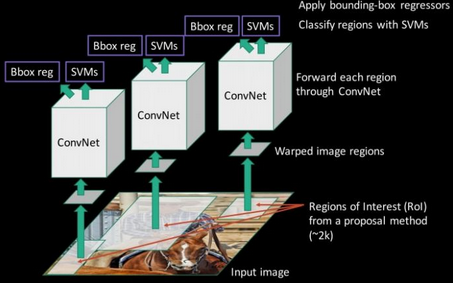
저자들은 CNN을 사용하여 4096차원의 feature vector를 추출한다. CNN은 5개의 conv layer와 2개의 fc layer로 구성되고, 227x227 크기의 이미지를 입력받는다.

CNN의 입력 이미지 크기가 정해져 있기 때문에, region proposal로부터 제안된 이미지들을 변환해주어야 한다. 이를 위해 bounding box 내 이미지의 모든 픽셀들을 227x227크기로 warp한다. 위의 그림은 warped된 이미지의 예시들이다.
Test-time detection
test-time에서 제안된 R-CNN이 어떻게 object detection을 수행하는지에 대해 간략히 설명한다.
- 입력된 이미지에 대해 selective search를 사용하여 약 2000개의 region proposals를 추출
- CNN에 입력하기 위해 region proposals를 warp 수행
- CNN(AlexNet사용) 연산을 통해 features 추출
- 클래스를 분류하도록 훈련된 SVM을 사용하여 추출된 features를 채점
- 여러 bounding box들의 겹치는 정도 IoU(0.5 사용)를 계산하여, 0.5보다 크면 동일한 물체를 대상으로 한 박스로 판단(non-Maximum suppression)
Non-Maximum Suppression

약 2000개의 region proposals를 추출해 feature를 계산하고 점수를 얻었지만, 동일한 물체에 대해 여러 중복되는 box들이 존재할 것이다. non-maximum suppression은 겹치는 정도를 계산하여 가장 많이 겹치는 박스를 남기고 제거하는 것이다.
Training
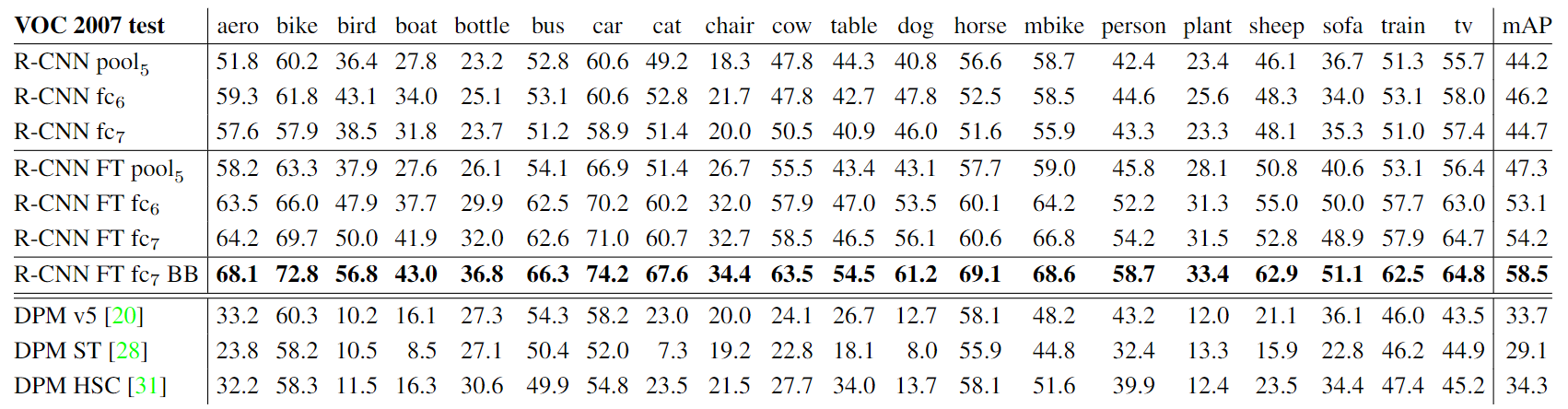
저자들은 도메인에 해당하는 데이터셋에 대해 fine-tune을 적용 여부에 따라서, bounding-box regression의 적용 여부에 따라 실험을 수행해보았다.
