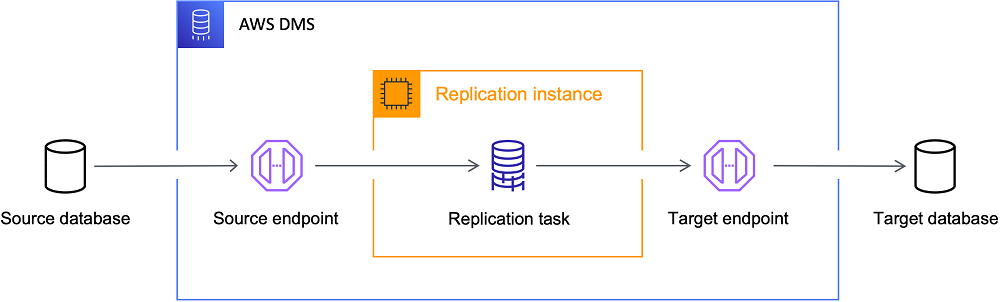
AWS DMS란?
AWS DMS(Database Migration Service)는 관계형 데이터베이스, 데이터 웨어하우스, NoSQL 데이터베이스 및 기타 유형의 데이터 스토어를 AWS 클라우드로 안전하게 마이그레이션할 수 있는 관리형 서비스입니다. AWS DMS는 데이터베이스 마이그레이션을 위한 간편하면서도 강력한 솔루션을 제공하며, 마이그레이션 과정에서 서비스 중단 시간을 최소화할 수 있습니다.
AWS DMS의 주요 특징:
- 데이터베이스 마이그레이션 설정 및 작업이 간단
- 사용한 리소스에 대해서만 비용 지불
- 다양한 데이터베이스 엔진 간 마이그레이션 지원 (이기종 마이그레이션)
- 지속적인 데이터 복제 가능 (CDC - Change Data Capture)
AWS DMS는 초기 데이터 로드뿐만 아니라 변경 데이터 캡처(CDC)를 통해 소스 데이터베이스에서 발생하는 지속적인 변경사항을 대상 데이터베이스에 적용할 수 있어, 실시간에 가까운 데이터 동기화가 가능합니다.

AWS DMS의 주요 기능
1. 다양한 데이터 소스 및 대상 지원
AWS DMS는 다음과 같은 다양한 데이터베이스를 지원합니다:
소스 데이터베이스:
- Oracle
- SQL Server
- MySQL/MariaDB
- PostgreSQL
- MongoDB
- SAP
- DB2
대상 데이터베이스:
- 위의 모든 데이터베이스
- Amazon Redshift
- Amazon DynamoDB
- Amazon S3
- Kinesis Data Streams
- Apache Kafka
- Elasticsearch
2. 최소한의 다운타임으로 마이그레이션
AWS DMS는 소스 데이터베이스의 가용성에 거의 영향을 주지 않으면서 데이터를 안전하게 마이그레이션합니다. 초기 로드 중에도 소스 데이터베이스의 변경 사항을 캡처하여 대상 데이터베이스에 적용함으로써 다운타임을 최소화합니다.
3. 지속적인 데이터 복제 (CDC)
CDC(Change Data Capture)를 통해 소스 데이터베이스에서 발생하는 지속적인 변경사항을 캡처하여 대상에 적용할 수 있습니다. 이는 다음과 같은 용도로 활용될 수 있습니다:
- 데이터 웨어하우스 구축 및 유지
- 재해 복구 시나리오
- 데이터 동기화
- 데이터 레이크 구축
4. 스키마 변환 지원
AWS Schema Conversion Tool(SCT)과 함께 사용하면 소스 데이터베이스 스키마를 대상 데이터베이스의 호환 가능한 형식으로 자동 변환할 수 있습니다.
데이터브릭스 Delta Lake란?

Delta Lake는 데이터브릭스에서 개발한 오픈 소스 스토리지 레이어로, 데이터 레이크에 신뢰성을 제공합니다. 기존 데이터 레이크 위에서 작동하며 Apache Spark API와 완벽하게 호환됩니다.
