실전 수익형 웹, 앱 서비스 동물상 테스트 만들기의
1번째 영상을 통해 제작된 코드입니다.
해당 내용에 도움이 되는 부분은 링크를 걸어두었습니다!
그럼 시작하도록 하겠습니다!
1. Beautiful Soup를 통한 크롤링 이해
우선 Python 설치를 한 후, cmd를 통해 원하는 로컬 파일의 경로에 index.py를 생성한다.
물론 생성할 index.py의 파일명은 아무거나 상관없다.
자신이 사용하는 에디터 툴(필자는 Atom)을 이용하여 테스트로
print("Hello Wolrd!")위의 코드를 입력 후, 저장한 다음 cmd를 통해 해당 .py 파일이 있는 경로를 지정한다.
(경로는 자신이 원하는 곳으로)
cd C:\Bitnami\wampstack-8.1.5-0\apache2\htdocs\just_make위의 코드 cmd에 입력하여 해당 파일의 경로로 이동, index.py를 입력!
C:\Bitnami\wampstack-8.1.5-0\apache2\htdocs\just_make>index.py
Hello World!이렇게 잘 나오는 것을 확인했다면 Python 설치는 완료!
이제 Beautiful Soup 4 사용을 위한 라이브러리 설치!
pip install beautifulsoup4위의 코드를 cmd에 입력 후, 설치가 완료 되었다면 본격적으로
Beautiful Soup 4의 라이브러리를 사용해보도록 하자!
Beautiful Soup 위키피디아의 Code example의
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))이러한 코드를 자신의 .py 파일에 에디터 툴(필자는 Atom)을 통해 입력한다.
위의 코드를 나름 해석해보자면!
from bs4 import BeautifulSoup
from urllib.request import urlopen위의 코드는 bs4(Beautiful Soup 4)로부터 BeautifulSoup의 기능을 불러온다!
urllib.request로부터 urlopen(url을 여는 기능?) 기능을 불러온다!
필자가 Python 공부를 하며 많이 봤던 import cgi, math처럼 모듈 불러오기 기능이다.
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:위의 코드는 뭔가 낯설어 보이지만...사실!
response = urlopen('https://en.wikipedia.org/wiki/Main_Page')이렇게 볼 수 있다. 결국 response라는 변수에 해당 내용을 담았다는 뜻.
urlopen의 기능을 통해 https://en.wikipedia.org/wiki/Main_Page를 연다!
이런 뜻의 코드를 변수에 담았다는 것!
soup = BeautifulSoup(response, 'html.parser')다음으로 위의 코드는 Beautifulsoup 함수를 이용해서
만들어진 response라는 변수를 html.parser라는 기능으로 분석해준다라는 의미.
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))여기서 반가운 for문이 나왔다... 정말 너무 반가웠다.
위의 코드의 의미는 for문을 이용하여 response에 담겨진 링크에 있는 a 태그를 모두 찾고,
찾은 a 태그에서 하이퍼링크를 받아온다는 의미이다.
이렇게 간단(?)하게 분석 및 사용 원리를 어느정도 파악 완료한 것 같다.
이제 cmd를 이용하여 실행을 시켜주면?
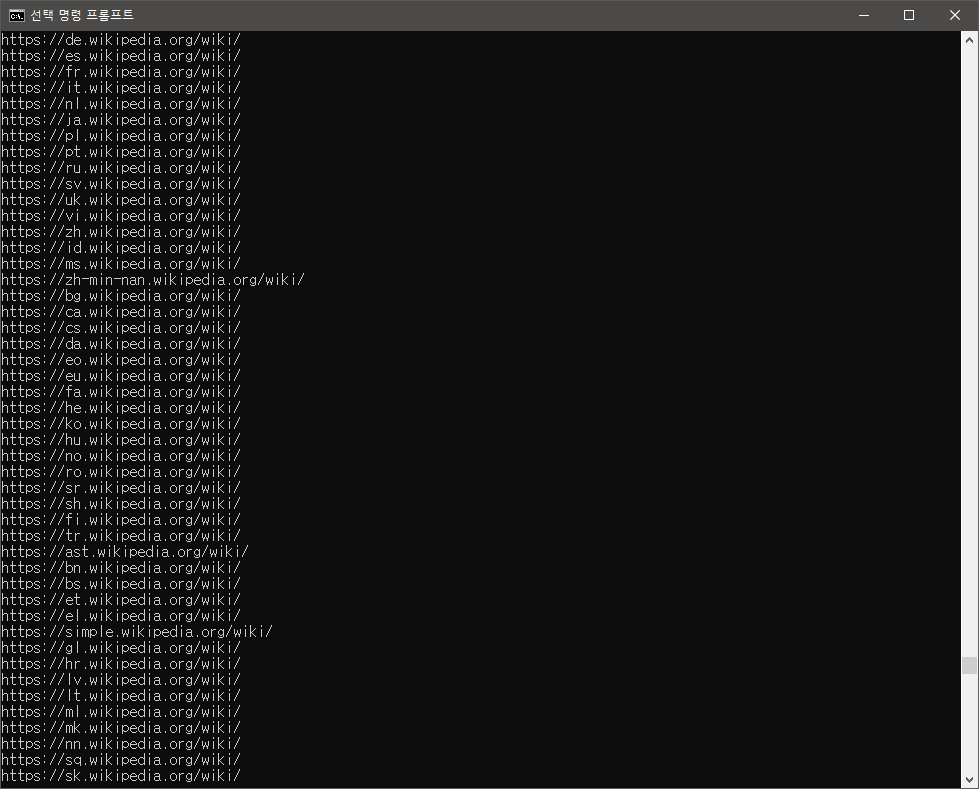
이렇게 해당 링크에 있는 모든 하이퍼링크를 cmd를 통해 출력되는 것을 확인할 수 있다.