- ImageNet으로 사전학습된 CNN만 사용한 것보다, 추가적으로 object detection 데이터 셋으로 fine-tune한 것이 더 좋은 성능을 보임(FT=fine-tuning)
- Bounding-box Regression을 적용한 것이 가장 좋은 성능을 보임
Bounding-box Regression
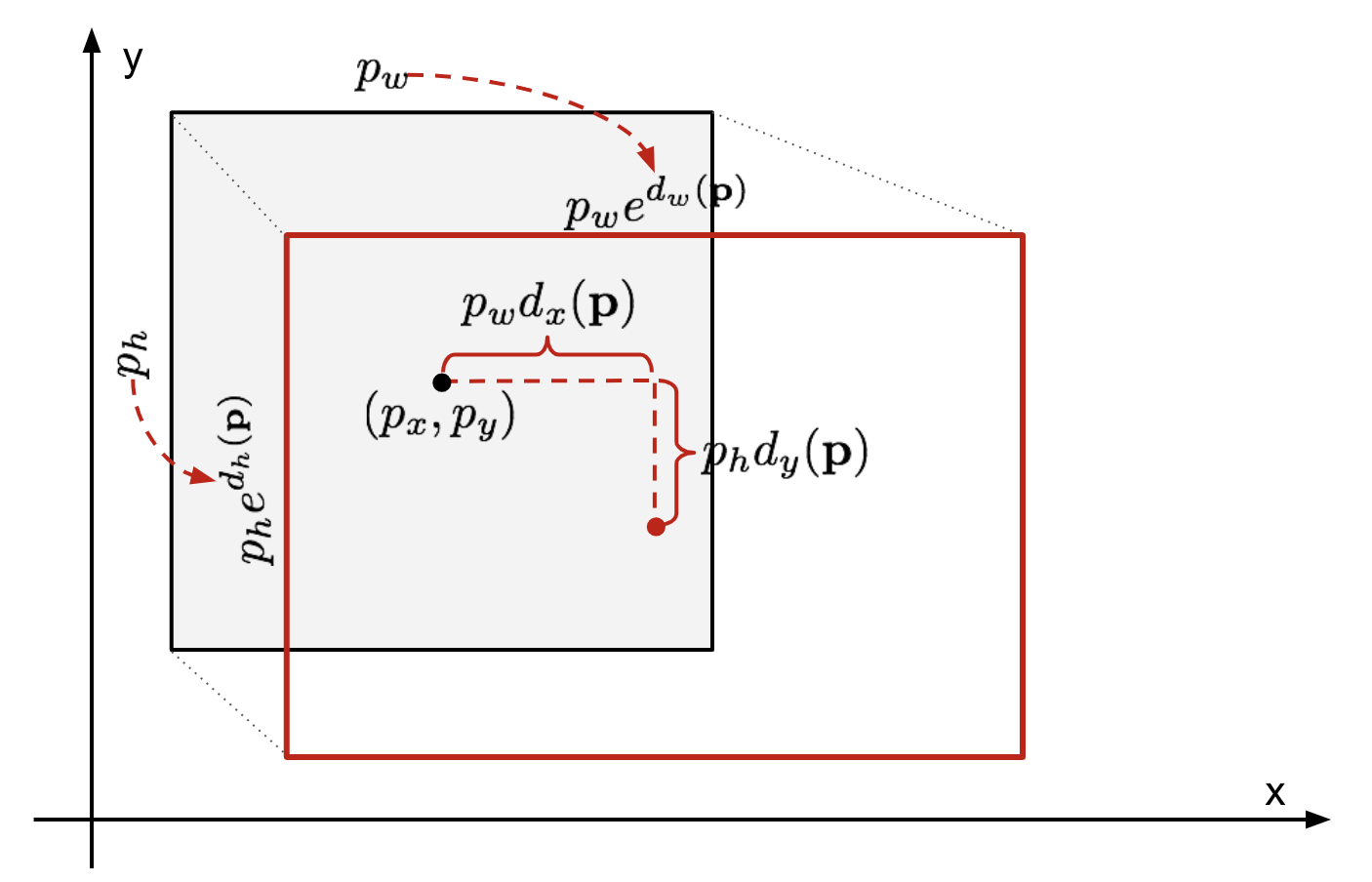
저자들은 selective search를 통해 bounding-box를 제안했었는데요. 부정확하다는 단점이 있어 성능을 올리기 위해 bounding-box의 위치를 조정해주는 과정을 추가했다.