Delta Lake의 주요 특징:
1. ACID 트랜잭션
- 직렬화 가능한 격리 수준 보장
- 사용자가 일관된 데이터를 볼 수 있도록 함
2. 확장 가능한 메타데이터 처리
- Spark의 분산 처리 능력을 활용
- 페타바이트 규모의 테이블과 수십억 개의 파일 처리 가능
3. 스트리밍 및 배치 통합
- Delta Lake의 테이블은 배치 테이블이면서 동시에 스트리밍 소스 및 싱크로 작동
- 스트리밍 데이터 수집, 배치 백필, 대화형 쿼리 모두 지원
4. 스키마 적용
- 수집 중 잘못된 레코드 삽입 방지를 위한 자동 스키마 변형 처리
5. 타임 트래블 (Time Travel)
- 데이터 버전 관리 지원
- 롤백, 전체 기록 감사 추적, 재현 가능한 ML 실험 가능
6. 업서트(Upsert) 지원
- MERGE 명령을 통해 데이터 레이크의 레코드를 효율적으로 업서트 및 삭제 가능
- CDC 데이터 파이프라인 구축 간소화
AWS DMS와 데이터브릭스 연동 방법
AWS DMS와 데이터브릭스를 연동하면 트랜잭션 데이터를 지속적으로 데이터 레이크로 이동시키고, 이를 분석 및 AI에 활용할 수 있는 강력한 파이프라인을 구축할 수 있습니다. 이 연동 과정은 다음과 같은 아키텍처로 구성됩니다:
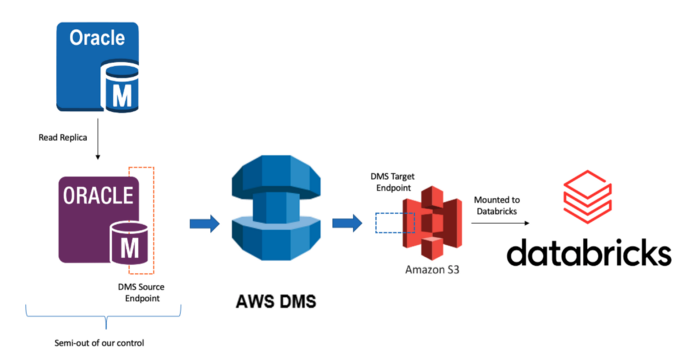
연동 구성 단계
1. AWS DMS 설정
-
복제 인스턴스 생성
- AWS DMS 콘솔에서 복제 인스턴스 생성
- 적절한 인스턴스 크기 및 네트워크 설정 구성
-
엔드포인트 생성
- 소스 데이터베이스 엔드포인트 생성 (MySQL, PostgreSQL 등)
- 대상 S3 버킷 엔드포인트 생성
-
복제 작업 구성
- 초기 로드 작업: 전체 데이터 로드
- CDC 작업: 변경 데이터 지속적 캡처
-
트랜잭션 로그 활성화
- MySQL의 경우: binlog 설정
Copycall mysql.rds_set_configuration('binlog retention hours', 24);- binlog_format = ROW
- binlog_row_image = FULL
-
S3 출력 형식 구성
- 데이터 형식: CSV 또는 Parquet (Parquet 권장)
- CDC 배치 간격 및 최소 파일 크기 설정
- 타임스탬프 컬럼 이름 지정
2. 데이터브릭스 Delta Lake 설정
-
S3 마운트 구성
- 데이터브릭스에서 S3 버킷 마운트
Copydbutils.fs.mount( source = "s3a://<your-bucket>", mount_point = "/mnt/your-mount-name", extra_configs = {"fs.s3a.access.key": access_key, "fs.s3a.secret.key": secret_key} ) -
초기 데이터 로드
- S3에서 초기 로드 파일을 읽어 Delta 테이블 생성
Copy# CSV 파일을 읽어 Delta 테이블로 저장 df = spark.read.option("header", True).option("inferSchema", True).csv("/mnt/your-mount/initial-load/") df.write.format("delta").save("/delta/your-table") # Delta 테이블 생성 spark.sql("CREATE TABLE your_table USING DELTA LOCATION '/delta/your-table/'") -
변경 데이터 처리 (CDC)
- DLT(Delta Live Tables)를 사용한 CDC 처리
- 또는 Delta Lake의 MERGE INTO 명령을 사용한 변경 데이터 적용
실제 구현 예제
다음은 AWS DMS에서 S3로 내보낸 CDC 데이터를 데이터브릭스의 Delta Lake에 적용하는 코드 예제입니다:
1. DLT(Delta Live Tables)를 사용한 CDC 처리
Copyimport dlt
from pyspark.sql.functions import *
# CDC 소스 데이터 정의
@dlt.table
def customer_cdc_raw():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/mnt/s3-bucket/customer/")
.withColumn("_ingest_file_name", input_file_name())
