이진 트리
이진 트리는 비선형 자료구조이다. 이진트리는 데이터의 탐색 속도를 빠르게 하기 위해 사용한다.
이진 트리 등장 이전의 일반 트리에서는 자식의 수가 제한이 되어 있지않아 데이터를 균일하게 관리하기가 힘들었다. 또한 원하는 데이터를 찾는 과정이 번거롭고 효율적이지 못하였다. 따라서 이즌트리의 등장 이후 대부분의 트리는 이진 트리로 표현 되고있다.
이진 트리는 모든 노드가 2개의 서브 트리를 갖는 트리이다.
루트와 왼쪽 서브 트리, 오른쪽 서브 트리로 구성된 노드들의 집합, 이즌트리의 서브 트리들은 모두 이진트리이어야 한다.
포화 이진 트리
트리의 각 레벨에 노드가 꽉 차있는 이진 트리
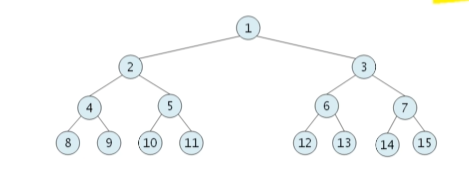
완전 이진 트리
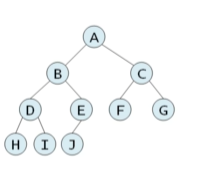
완전 이진 트리는 높이가 h일 때 레벨 1부터 h-1까지는 노드가 모두 채워져 있고 마지막 레벨 h에서는 노드가 순서대로 채워진 트리를 말한다. 즉 위에서부터 차례대로 트리를 채워온 형태이다.
기타 이진 트리
포화 이진 트리, 완전 이진 트리를 제외한 모든 이진 트리를 기타 이진 트리라고 한다.
이진 트리의 성질
노드의 개수가 n개이면 간선의 개수는 n-1개 이다. (루트 노트의 부모가 없기 때문이다.)
높이가 n 이면 n ~2ⁿ-1개의 노드를 갖는다.
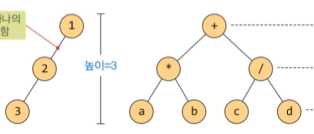
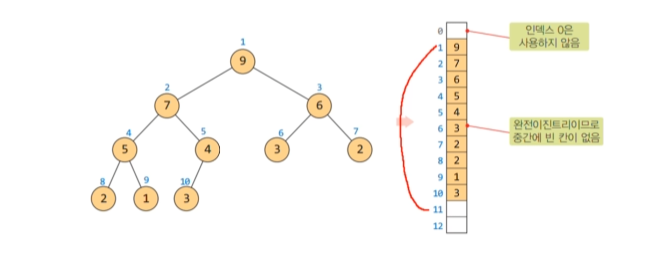
이진 트리의 배열 표현법
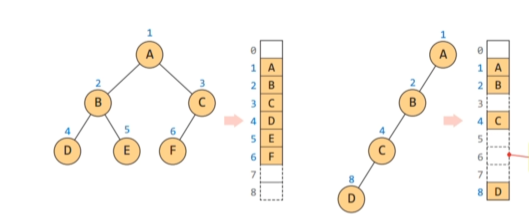
배열을 만들 때 이진트리의 속성을 고려하여 트리에서 비여있는 부분에는 언제는 값이 들어갈수있음으로 배열에서도 비운채로 할당해줘야 한다.
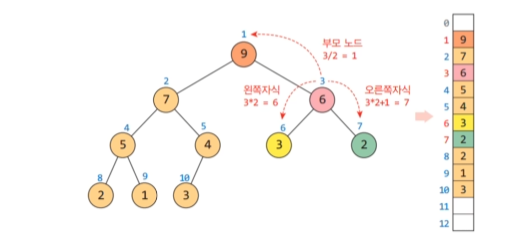
노드 i의 부모 노드 인덱스 = i//2 => //한 이유는 홀수를 나눴을 경우 나머지를 버려줘야 하기 때문이다.