- selective search로 추출한 region proposal과 정답 label bounding-box와의 차이를 줄이기 위한 regression 수행
수식을 통해 살펴보자면, 먼저 region proposal을 통해 추출된 부분이 P이고, Ground truth에 해당하는 부분이 G라고 한다. 이때 는 이미지의 중심점, 는 너비와 높이이다.
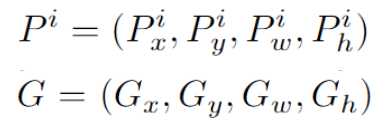
추출된 부분 P를 정답 label인 G에 맞도록 이동시킨다.
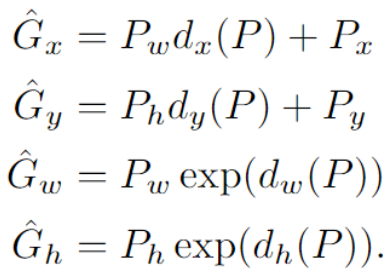
여기서 는 학습을 통해 얻고자 하는 함수이고, 학습을 위해 weight를 주어 계산한다. 다만, bounding-box regression은 CNN의 pooling layer5에서 나온 벡터를 사용한다.
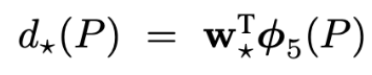
이후 아래의 식과 같이 손실함수를 정의한다. MSE 함수에 L2 normalization을 추가한 형태라고 한다.
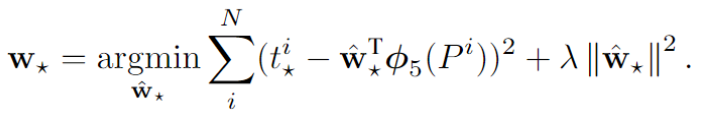
는 P와 G사이의 차이를 의미하고, 차이를 계속 줄여나가야 한다.
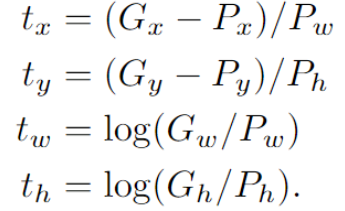
CNN을 이용해 이미지 내에 있는 여러 물체에 대해 object detection을 수행한다는 점이 장점이다. 본 논문은 신경망을 활용하여 object detection을 수행하고, object의 위치가 labeled된 데이터 셋이 적을 경우에도 높은 성능을 내는 것에 초점을 맞추고 연구를 수행했다.
다만, selective search 알고리즘은 cpu를 사용하여 연산하고 추출된 region proposal의 CNN연산만 gpu를 사용해 학습하기 때문에 속도가 느리다는 단점이 존재한다. 또한, SVM과 bounding-box regression은 각각 input이 feature map from CNN, region proposal로 서로 다른 input을 가지고 학습하므로, end-to-end로 학습할 수 없다.
추가로 R-CNN에서 학습이 일어나는 곳은 CNN, SVM, Bounding-box regression만 학습된다.