)
# CDC 변경 데이터 적용
@dlt.table
def customers():
return (
dlt.apply_changes(
target = "customers",
source = "customer_cdc_raw",
keys = ["customer_id"],
sequence_by = "dms_timestamp",
ignore_null_updates = True,
apply_as_deletes = expr("op = 'D'"),
except_column_list = ["op", "dms_timestamp"]
)
)
2. SQL을 사용한 DLT 방식
CopyCREATE STREAMING LIVE TABLE customer_cdc_raw
COMMENT "Raw customer change data from AWS DMS"
AS SELECT *, input_file_name() AS _ingest_file_name
FROM cloud_files('/mnt/s3-bucket/customer/', 'csv', map('header', 'true'));
CREATE STREAMING LIVE TABLE customers
COMMENT "Customers table with change data applied"
AS
APPLY CHANGES INTO LIVE.customers
FROM STREAM(LIVE.customer_cdc_raw)
KEYS (customer_id)
APPLY AS DELETE WHEN op = 'D'
SEQUENCE BY dms_timestamp
COLUMNS * EXCEPT (op, dms_timestamp);
3. MERGE INTO를 사용한 전통적인 방식
Copy# CDC 변경 데이터 읽기
changes_df = spark.read.csv("dbfs:/mnt/s3-bucket/customer",
inferSchema=True,
header=True)
changes_df.createOrReplaceTempView("customer_changes")
# MERGE 쿼리 실행
spark.sql("""
MERGE INTO customers target
USING (
SELECT
op,
latest_changes.customer_id,
name,
email,
address,
create_date,
last_update
FROM customer_changes latest_changes
INNER JOIN (
SELECT
customer_id,
max(last_update) AS max_date
FROM customer_changes
GROUP BY customer_id
) cm
ON latest_changes.customer_id = cm.customer_id
AND latest_changes.last_update = cm.max_date
) as source
ON source.customer_id = target.customer_id
WHEN MATCHED AND source.op = 'D' THEN DELETE
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
마치며
AWS DMS와 데이터브릭스 Delta Lake를 연동하면 실시간에 가까운 데이터 파이프라인을 구축할 수 있습니다. 이를 통해 다음과 같은 다양한 이점을 얻을 수 있습니다:
- 데이터 일관성: ACID 트랜잭션을 통해 데이터 레이크의 일관성 보장
- 실시간 분석: 거의 실시간으로 업데이트되는 데이터에 대한 분석 가능
- 간소화된 아키텍처: 복잡한 ETL 프로세스 대신 선언적 CDC 처리 방식 사용
- 확장성: 대량의 데이터와 높은 변경 속도에도 대응 가능한 아키텍처
- 낮은 운영 비용: 서버리스 아키텍처와 사용한 만큼만 지불하는 비용 구조
AWS DMS와 데이터브릭스 Delta Lake를 활용하면 데이터 엔지니어링 팀은 복잡한 데이터 파이프라인을 더 쉽게 구축하고 유지보수할 수 있으며, 데이터 과학자와 분석가는 더 신선하고 일관된 데이터에 접근할 수 있게 됩니다.

이제 트랜잭션 데이터베이스의 변경 사항을 실시간으로 추적하고, 이를 데이터 레이크하우스에 반영하여 최신 데이터에 기반한 고급 분석과 AI 모델을 구축할 수 있습니다.
참고 자료:
