Athena란?
aws의 athena는 s3 버켓에 들어있는는 데이터들을 S3 자체를 DB로 취급하여 쿼리문을 작성하고 실행시켜주는 명령 전달, 데이터 읽기 및 가공의 일을 Athena에서 처리해줍니다.
Hive 기반으로 작동합니다.
Athena 동작 방법
Athena의 데이터베이스
개발자가 검색을 원하는 버켓을 지정한 table들의 집합을 athena에서는 데이터베이스라고 한다.
Athena의 테이블
Athena는 쿼리를 실행할 때 스키마가 사용자의 데이터에 프로젝션 됩니다. 따라서 데이터를 로드하거나 변경할 필요가 없습니다.
테이블을 생성할 때는 반드시 LOCATION절을 고려해야합니다. Athena와 같은 버전의 S3버켓의 데이터만 로드 할 수 있습니다. 이전 버전의 데이터는 쿼리할 수 없습니다.
Athena는 S3버켓의 데이터를 로드하고 읽기가 가능한 적절한 권한이 필요합니다. 또한 객체가 많은 S3버켓에서는 데이터를 분활시켜야 합니다 분할 시키지 않으면 쿼리를 실행할 때 마다 많은 데이터를 검사해야 하기 때문에 성능이 떨어집니다.
Athena의 테이블의 이름과 테이블 열 이름은 반드시 소문자여야 합니다.
Athena 쿼리 동작
Athena에서 데이블을 분할해서 생성해야 합니다. 분할되지 않는 테이블에 대해서는 SQL 쿼리를 실행할 때 LOCATION 하위에 모든 파일을 스캔합니다. 그러나 분할된 테이블을 쿼리할 때는 AWS Glue 파티션 정보가 있는 데이터
Athena 파티셔닝
S3 버켓에 url 네이밍을 //s3:kongservice.com/kongplace/dynamoDB/key=value
이렇게 생성하고 나중에 athena에서 테이블을 생성할 때 파티션 키를 key로 해주고 value값을 url상의 value값으로 넣어주면 차후 파티션 값을 자동으로 등록해서 사용 할 수 있다.
파티션 설정 방법
athena sql querry
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/create-table.html
athena query by python
lambda에서 spring에서 전달 받은 날짜를 기준으로 쿼리를 생성한다. createNamedQuery
생성한 쿼리 아이디를 통해서 get_results를 수행 -> 원하는 결과 얻기 가능
Athena를 Lambda에서 수행하기 위해서 필요한 권한
- s3 접근 권한
- athena 접근 권한
Athena를 수행하는 순서
- Athena에서 수행하길 원하는 쿼리를 생성한다. By start_query_execution
- return 생성한 쿼리의 ID : QueryExecutionId
- 생성한 쿼리로 조회를 실행한다. By get_query_execution
- return 1단계에서 생성한 쿼리 ID: QueryExecutionId를 통해서 쿼리문을 실행한다.
- 수행이 완료되면 지정한 S3 버켓에 지정한 위치에 쿼리 결과가 CVS 형식으로 생성된다.
- 쿼리 결과를 수행한 쿼리 ID: QueryExecutionId 로 조회한다. By get_query_results
Athena 성능 이슈
Athena는 대용량 데이터 조회에서 사용되고 실시간 서비스에서 사용은 지양 된다. 이유는 Athena 쿼리 동작 방식 때문에 그렇다.
Athena 쿼리의 동작 방식은 다음과 같이 진행된다.
-
원하는 쿼리를 생성한다, 생성과 동시에 쿼리 결과가 S3에 저장된다
-
생성된 쿼리 결과 ID로 결과 상태를 조회한다. 'QUEUE', 'RUNNING', 'SUCCESSED', 'FAILED'
-
2번에서 작업한 결과가 SUCCESSED 인지 검사하고 일치하면 1번에서 생성한 쿼리 ID를 기반으로 결과를 가져온다. 이때 상태가 SUCCESSED인지 계속해서 검사해줘야 한다.
수행결과 11만건의 데이터를 조회하고 가져온느데 2s 정도가 소요된다. 시간 소요의 비중은 2번째 단계에서 80%가 소요된다.
따라서 Athena는 실시간으로 사용하기에는 성능상 문제가 있다. 하지만 조건만 맞다면 쉽게 S3 데이터를 조회가 가능하기에 여전히 매력적인 기술이다.
모든 동작을 수행 했을 때 1,2,3단계
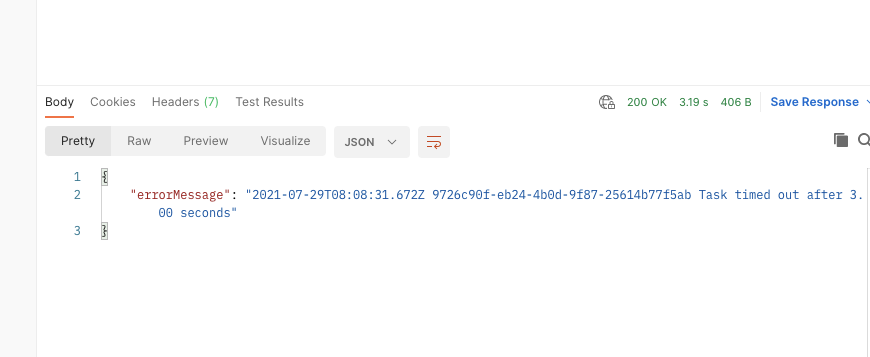
쿼리를 생성하고 결과를 저장할 때 1단계
쿼리 ID를 기준으로 결과를 불러올 때(상태는 SUCCESSED라고 가정) 3단계
코드 (python 3.7)
def lambda_handler(event, context):
start = time.time()
# 원하는 쿼리 생성
response_query_execution_id = client.start_query_execution(
QueryString = "원하는 쿼리문",
QueryExecutionContext = {
'Database' : '디비 이름',
},
ResultConfiguration = {
'OutputLocation' : "원하는 s3 버켓 위치"},
WorkGroup = 'primary'
)
# 생성한 쿼리로 조회 실행
response_get_query_details = client.get_query_execution(
QueryExecutionId = response_query_execution_id['QueryExecutionId'])
# 쿼리를 조회하는 상태 시작하자마자는 queue로 찍힌다.
status = response_get_query_details['QueryExecution']['Status']['State']
while True:
if status =='SUCCEEDED':
response_query_result = client.get_query_results(
QueryExecutionId = response_query_execution_id['QueryExecutionId'])
break
elif status =='FAILED':
print(response_get_query_details)
break
else:
response_get_query_details = client.get_query_execution(
QueryExecutionId = response_query_execution_id['QueryExecutionId'])
status = response_get_query_details['QueryExecution']['Status']['State']
result_data = response_query_result['ResultSet']
json_val = json.dumps(result_data)
return json_val
참고자료
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/athena.html#Athena.Client.get_query_results
https://docs.aws.amazon.com/ko_kr/athena/latest/APIReference/API_StartQueryExecution.html