붙여넣기한 코드의 링크가 아닌 다른 링크의 정보를 받고 싶다면?
from bs4 import BeautifulSoup
from urllib.request import urlopen
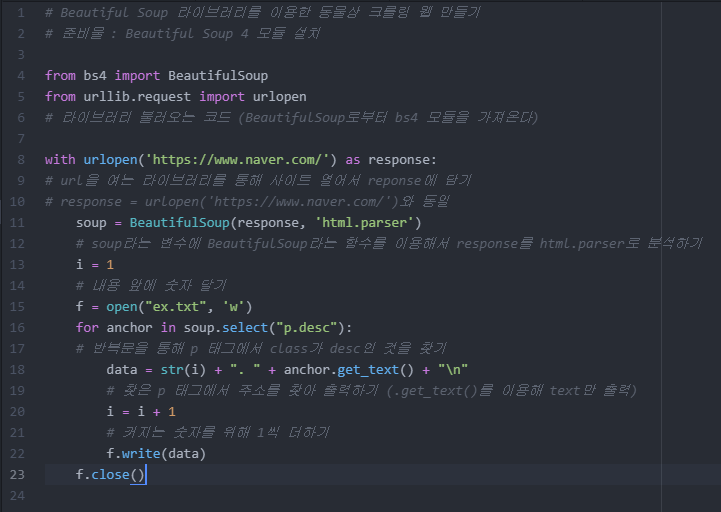
with urlopen('https://www.naver.com/') as response:
# 원하는 사이트의 주소를 입력
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.select("strong.title"):
# .select를 이용하여 strong 태그의 title class를 얻기
print(anchor)
# 지금 얻으려는 정보들은 .get을 할 이유가 없기에 삭제이런식으로 원하는 사이트의 태그, 클래스를 브라우저 개발자 도구로 알아낸 후 입력하면?
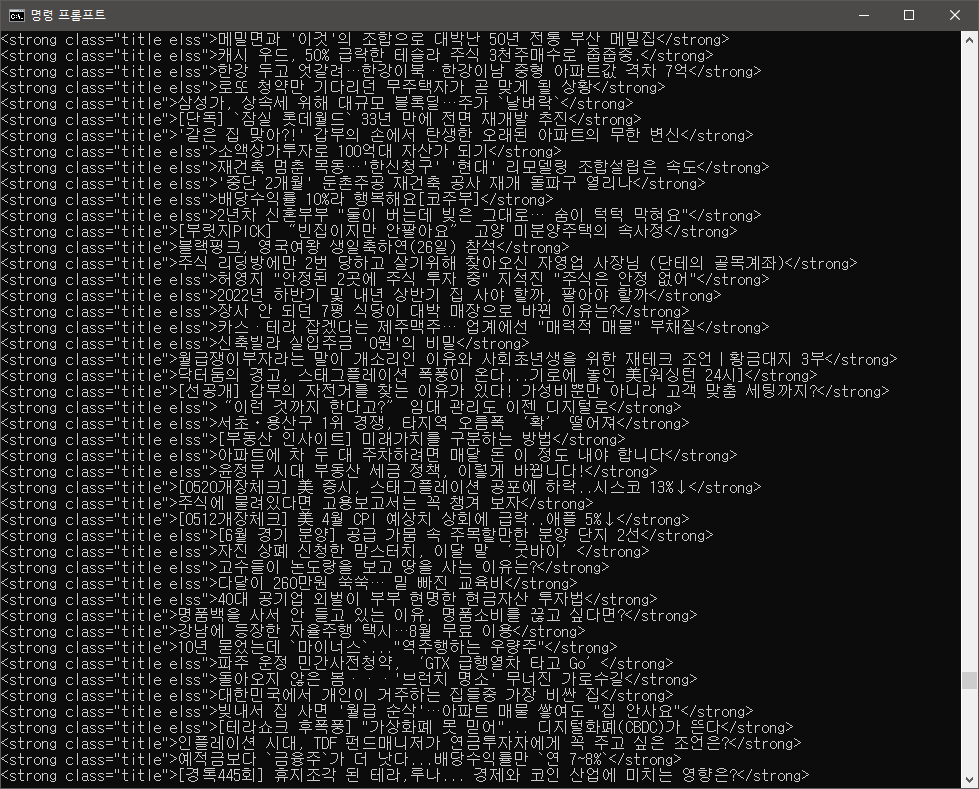
이렇게 원하는 정보들이 주르륵 나오게 된다!
