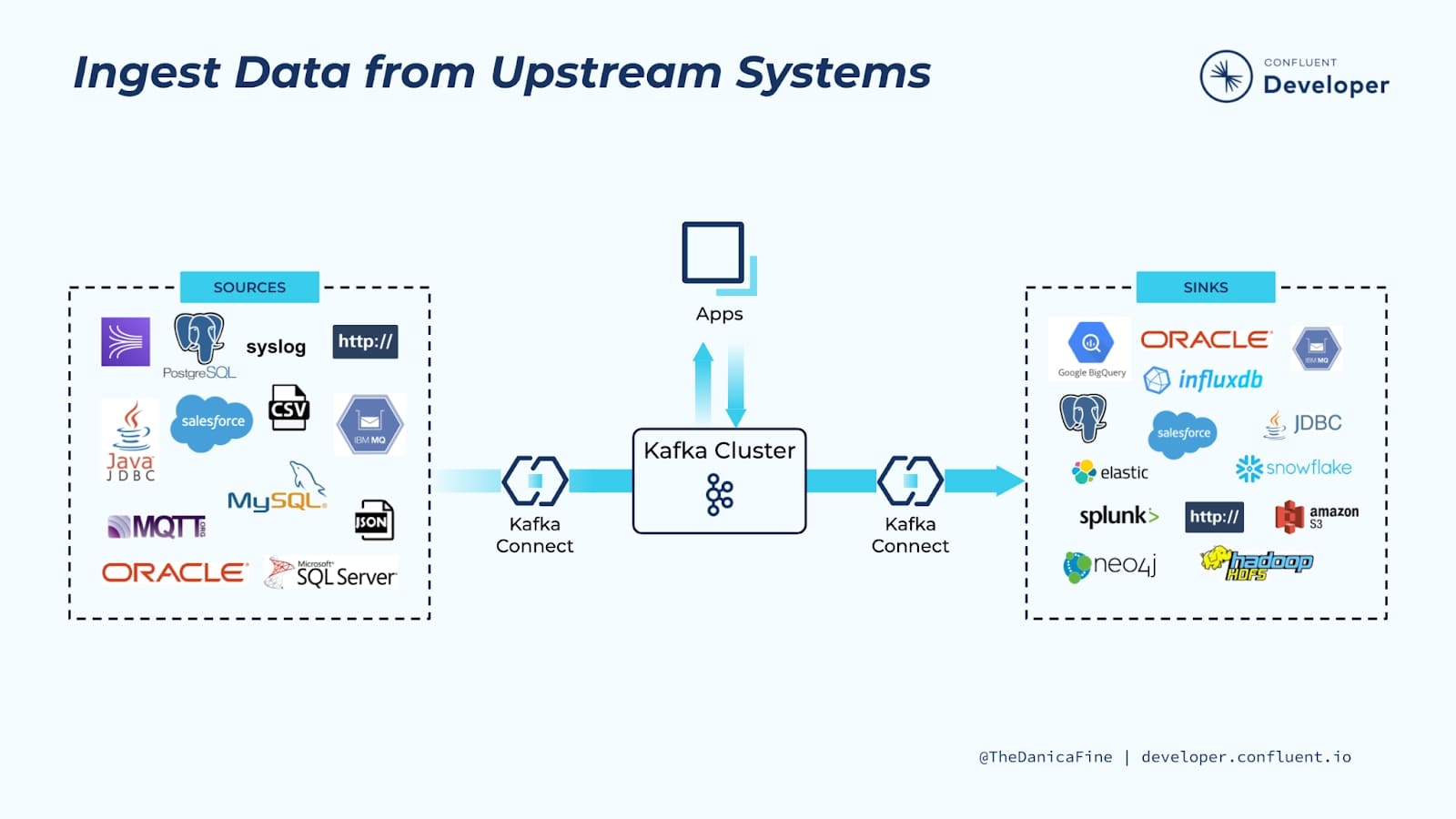
🔌 Kafka Connect 개요
Apache Kafka Connect는 카프카와 외부 시스템 간의 데이터를 안정적이고 확장 가능하게 스트리밍하기 위한 프레임워크입니다. 복잡한 코드 작성 없이 다양한 데이터 소스와 카프카를 손쉽게 연결할 수 있어, 데이터 파이프라인 구축을 단순화합니다.
Kafka Connect의 필요성
기존에는 데이터를 카프카로 보내거나 카프카에서 데이터를 가져오기 위해 매번 Producer와 Consumer 애플리케이션을 직접 개발해야 했습니다. 이런 반복적인 작업은 다음과 같은 문제를 야기했습니다:
- 개발 시간 낭비: 유사한 코드를 반복적으로 작성
- 유지보수 부담: 각 데이터 소스마다 별도의 코드 관리 필요
- 표준화 부재: 팀마다 다른 방식으로 통합 구현
- 확장성 제한: 새로운 데이터 소스 추가 시 개발 비용 증가
Kafka Connect는 이러한 문제를 해결하기 위해 표준화된 방식으로 데이터 통합을 제공합니다.
🏗️ Kafka Connect 아키텍처
핵심 구성 요소
Kafka Connect는 다음과 같은 주요 컴포넌트로 구성됩니다:
1. 커넥터 (Connector)
커넥터는 Kafka Connect의 핵심 논리 단위로, 데이터 복사 작업을 정의합니다. 두 가지 유형이 있습니다:
- Source Connector (소스 커넥터): 외부 시스템 → Kafka로 데이터 전송
- Sink Connector (싱크 커넥터): Kafka → 외부 시스템으로 데이터 전송
2. Task (태스크)
커넥터가 생성하는 실제 작업 단위입니다. 병렬 처리를 위해 여러 태스크로 분산될 수 있습니다.
3. Worker (워커)
커넥터와 태스크를 실행하는 프로세스입니다. 두 가지 실행 모드를 지원합니다:
- Standalone Mode (단독 모드): 단일 프로세스에서 실행 (개발/테스트용)
- Distributed Mode (분산 모드): 여러 워커가 클러스터를 구성 (프로덕션 환경)
4. Converter (컨버터)
데이터 형식을 변환합니다 (예: JSON, Avro, String).
5. Transform (변환기)
데이터를 처리하는 과정에서 간단한 변환 작업을 수행합니다.
데이터 흐름
외부 시스템 → Source Connector → Kafka Topic → Sink Connector → 외부 시스템📦 주요 커넥터 종류
Kafka Connect는 다양한 사전 제작된 커넥터를 제공합니다:
1. JDBC Connector
관계형 데이터베이스와의 통합을 위한 가장 널리 사용되는 커넥터입니다.
Source Connector:
- MySQL, PostgreSQL, Oracle 등의 데이터를 Kafka로 전송
- 테이블 변경사항을 실시간으로 감지 (Change Data Capture)
Sink Connector:
- Kafka의 데이터를 관계형 데이터베이스에 저장
{
"name": "jdbc-source-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "user",
"connection.password": "password",
"table.whitelist": "users,orders",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "mysql-"
}
}2. Elasticsearch Connector
Kafka의 데이터를 Elasticsearch로 전송하여 검색 및 분석을 가능하게 합니다.
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics": "logs",
"connection.url": "http://localhost:9200",
"type.name": "_doc"
}
}3. S3 Connector
Kafka 토픽의 데이터를 Amazon S3에 저장합니다 (데이터 레이크 구축).
4. MongoDB Connector
NoSQL 데이터베이스인 MongoDB와의 양방향 데이터 전송을 지원합니다.
5. HDFS Connector
빅데이터 처리를 위해 Hadoop HDFS에 데이터를 저장합니다.
6. FileStream Connector
로컬 파일 시스템과 Kafka 간 데이터 전송 (개발/테스트용).
🎯 Kafka Connect 주요 사용사례
1. 데이터베이스 CDC (Change Data Capture)
실시간으로 데이터베이스의 변경사항을 감지하고 Kafka로 스트리밍합니다.
활용 예시:
- MySQL의 주문 테이블 변경사항을 실시간으로 Kafka에 전송
- 마이크로서비스 간 데이터 동기화
- 데이터 웨어하우스로 실시간 데이터 복제
MySQL (Orders Table) → JDBC Source Connector → Kafka (orders topic)사용 커넥터: Debezium MySQL Connector, JDBC Source Connector
2. 로그 집계 및 모니터링
분산 시스템의 로그를 중앙 집중식으로 수집하고 분석합니다.
활용 예시:
- 여러 서버의 애플리케이션 로그를 Kafka로 수집
- Elasticsearch로 전송하여 Kibana로 시각화
- 실시간 알람 및 모니터링 시스템 구축
Application Logs → FileStream Source → Kafka → Elasticsearch Sink → Kibana3. 데이터 레이크 구축
대량의 데이터를 저렴한 저장소에 보관하고 나중에 분석합니다.
활용 예시:
- Kafka의 모든 이벤트를 S3에 자동 저장
- Parquet 또는 Avro 형식으로 압축하여 저장
- AWS Athena 또는 Spark로 배치 분석
Kafka Topics → S3 Sink Connector → Amazon S3 → AWS Athena4. 실시간 검색 인덱싱
데이터를 실시간으로 검색 엔진에 색인화합니다.
