kafka
1.Quorum과 Kafka의 Quorum 동작 방식 완벽 가이드

분산 시스템을 공부하다 보면 반드시 마주치게 되는 개념이 있습니다. 바로 Quorum(쿼럼)입니다. 오늘은 Quorum이 무엇인지, 왜 필요한지, 그리고 Apache Kafka에서 어떻게 활용되는지 깊이 있게 알아보겠습니다.Quorum Consensus DiagramQ
2.Apache Kafka 4.0: 아키텍처 및 주요 특징

완벽합니다! 이제 카프카 4.0에 대한 포괄적인 마크다운 블로그 글을 작성해드리겠습니다.Apache Kafka 4.0은 2025년 3월에 출시된 메이저 릴리즈로, 이벤트 스트리밍 플랫폼의 역사에서 중요한 전환점을 맞이했습니다. 가장 주목할 만한 변화는 10년 이상 Ka
3.Kafka MirrorMaker 2란?

완벽합니다! 이제 Mirror Maker 2에 대한 포괄적인 마크다운 블로그 글을 작성해드리겠습니다.분산 시스템에서 데이터 복제(Replication)는 가용성과 내구성을 보장하는 핵심 메커니즘입니다. Apache Kafka는 단일 클러스터 내에서 파티션 간 복제를 통
4.카프카 설치 및 초기세팅 가이드

Apache Kafka는 LinkedIn에서 개발한 분산 스트리밍 플랫폼으로, 대용량의 실시간 데이터 피드를 처리할 수 있는 고성능 메시징 시스템입니다. 빅데이터 환경에서 실시간 데이터 파이프라인을 구축하고 스트리밍 애플리케이션을 개발하는 데 널리 사용됩니다.Kafka
5.카프카 커넥트란? 주요 사용사례
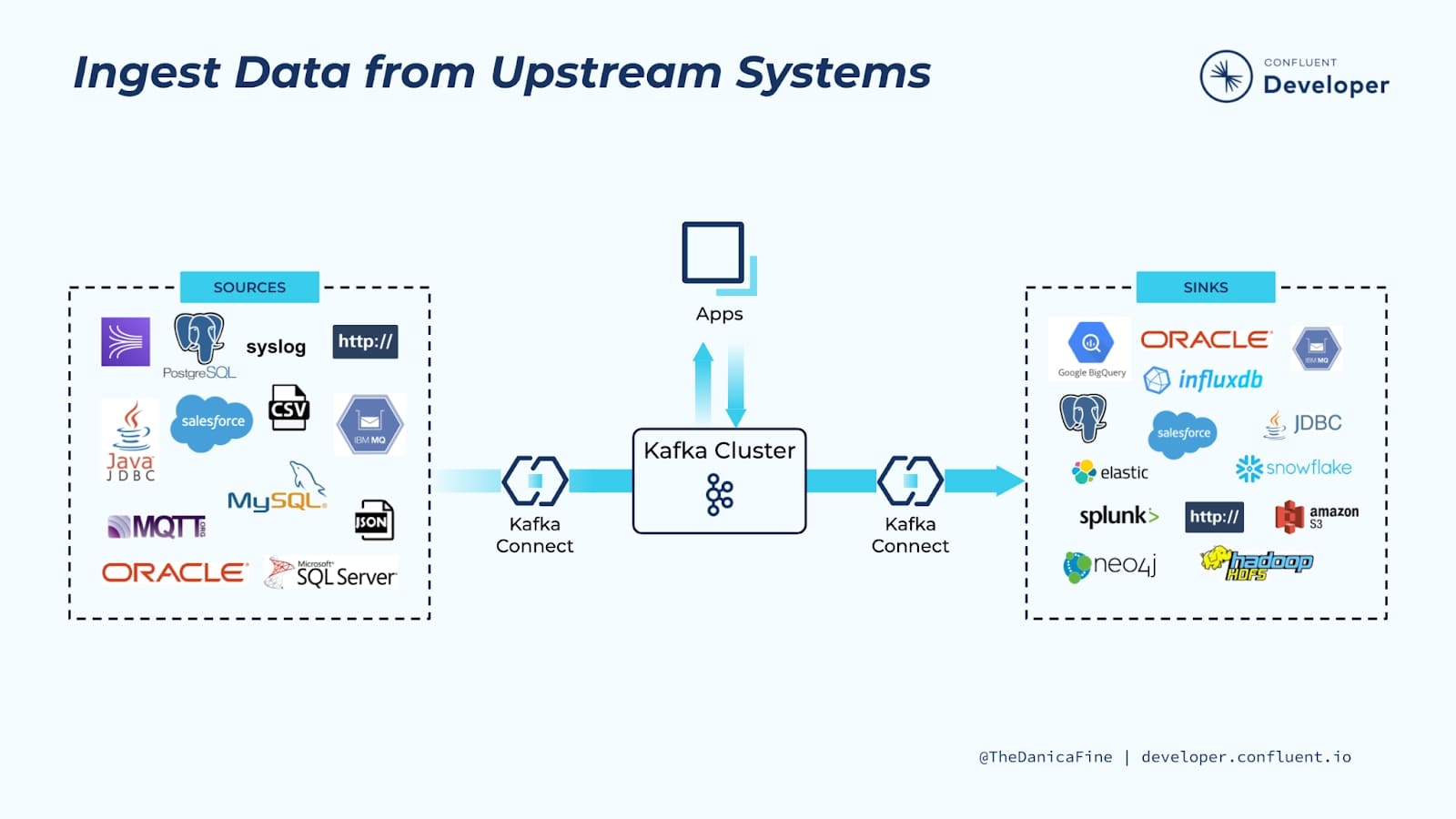
🔌 Kafka Connect 개요 Apache Kafka Connect는 카프카와 외부 시스템 간의 데이터를 안정적이고 확장 가능하게 스트리밍하기 위한 프레임워크입니다. 복잡한 코드 작성 없이 다양한 데이터 소스와 카프카를 손쉽게 연결할 수 있어, 데이터 파이프라인
6.카프카 관리툴의 종류와 특징 비교
Apache Kafka는 대용량 실시간 데이터 처리를 위한 분산 이벤트 스트리밍 플랫폼으로, 전 세계 수많은 기업에서 사용되고 있습니다. 하지만 Kafka를 효율적으로 관리하고 모니터링하는 것은 쉬운 일이 아닙니다. CLI 명령어만으로는 클러스터의 상태를 파악하고 문제
7.Kafka-UI란? 설치 및 사용법

Apache Kafka를 운영하면서 CLI 명령어만으로 클러스터를 관리하고 모니터링하는 것은 쉽지 않습니다. 토픽의 메시지를 확인하거나, 컨슈머 그룹의 상태를 점검하고, 브로커의 상태를 모니터링하는 일련의 작업들이 번거롭고 시간이 많이 소요되죠.이런 문제를 해결하기 위
8.카프카 스키마 레지스트리(Kafka Schema Registry)란?

현대의 데이터 파이프라인에서 Apache Kafka는 필수적인 메시징 플랫폼이 되었습니다. 하지만 Kafka를 운영하다 보면 프로듀서와 컨슈머 간의 데이터 형식 불일치로 인한 문제에 직면하게 됩니다. 이러한 문제를 해결하기 위해 등장한 것이 바로 스키마 레지스트리(Sc
9.카프카 server.properties 설정 가이드

Apache Kafka는 대용량의 실시간 데이터 스트리밍을 처리하는 분산 메시징 시스템입니다. Kafka 브로커의 핵심 설정 파일인 server.properties를 올바르게 구성하는 것은 안정적이고 효율적인 운영의 시작점입니다. 이 가이드에서는 주요 설정 항목들을 카
10.카프카 KSQL(ksqlDB)이란? 스트리밍 SQL로 실시간 데이터 처리하기

ksqlDB(이전 명칭: KSQL, Kafka SQL)는 Apache Kafka를 위한 스트리밍 SQL 엔진입니다. SQL 인터페이스를 제공하여 개발자들이 익숙한 SQL 구문으로 Kafka에서 실시간 스트리밍 처리를 쉽게 할 수 있도록 도와줍니다.2017년 Conflu
11.카프카 컨슈머 그룹(Kafka Consumer Group)이란?

Apache Kafka를 활용한 분산 메시징 시스템에서 컨슈머 그룹(Consumer Group)은 효율적이고 안정적인 메시지 처리를 위한 핵심 개념입니다. 이 글에서는 컨슈머 그룹의 개념과 동작 원리, 그리고 실무에서 알아야 할 중요한 특징들을 살펴보겠습니다.컨슈머 그
12.카프카 CLI 명령어 핵심정리

Apache Kafka를 효과적으로 관리하고 운영하기 위해서는 CLI(Command Line Interface) 도구에 대한 이해가 필수입니다. 카프카는 다양한 쉘 스크립트를 제공하여 토픽 관리, 메시지 송수신, 컨슈머 그룹 관리 등을 명령어로 수행할 수 있습니다. 이
13.카프카에 메시지를 Publish하는 방법 완벽 가이드

Apache Kafka는 대용량 실시간 데이터 스트리밍을 처리하기 위한 분산 이벤트 스트리밍 플랫폼입니다. 이 가이드에서는 Kafka에 메시지를 효과적으로 발행(Publish)하는 방법을 단계별로 알아보겠습니다.Kafka 아키텍처 이해하기(2. Producer 설정 방
14.카프카에 SUB하는 방법 완벽 가이드

Apache Kafka는 대용량 실시간 데이터 스트리밍을 처리하기 위한 분산 이벤트 스트리밍 플랫폼입니다. Kafka에서 데이터를 소비(구독)하는 방법을 이해하는 것은 효과적인 데이터 파이프라인 구축의 핵심입니다.Kafka Consumer 기본 개념(2. Consume
15.카프카 토픽 설정 가이드와 파티션 전략 완벽 가이드
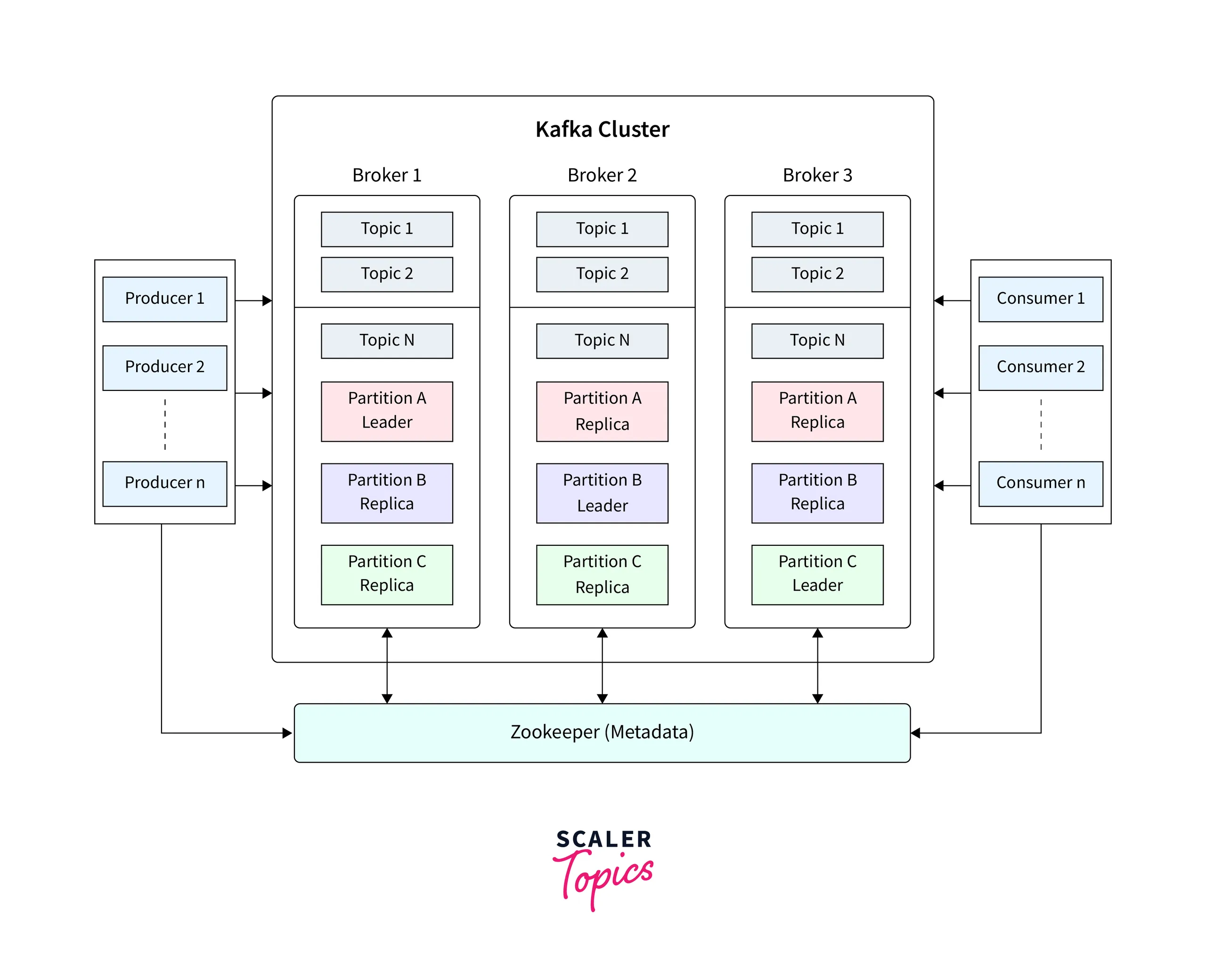
Apache Kafka는 현대적인 데이터 스트리밍 플랫폼의 핵심으로, 대규모 실시간 데이터를 효율적으로 처리할 수 있습니다. 이 글에서는 Kafka의 토픽 설정과 파티션 전략에 대한 모범 사례를 살펴보겠습니다.Kafka ArchitectureKafka는 토픽(Topic
16.카프카 프로듀서 애플리케이션 만들기: 완벽 가이드

Apache Kafka는 대규모 실시간 데이터 스트리밍을 위한 강력한 플랫폼입니다. 이 글에서는 Kafka 프로듀서 애플리케이션을 처음부터 만드는 방법을 단계별로 살펴보겠습니다.Kafka 프로듀서란?(2. 개발 환경 설정(3. 기본 프로듀서 구현 (Java)(4. Sp
17.Kafka 토픽의 키(key) 설정
Kafka에서 키(key) 는 단순한 “식별자”가 아니라, (1) 어떤 파티션에 저장될지와 (2) 그 파티션 내부에서 순서가 어떻게 보장될지를 결정하는 핵심 설계 포인트입니다. 같은 키는 같은 파티션으로 라우팅되므로, 키 전략을 잘못 잡으면 핫 파티션(쏠림), 처리량
18.Kafka 토픽 키(key) 설정 전략: 10분 완독 가이드 (Java + AWS MSK 기준)

Kafka에서 키(key) 는 단순한 “식별자”가 아니라, 파티션 라우팅(부하 분산) 과 파티션 내 순서 보장을 동시에 결정하는 설계 레버입니다. 잘 잡으면 확장성이 좋아지고, 잘못 잡으면 핫 파티션/지연/리밸런스 폭탄/확장 불가로 이어집니다. Source키가 있으면(
19.Apache Kafka Streams란? (개념부터 실전 사용 예까지)

Kafka Streams는 카프카 클러스터에 저장된 데이터를 입력/출력으로 삼아 “애플리케이션 내부에서” 스트림 처리를 수행하는 라이브러리라는 점이 핵심입니다. SourceKafka Streams는 “Kafka 토픽을 입력으로 받아(consume) 변환/집계/조인/윈도
20.핀테크 실무 관점으로 보는 개념 + 적용 패턴(Java)
Kafka Streams는 Kafka 토픽을 입력으로 받아 애플리케이션 내부에서 스트림 처리(변환/집계/조인)를 수행하고, 결과를 다시 Kafka 토픽으로 내보내는 JVM 라이브러리입니다. “별도 스트림 처리 클러스터 없이(예: Flink 클러스터 운영 없이) 서비스처
21.Apache Kafka Connect 설치 및 운영환경 셋팅 (실전 가이드)

Kafka Connect는 “소스 시스템(DB, 파일, SaaS 등) → Kafka” 또는 “Kafka → 싱크 시스템(검색엔진, 스토리지 등)”으로 데이터를 코드 최소화로 이동시키는 프레임워크입니다. 운영 관점에서는 Distributed 모드(클러스터 구성)로 띄우고
22.Debezium이란? (CDC로 데이터 “변화”를 스트리밍하는 방법) + 다양한 사용 예시

서비스를 운영하다 보면 “DB는 단일 진실의 원천(Source of Truth)인데, 검색(Elasticsearch), 캐시(Redis), 분석 파이프라인, 다른 마이크로서비스 데이터까지 항상 최신으로 맞추기”가 정말 어렵습니다.Debezium은 이런 문제를 CDC(C
23.MySQL → Debezium → Kafka Connect 단계별 실습 가이드 (Docker Compose 포함)
이 글은 로컬 환경에서 MySQL binlog 기반 CDC(Change Data Capture) 를 구성해, Debezium 커넥터가 변경 이벤트를 Kafka 토픽으로 흘려보내는 것까지를 “끝까지” 실습하는 가이드입니다. Debezium은 보통 Apache Kafka