(사실 조코딩님의 예제에는 실시간 검색어지만 없어지는 바람에...)
그래서 예시는 네이버 메인에 보이는 추천 엔터 제목으로 했다.
추가적으로 이런 것도 가능하다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://www.naver.com/') as response:
soup = BeautifulSoup(response, 'html.parser')
f = open("ex.txt", 'w')
# f라는 변수에 쓰기 전용으로 ex.txt파일 생성
for anchor in soup.select("strong.title"):
data = anchor.get_text() + "\n"
# 원하는 정보의 text만 추출 + 줄바꿈
f.write(data)
# f라는 변수에 data를 쓰기
f.close()
# f 변수(ex.txt) 닫기원하는 내용을 text 형식으로 다운받기!
이렇게 코드를 수정한 후, cmd로 해당 파일을 실행시키면
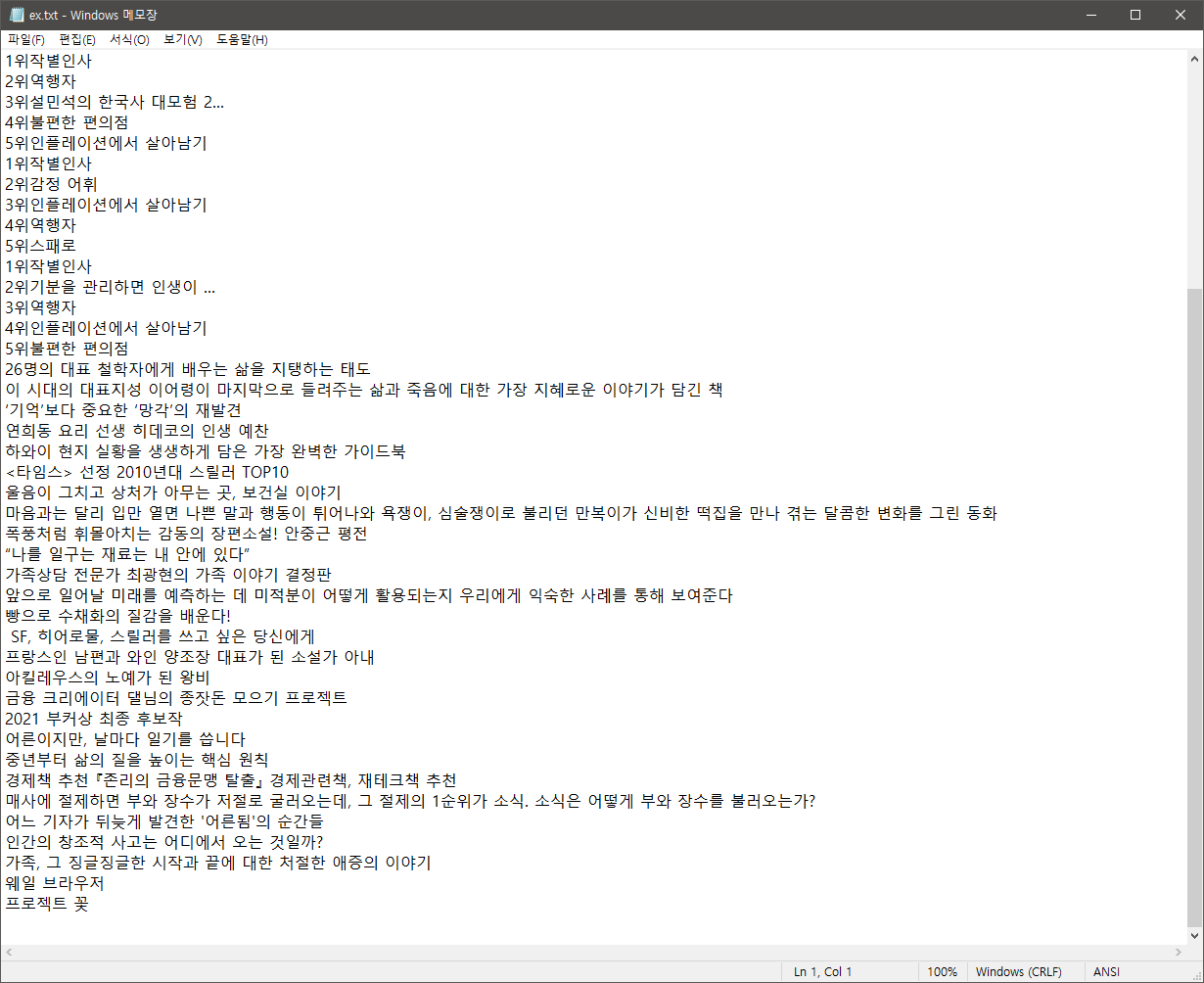
결과물이 이렇게 나오는 걸 확인할 수 있다.
이렇게 알 수 있는 크롤링 지식!
Crawling(크롤링)을 통해 해당 웹 페이지에 자신이 원하는 정보를 찾는 것도 가능하며,
필요에 따라서는 그러한 정보를 다운받을 수 있다!
그렇다면 이제 다음 단계로 넘어가도록 하자.
2. 원하는 이미지를 찾고 컴퓨터에 저장
사실 원하는 코드는 머리속에 있기는 하다...
원하는 키워드를 자동으로 구글링해주고, 이미지를 다운받아 주고,
원하는 키워드 별로 디렉토리를 다르게 해서 저장해주는...
이러한 코드는 사실 새싹 개발자에게는 매우 무리일 것이다...
하지만 내가 이런 생각을 했다는 것은 결국 누군가는 이미 만들었다는 의미!
그렇다면 구글링을 통해 원하는 검색어에 맞게 이미지를 불러오는 코드를 찾아본다.
python google image search and download와 같은 키워드로 구글링을 한 후,
구글 이미지 다운로드 코드에 나오는
pip install google_images_download위의 코드를 cmd에 ...하면 되지만 이미지 다운을 받는 도중에 필자는 에러가 났다...
설치는 정상적으로 됐으나, 마지막에 이미지 다운이 안됐다...
이러한 에러도 google image download error라는 키워드의 구글링을 통해
알아낸 결과!
pip uninstall google_images_downloadcmd에 위의 코드 입력으로 기존의 google image download를 삭제한 다음,
google image download (stack overflow)에 올라와있는
pip install git+https://github.com/Joeclinton1/google-images-download.git위의 코드를 cmd에 입력해서 재설치를 하게 되었다.
준비가 됐다면, 새로운 .py 파일을 만들고
google image download Code sample에서 Code smaple 부분의
from google_images_download import google_images_download
response = google_images_download.googleimagesdownload()
arguments = {"keywords":"Polar bears,baloons,Beaches","limit":20,"print_urls":True}
paths = response.download(arguments)
print(paths)위의 코드를 에디터를 통해 입력하도록 한다.
필자는 위의 코드의 주석(
#잡다한 설명~)을 전부 지웠다.
마찬가지로 코드에 대한 간단한 해석을 해보자면,
from google_images_download import google_images_download위의 코드는 위에서도 본 것 같은...바로 google_images_download로부터
google_images_download 기능을 불러온다는 의미
response = google_images_download.googleimagesdownload()response라는 변수에 google_images_download의 기능으로 보이는 코드를 담고,
arguments = {"keywords":"Polar bears,baloons,Beaches","limit":20,"print_urls":True}
paths = response.download(arguments)
print(paths)keywords에 원하는 키워드를 입력, limit에는 몇 장을 다운받을 것인지,
이미지의 url들을 출력할 것인지를 arguments라는 변수에 담는다.
필요한 기능들을 담았다면, google_images_download 기능을 사용해보자!
위에서 지정한 키워드, 사진 개수 등의 정보가 담긴 arguments를
response.download라는 다운로드 기능을 통해 이미지를 다운받도록 지정 후,
이걸 또 paths라는 변수에 담는다.
하지만, 여기서 함정은 사진을 받는 것은 맞지만 확장자를 지정하지 않았으므로
쓰이지 않을gif와 같은 확장자도 섞이며 아주 멋대로 날 뛸 예정이다.
Input Arguments에서 extension 키워드를 통해 format이라는 기능을 찾도록 하자.
이렇게 찾은 코드를 입력하자면...
arguments = {"keywords":"Polar bears,baloons,Beaches","limit":20,"print_urls":True,"format" : "jpg"}arguments 변수에 format을 입력해서 jpg 파일로만 다운받도록 지정
결론적으로 나온 이미지 다운 코드!
from google_images_download import google_images_download
response = google_images_download.googleimagesdownload()
arguments = {"keywords":"워너원 강다니엘, 엑소 백현, 박보검, 송중기, 워너원 황민현, 엑소 시우민, 강동원, 이종석, 이준기, 마동석, 조진웅, 조세호, 안재홍, 윤두준, 이민기, 김우빈, 육성재, 공유, 방탄소년단 정국, 아이콘 바비, 워너원 박지훈, 엑소 수호","limit":50,"print_urls":True, "format" : "jpg"}
paths = response.download(arguments)
print(paths)위의 코드에서 연예인 이름들은 조코딩님이 사전에 동물상으로 유명한 연예인들을
미리 찾아왔기 때문에 따라하는 것이 목적인 나는 예시를 똑같이 따라서 코딩해봤다.
위의 코드와 같이 입력하고 난 후, cmd를 통해 코드를 실행하게 되면???

!!!
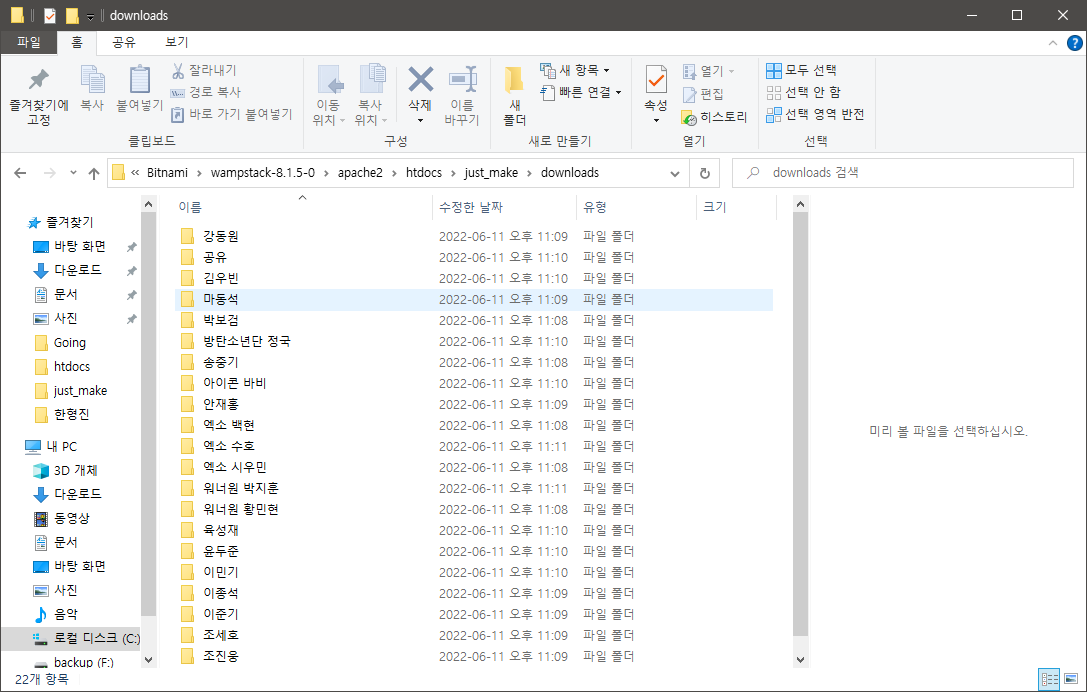
!!!
정상적으로 키워드에 맞춰서 이미지가 다운받아졌다.
이제 갓 언어에 입문해서 차근차근 공부하던 도중에 재미삼아 코딩을 따라해봤다.
이런 것을 두고 클론 코딩이라고 하는 것인가?
그리고 구글링의 위대함과 중요함을 다시금 깨닫게 되는 시간이었다...
마치며...
아무튼! 동물상 테스트를 위한 견본(?)을 얻기 위해 키워드를 정하고
크롤링을 함으로써 원하는 정보를 얻는 코딩을 해보았다.
이제 1편 후로 점점 발전해가는 앱을 만들 수 있기를 기원하며 1편을 마치도록 한다.
다음 2편도 무사히 성공할 수 있도록...