노드 i의 왼쪽 자식 노드 인덱스 = 2i
노드 i의 오른쪽 자식 노드 인덱스 = 2i +1
이진트리의 연산
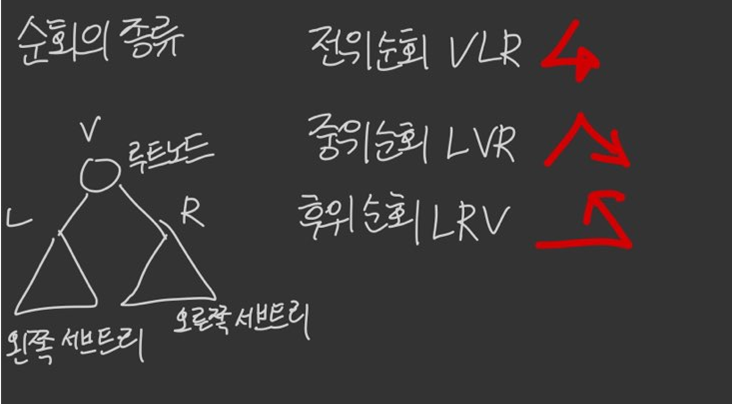
순회
트리에 속하는 모든 노드를 한 번씩 방문하는 것
선형 자로구조는 순회가 단순 => 그냥 순서대로 방문
트리는 다양한 방법이 있다 ex) (BFS, DFS)
전위 순회 VLR (루트 -> 왼쪽 -> 오른쪽) = DFS
def preorder(n):
if n is not None:
print(n.data, end='') // 루트노드 처리
preorder(n.left) // 왼쪽 서브트리 처리
preorder(n.right) // 오른쪽 서브트리 처리중위 순회 LVR (왼쪽 -> 루트 -> 오른쪽)
def inorder(n):
if n is not None:
inorder(n.left) // 왼쪽 서브트리 처리
print(n.data, end='') // 루트노드 처리
inorder(n.right) // 오른쪽 서브트리 처리후위 순회 LRV (왼쪽 -> 오른쪽 -> 루트)
def postorder(n):
if n is not None:
postorder(n.left) // 왼쪽 서브트리 처리
postorder(n.right) // 오른쪽 서브트리 처리
print(n.data, end='') // 루트노드 처리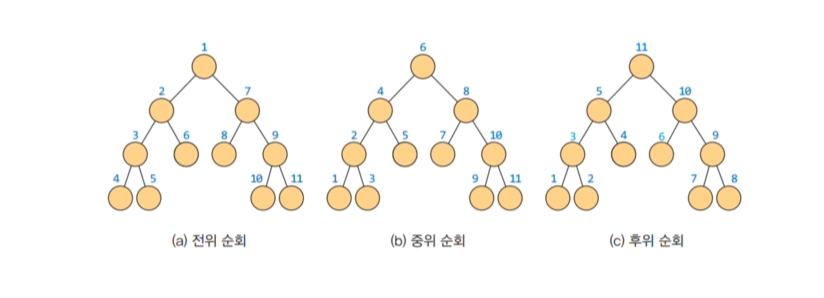
레벨 순회 (노드를 레벨 순으로 검사하는 순회 방법)
큐를 사용해 구현 한다.
순환을 사용하지 않는다.
연산 순서 계산에 활용가능 (연산의 우선순위)
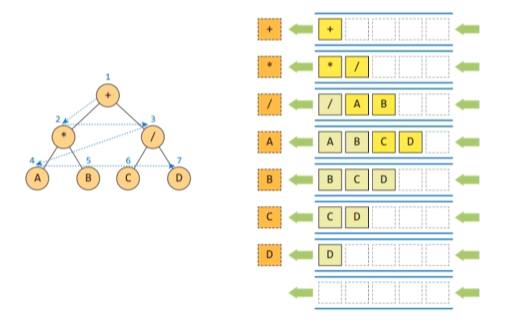
def levelorder(root):
queue = CircularQueue() //큐 객체 초기화
queue.enqueue(root) // 최초의 큐에는 루트 노드만 들어있음
while not queue.isEmpty(): // 큐가 공백이 아닌 동안
n = queue.dequeue //큐에서 맨 앞의 노드 n을 꺼냄
if n is not None:
print(n.data, end='') //먼저 노드의 정보를 출력
queue.enqueue(n.left) // n의 왼쪽 자식 노드를 큐에 삽입
queue.enqueue(n.right) // n의 오른쪽 자식 노드를 큐에 삽입힙(Heap)
힙이란 완전이진트리 기반의 자료구조로 가장 큰(가장 작은)값을 빠르게 찾아내도록 만들어진 자료구조이다.
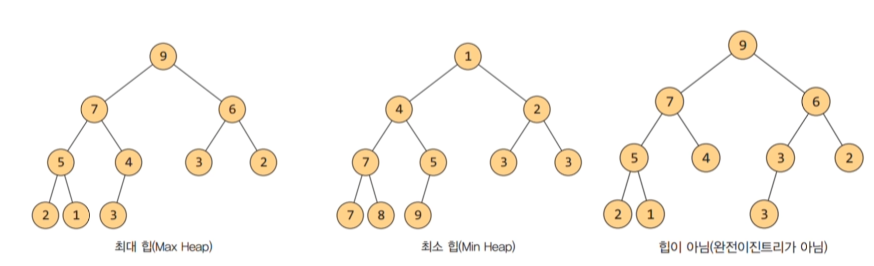
최대 힙: 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전이진트리
최소 힙: 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전이진트리\
힙의 연산: 삽입 연산
가장 아래 노드에 새로운 값을 넣고 -> 부모 노드와 크기를 비교하여 크다면 부모 노드와 값 교환 -> 부모 노드보다 작을 때 까지 반복
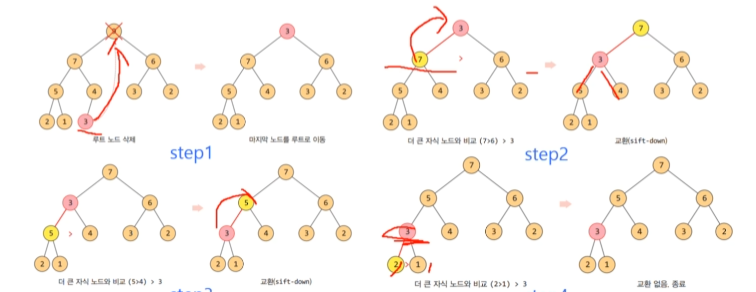
힙의 삭제
삭제된 자리에 가장 마지막에 들어온(가장 아래에 있는) 노드의 값을 넣어준다 -> 이렇게 넣어준 노드의 값이 그 아래 자식들중 더 큰 자식의 노드값과 비교하여 작으면 자식의 노드값과 교환 -> 클 때 까지 반복
힙의 구현: 배열구조
힙은 완전 이진트리이기에 이진트리의 배열 표현법과 동일하다