활용 예시:
- 전자상거래 상품 정보를 Elasticsearch에 실시간 동기화
- 사용자가 항상 최신 검색 결과를 볼 수 있도록 보장
- 자동완성 기능을 위한 실시간 인덱싱
Product DB → Source Connector → Kafka → Elasticsearch Sink → 검색 서비스5. 이벤트 소싱 아키텍처
모든 상태 변경을 이벤트로 저장하는 패턴을 구현합니다.
활용 예시:
- 주문 시스템의 모든 이벤트를 Kafka에 저장
- 이벤트를 다양한 데이터베이스로 복제
- 감사 추적(audit trail) 및 시간 여행 쿼리 지원
6. 데이터 웨어하우스 통합
운영 데이터베이스의 데이터를 분석용 데이터 웨어하우스로 전송합니다.
활용 예시:
- PostgreSQL의 거래 데이터를 BigQuery로 실시간 전송
- BI 도구에서 거의 실시간 분석 가능
- ETL 파이프라인 대체
OLTP DB → Source Connector → Kafka → BigQuery Sink → BI Tool (Tableau)7. 마이크로서비스 데이터 동기화
서로 다른 마이크로서비스의 데이터베이스를 동기화합니다.
활용 예시:
- 주문 서비스의 데이터를 배송 서비스 DB에 복제
- 각 서비스가 독립적인 데이터베이스를 유지하면서 필요한 데이터 공유
- CQRS 패턴 구현 (Command Query Responsibility Segregation)
8. IoT 데이터 수집
IoT 디바이스에서 생성되는 대량의 센서 데이터를 수집합니다.
활용 예시:
- MQTT 브로커의 센서 데이터를 Kafka로 전송
- 실시간 스트림 처리 및 이상 탐지
- 시계열 데이터베이스(InfluxDB)에 저장
⚙️ Kafka Connect 실행하기
1. Standalone 모드 실행
개발 및 테스트 환경에 적합합니다.
# Connect 설정 파일
vi config/connect-standalone.properties# Bootstrap 서버 설정
bootstrap.servers=localhost:9092
# 데이터 형식 변환 설정
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
# 오프셋 저장 위치
offset.storage.file.filename=/tmp/connect.offsets# Standalone 모드로 실행
bin/connect-standalone.sh \
config/connect-standalone.properties \
config/connector-config.properties2. Distributed 모드 실행
프로덕션 환경에서 권장되는 방식입니다.
# Distributed 설정 파일
vi config/connect-distributed.properties# 클러스터 식별자
group.id=connect-cluster
# Bootstrap 서버
bootstrap.servers=localhost:9092
# 내부 토픽 설정
config.storage.topic=connect-configs
offset.storage.topic=connect-offsets
status.storage.topic=connect-status
# 복제 팩터
config.storage.replication.factor=3
offset.storage.replication.factor=3
status.storage.replication.factor=3
# REST API 포트
rest.port=8083# Distributed 모드로 실행
bin/connect-distributed.sh config/connect-distributed.properties3. REST API를 통한 커넥터 관리
Kafka Connect는 RESTful API를 제공하여 커넥터를 관리할 수 있습니다.
커넥터 목록 조회
curl http://localhost:8083/connectors커넥터 생성
curl -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d '{
"name": "mysql-source",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "user",
"connection.password": "password",
"table.whitelist": "users",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "mysql-"
}
}'커넥터 상태 확인
curl http://localhost:8083/connectors/mysql-source/status커넥터 삭제
curl -X DELETE http://localhost:8083/connectors/mysql-source커넥터 일시 중지 및 재개
# 일시 중지
curl -X PUT http://localhost:8083/connectors/mysql-source/pause
# 재개
curl -X PUT http://localhost:8083/connectors/mysql-source/resume🔧 실전 예제: MySQL to Kafka
1. JDBC Connector 설정
{
"name": "mysql-source-users",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"connection.url": "jdbc:mysql://localhost:3306/ecommerce",
"connection.user": "kafka_user",
"connection.password": "secure_password",
"table.whitelist": "users,orders",
"mode": "timestamp+incrementing",
"timestamp.column.name": "updated_at",
"incrementing.column.name": "id",
"topic.prefix": "mysql-",
"poll.interval.ms": "5000",
"batch.max.rows": "100"
}
}2. 커넥터 배포
curl -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d @mysql-source-config.json3. 데이터 확인
# Kafka 토픽 확인
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
# 메시지 확인
bin/kafka-console-consumer.sh \
--topic mysql-users \
--from-beginning \
--bootstrap-server localhost:9092💡 Kafka Connect 모범 사례
1. 분산 모드 사용
프로덕션 환경에서는 항상 분산 모드를 사용하여 고가용성을 확보하세요.
2. 적절한 태스크 수 설정
{
"tasks.max": "3" // 병렬 처리를 위해 적절한 수 설정
}3. 배치 크기 최적화
{
"batch.max.rows": "500", // 한 번에 처리할 레코드 수
"poll.interval.ms": "5000" // 폴링 간격
}4. 에러 핸들링 설정
{
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"errors.deadletterqueue.topic.name": "dlq-topic"
}5. 모니터링 및 알람
- JMX 메트릭을 통한 모니터링
- Prometheus + Grafana 통합
- 커넥터 상태 주기적 체크
6. 스키마 레지스트리 활용
{
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://localhost:8081",
"value.converter.schema.registry.url": "http://localhost:8081"
}🚀 커스텀 커넥터 개발
기존 커넥터가 요구사항을 만족하지 못할 경우, 커스텀 커넥터를 개발할 수 있습니다.
Source Connector 예제 (Java)
public class CustomSourceConnector extends SourceConnector {
@Override
public void start(Map<String, String> props) {
// 초기화 로직
}
@Override
public Class<? extends Task> taskClass() {
return CustomSourceTask.class;
}
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
// 태스크 설정 반환
return configs;
}
@Override
public void stop() {
// 정리 로직
}
@Override
public ConfigDef config() {
// 설정 정의 반환
return CONFIG_DEF;
}
@Override
public String version() {
return "1.0.0";
}
}📊 성능 최적화 팁
1. 네트워크 최적화
# 압축 활성화
compression.type=lz4
# 배치 크기 증가
batch.size=32768
linger.ms=102. 메모리 설정
export KAFKA_HEAP_OPTS="-Xms2G -Xmx4G"3. 병렬 처리 최적화
{
"tasks.max": "8", // CPU 코어 수에 맞춰 설정
"consumer.max.poll.records": "1000"
}🛠️ 문제 해결 (Troubleshooting)
1. 커넥터가 실패하는 경우
# 로그 확인
tail -f logs/connect.log
# 커넥터 상태 확인
curl http://localhost:8083/connectors/my-connector/status2. 데이터가 전송되지 않는 경우
- 데이터베이스 연결 확인
- 토픽 권한 확인
- 오프셋 리셋:
offset.storage.topic토픽 삭제 후 재시작
3. 성능 문제
- 태스크 수 증가
- 배치 크기 조정
- 네트워크 대역폭 확인
📈 Kafka Connect vs 다른 방식
| 비교 항목 | Kafka Connect | Custom Producer/Consumer | ETL 도구 |
|---|---|---|---|
| 개발 난이도 | 낮음 (설정만) | 높음 (코딩 필요) | 중간 |
| 유지보수 | 쉬움 | 어려움 | 중간 |
| 확장성 | 매우 높음 | 높음 | 중간 |
| 실시간 처리 | 우수 | 우수 | 배치 위주 |
| 표준화 | 높음 | 낮음 | 높음 |
| 커뮤니티 지원 | 우수 | - | 도구별 상이 |
🎓 다음 단계
Kafka Connect를 마스터했다면 다음 주제를 학습해보세요:
- Kafka Streams: 실시간 스트림 처리
- Schema Registry: 스키마 관리 및 호환성 보장
- ksqlDB: SQL로 스트림 처리하기
- Debezium: 강력한 CDC 솔루션
- Confluent Platform: 엔터프라이즈 기능 활용
📚 참고 자료
- Kafka Connect 공식 문서
- Confluent Hub - 다양한 커넥터 다운로드
- Debezium - CDC 전문 커넥터
- Kafka Connect Deep Dive
💡 마치며
Kafka Connect는 복잡한 데이터 통합 작업을 간소화하고 표준화하는 강력한 도구입니다. 코드 작성 없이 설정만으로 다양한 시스템과 Kafka를 연결할 수 있어, 개발 시간을 크게 단축하고 유지보수 부담을 줄일 수 있습니다.
프로덕션 환경에서는 분산 모드로 실행하고, 적절한 모니터링과 에러 핸들링을 설정하며, 스키마 레지스트리를 활용하여 데이터 품질을 보장하는 것이 중요합니다.
실시간 데이터 파이프라인 구축을 위해 Kafka Connect를 적극 활용해보세요! 🚀
