databricks
1.데이터브릭스의 델타레이크

오늘날 기업들이 직면한 데이터 문제는 점점 더 복잡해지고 있습니다. 대용량 데이터를 효율적으로 저장하고, 안정적으로 처리하며, 빠르게 분석할 수 있는 인프라가 필요한 시대입니다. 이러한 요구에 부응하여 데이터브릭스(Databricks)는 델타레이크(Delta Lake)
2.데이터브릭스 유니티 카탈로그의 권한 관리: 완벽 가이드
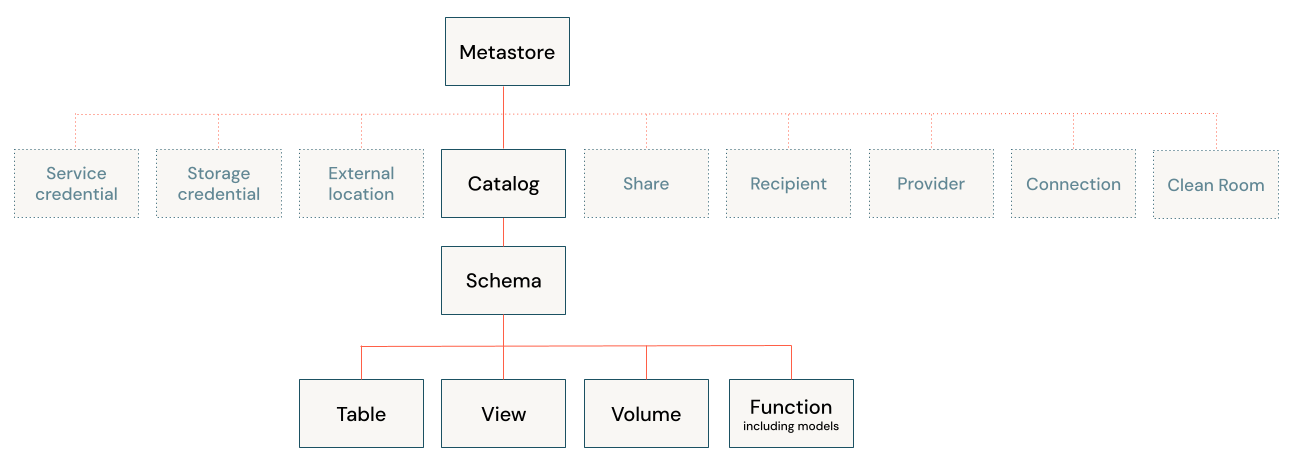
데이터가 조직의 가장 중요한 자산이 된 시대, 데이터에 대한 적절한 접근 제어와 보안은 그 어느 때보다 중요해졌습니다. 데이터브릭스(Databricks)의 유니티 카탈로그(Unity Catalog)는 이러한 데이터 거버넌스의 핵심 요소인 권한 관리를 위한 강력한 솔루션
3.데이터브릭스 Unity Catalog: 데이터와 AI의 통합 거버넌스 솔루션
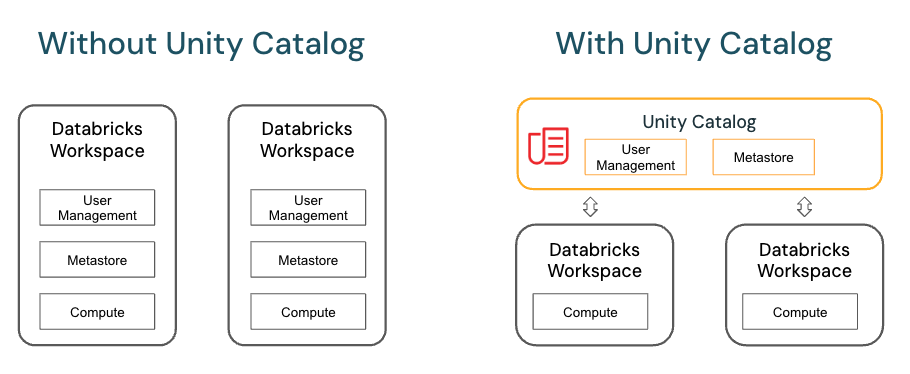
데이터 기반 의사결정이 중요해진 현대 비즈니스 환경에서, 조직들은 날로 증가하는 데이터 자산을 효과적으로 관리하고 보호해야 하는 과제에 직면해 있습니다. 이러한 과제를 해결하기 위해 데이터브릭스(Databricks)는 Unity Catalog라는 강력한 솔루션을 제공하
4.데이터브릭스의 BI 기능: AI가 만나 더욱 강력해진 비즈니스 인텔리전스
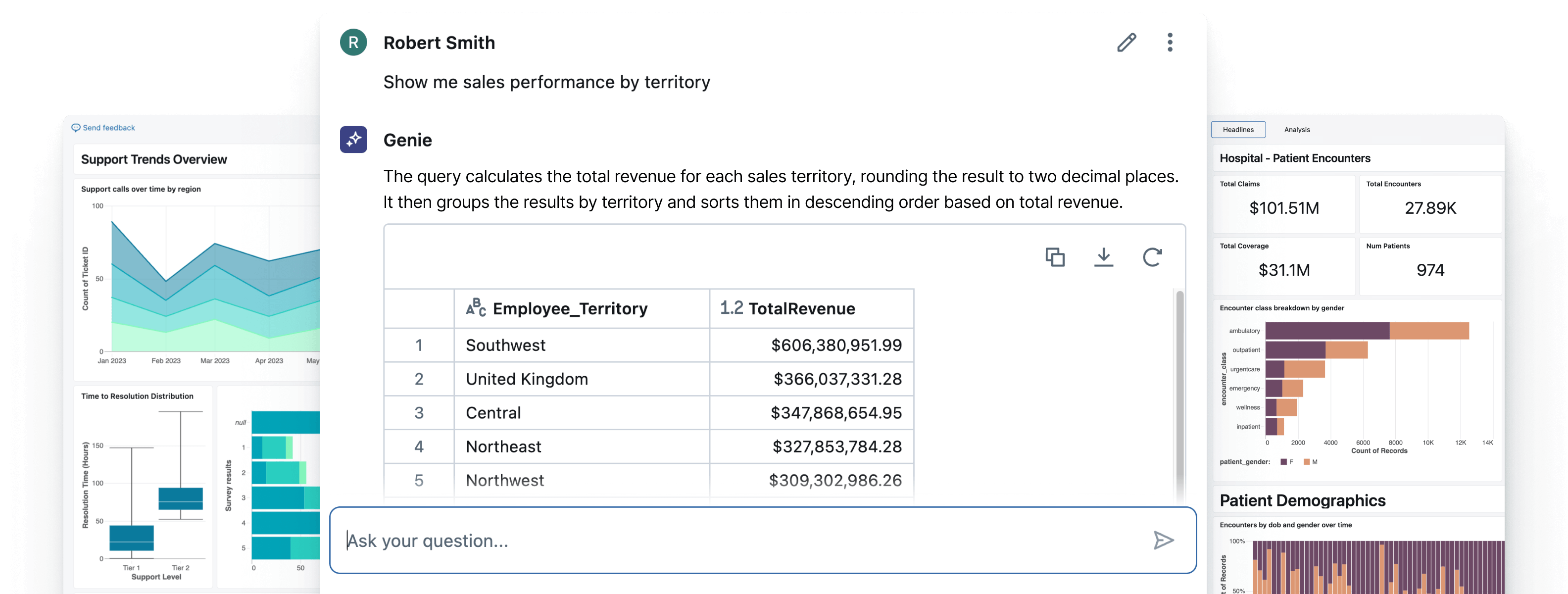
비즈니스 인텔리전스(BI)는 기업이 데이터 기반 의사결정을 내리는 데 핵심적인 역할을 해왔습니다. 그러나 전통적인 BI 도구는 여러 한계에 직면해 있습니다. 데이터 준비에 많은 시간이 소요되고, 기술적 지식이 필요하며, 사전에 정의된 질문에만 답할 수 있다는 제약이 있
5.데이터브릭스(Databricks): 데이터와 AI의 혁신 기업 분석

데이터와 AI가 기업의 성공을 좌우하는 시대에 데이터브릭스(Databricks)는 빠르게 성장하며 업계를 선도하고 있습니다. 2013년 아파치 스파크(Apache Spark)의 원 개발자들에 의해 설립된 이 회사는 단순한 데이터 처리 도구를 넘어 글로벌 데이터, 분석
6.Delta Live Tables: 데이터 파이프라인의 혁신적 접근법
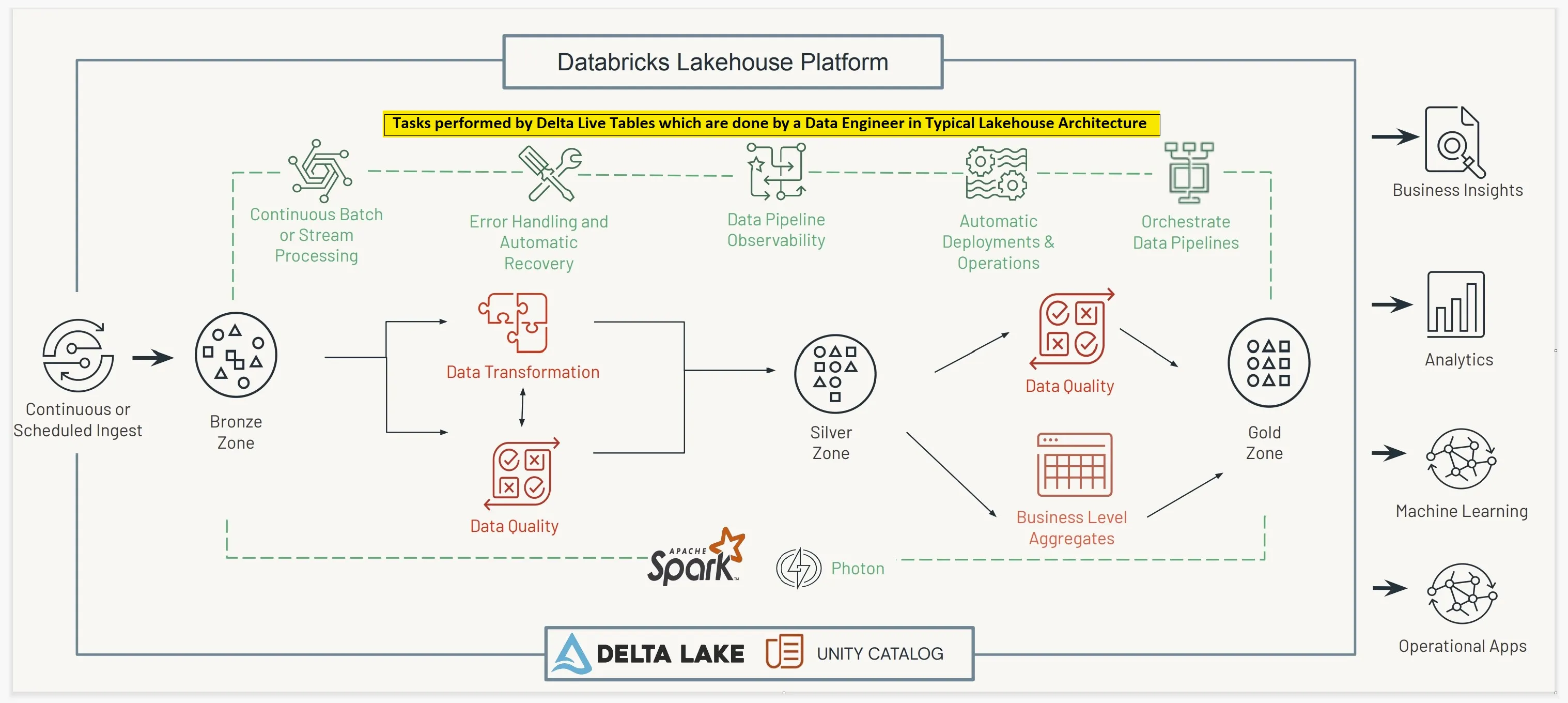
데이터 엔지니어링 분야에서 안정적이고 효율적인 ETL(Extract, Transform, Load) 파이프라인을 구축하는 것은 항상 큰 도전이었습니다. 데이터 소스와 목적지 간의 연결, 데이터 변환, 오류 처리, 모니터링 등을 관리하며 파이프라인을 유지하는 일은 복잡하
7.데이터브릭스(Databricks)의 아키텍처 구성 총정리
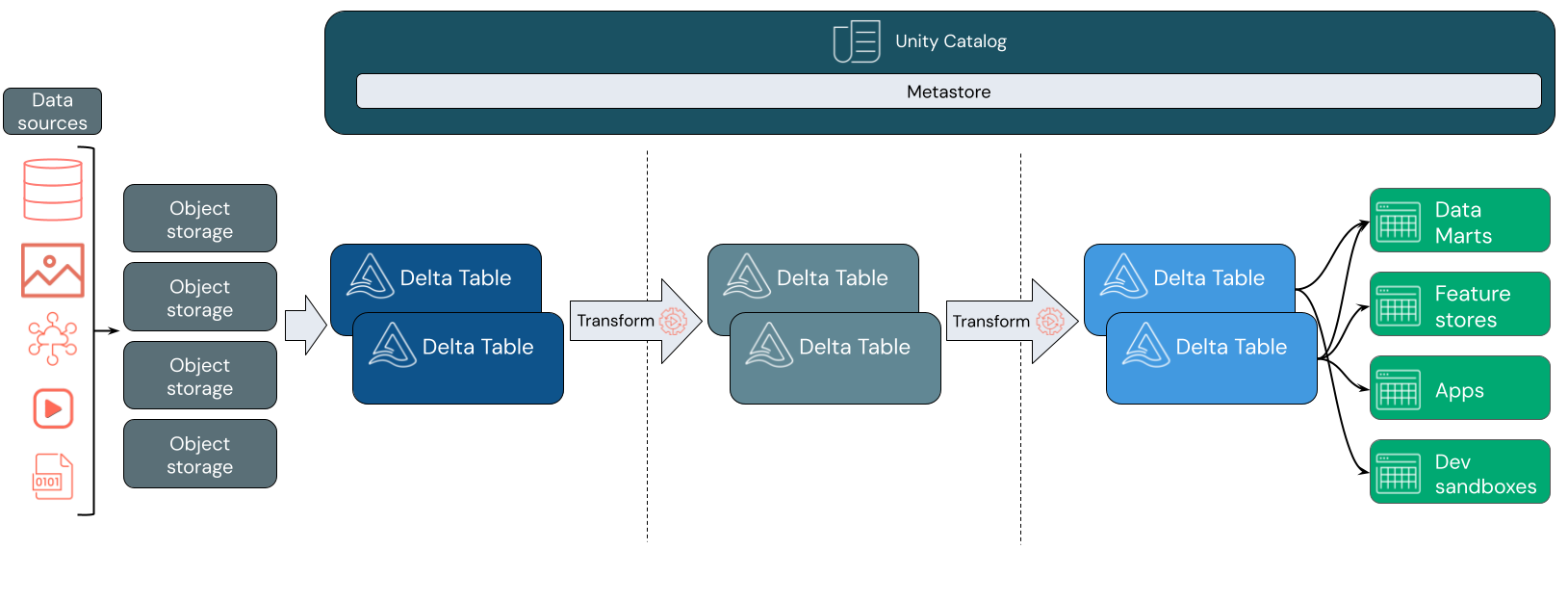
안녕하세요, 오늘은 빅데이터 분석과 머신러닝 워크로드를 처리하는 강력한 플랫폼인 데이터브릭스(Databricks)의 아키텍처 구성에 대해 자세히 알아보겠습니다. 데이터브릭스는 UC Berkeley에서 아파치 스파크를 만든 엔지니어들이 설립한 회사로, 데이터 레이크하우스
8.데이터브릭스의 데이터를 API로 제공하는 방법

데이터브릭스는 빅데이터 처리와 분석을 위한 강력한 플랫폼으로, 기업들이 데이터를 효과적으로 활용할 수 있도록 다양한 기능을 제공합니다. 이 중에서도 데이터브릭스에서 처리된 데이터를 외부 시스템이나 애플리케이션에 API로 제공하는 방법은 매우 중요한 주제입니다. 이 글에
9.데이터브릭스(Databricks)의 워크플로우: 효율적인 데이터 파이프라인 구축의 핵심
데이터브릭스 워크플로우란?데이터브릭스 워크플로우(Databricks Workflows)는 데이터브릭스 데이터 인텔리전스 플랫폼 위에서 데이터, 분석 및 AI 워크로드를 조율하기 위한 통합 오케스트레이션 도구입니다. 복잡한 데이터 파이프라인을 관리하고 자동화하는 방법을
10.데이터브릭스의 모자이크AI, 기업의 생성형 AI 혁신을 위한 완벽한 솔루션
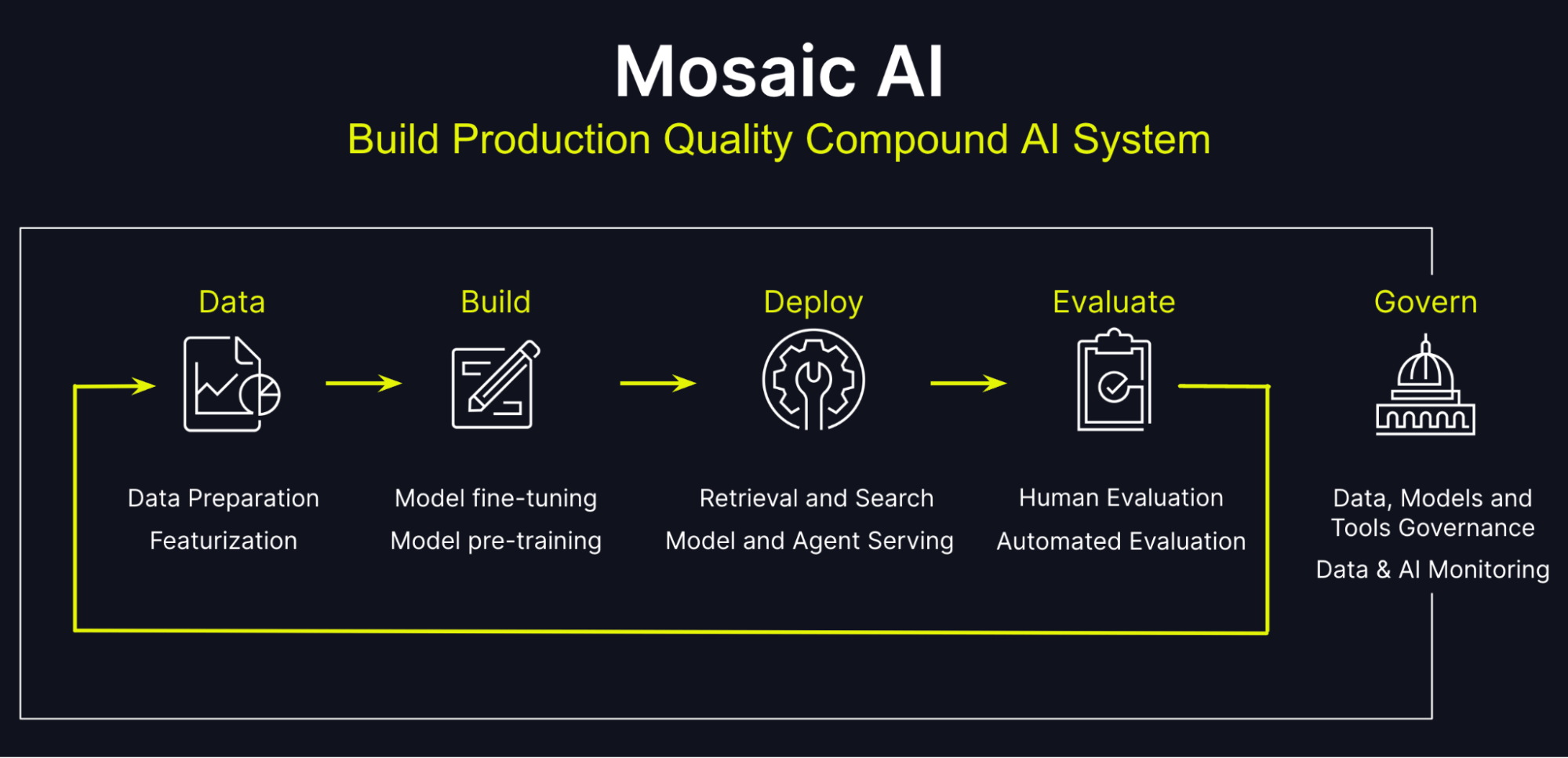
인공지능 기술의 발전과 함께 기업들은 자사의 데이터를 활용하여 생성형 AI 애플리케이션을 구축하고자 하는 니즈가 급증하고 있습니다. 그러나 기업 환경에서 프로덕션 품질의 생성형 AI를 구축하는 것은 데이터 준비, 모델 선택, 훈련, 평가, 배포, 그리고 거버넌스까지 복
11.데이터브릭스 노트북 사용법: 완벽 가이드

데이터브릭스(Databricks)는 빅데이터 분석과 머신러닝을 위한 통합 플랫폼으로, 그 핵심에는 '노트북(Notebook)'이라는 강력한 도구가 있습니다. 이 블로그에서는 데이터브릭스 노트북의 기본 개념부터 고급 기능까지 상세히 알아보겠습니다.데이터브릭스 노트북은 대
12.데이터브릭스의 데이터를 외부에 공유하는 방법

데이터의 가치는 그것이 적재적소에 활용될 때 극대화됩니다. 그러나 현대 비즈니스 환경에서는 조직 내부뿐만 아니라 외부 파트너, 고객, 협력업체와의 데이터 공유가 점점 중요해지고 있습니다. 데이터브릭스(Databricks)는 이러한 필요성을 인식하고 안전하고 효율적인 데
13.데이터브릭스의 테이블과 RDBMS의 테이블: 차이점과 속도 튜닝 방법 완벽 가이드

빅데이터 환경에서 데이터 분석과 처리를 위한 플랫폼으로 데이터브릭스(Databricks)가 널리 사용되고 있습니다. 데이터브릭스는 델타 레이크(Delta Lake)라는 오픈 소스 스토리지 레이어를 기반으로 테이블을 관리하는데, 이는 전통적인 관계형 데이터베이스 관리 시
14.MLOps의 개념과 데이터브릭스에서의 MLOps 구성
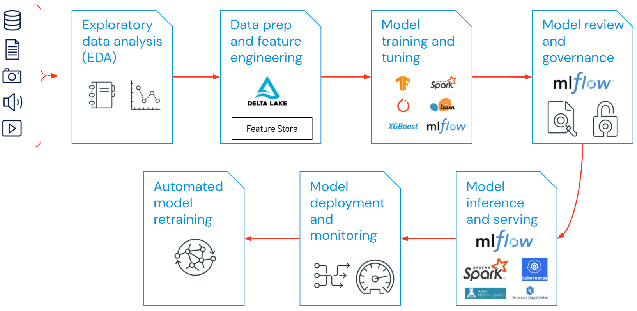
머신러닝 모델을 개발하는 것은 비즈니스 가치를 창출하는 여정의 시작일 뿐입니다. 실제로 모델을 프로덕션 환경에 배포하고 지속적으로 모니터링하며 필요에 따라 업데이트하는 과정은 더 많은 도전 과제를 수반합니다. 이러한 도전을 해결하기 위해 등장한 것이 바로 MLOps입니
15.메달리온 아키텍처와 데이터브릭스에서의 사용 예제
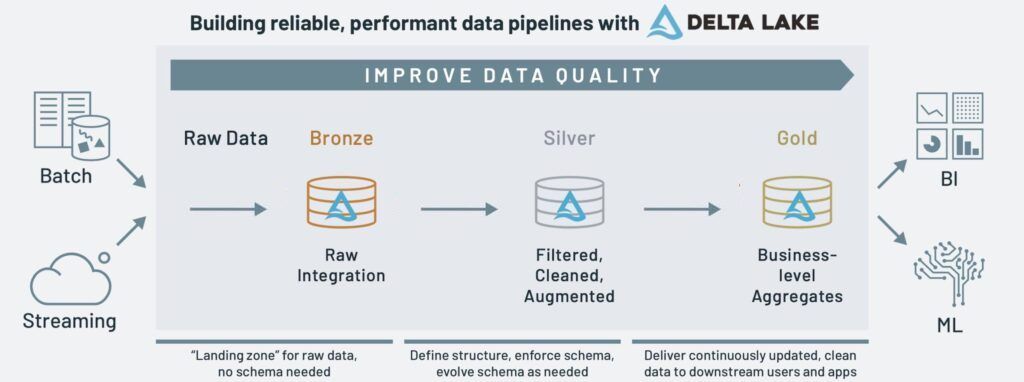
데이터 엔지니어링 분야에서 효율적인 데이터 파이프라인을 구축하는 것은 항상 도전적인 과제입니다. 특히 다양한 소스에서 데이터를 수집하고, 정제하며, 비즈니스 인사이트를 위한 분석용 데이터로 변환하는 과정은 복잡합니다. 이러한 복잡성을 해결하기 위해 등장한 패턴 중 하나
16.데이터브릭스에서 DAG란? DAG 사용법
데이터 엔지니어링과 분석 작업에서 효율적인 워크플로우 관리는 매우 중요합니다. 데이터브릭스(Databricks)에서는 DAG(Directed Acyclic Graph)라는 개념을 통해 복잡한 데이터 처리 작업을 체계적으로, 시각적으로 관리할 수 있습니다. 이 글에서는
17.데이터브릭스의 시스템 테이블
데이터브릭스 시스템 테이블은 계정의 운영 데이터를 분석할 수 있는 Databricks에서 호스팅하는 분석 저장소입니다. 이 테이블들은 system 카탈로그에 위치하며, 계정 전체에서 이루어지는 다양한 활동과 리소스 사용에 대한 이력 정보를 제공합니다. 시스템 테이블을
18.데이터 레이크하우스와 델타 레이크 최적화 가이드(1/3)

이 문서는 Databricks, Apache Spark 및 Delta Lake의 필수 모범 사례와 최적화 기술을 한곳에 모아 제공합니다. 모든 데이터 엔지니어와 데이터 아키텍트가 최적화되고 비용 효율적인 데이터 파이프라인을 설계하고 개발할 때 참고할 수 있는 가이드입니
19.데이터 레이크하우스와 델타 레이크 최적화 가이드(2/3):데이터 스필링, 스큐, 폭발 문제 해결 가이드

Spark SQL 셔플 파티션의 기본 설정 수(즉, 조인, 집계 등과 같은 넓은 변환을 수행하는 데 사용되는 CPU 코어 수)는 200으로, 항상 최적의 값은 아닙니다. 결과적으로 각 Spark 태스크(또는 CPU 코어)에 처리할 많은 양의 데이터가 주어지고, 각 코어
20.데이터 레이크하우스와 델타 레이크 최적화 가이드(3/3):데이터 스키핑, 캐싱, Delta 최적화 및 Databricks 클러스터 구성

처리할 데이터의 양은 쿼리 성능과 직접적인 관련이 있습니다. 따라서 필요한 데이터만 읽고 불필요한 모든 데이터를 건너뛰는 것이 매우 중요합니다. Spark 및 Delta로 적용할 수 있는 데이터 스키핑 및 프루닝 기술은 다음과 같습니다.Delta 데이터 스키핑(http
21.Databricks 로그인 방법 및 SSO 연동 가이드
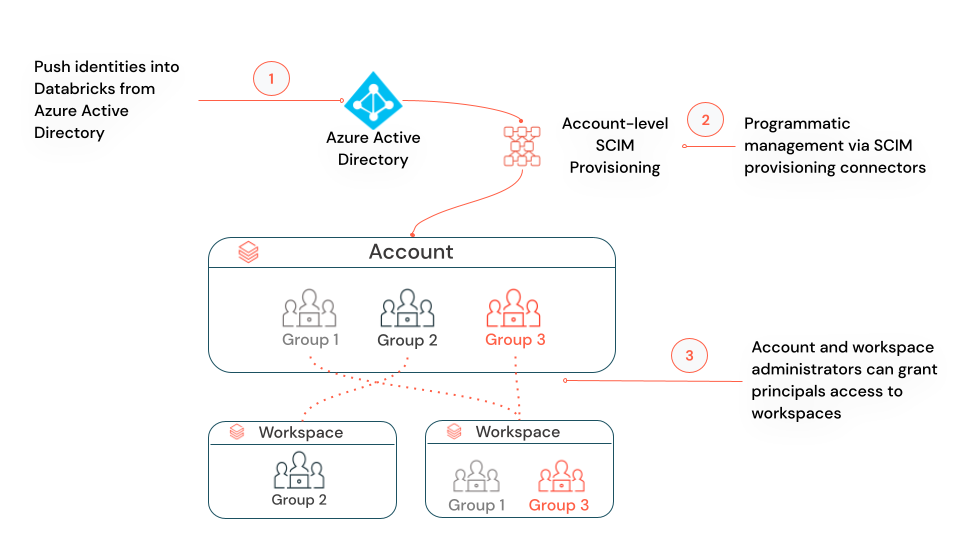
Databricks는 기업들이 데이터 및 AI 워크로드를 효율적으로 실행할 수 있도록 하는 클라우드 기반 데이터 플랫폼입니다. 이 가이드에서는 Databricks에 로그인하는 다양한 방법과 SSO(Single Sign-On)를 연동하는 방법에 대해 자세히 알아보겠습니다
22.데이터브릭스 RAG 사용하기: 기업의 LLM 애플리케이션 품질 향상을 위한 완벽 가이드
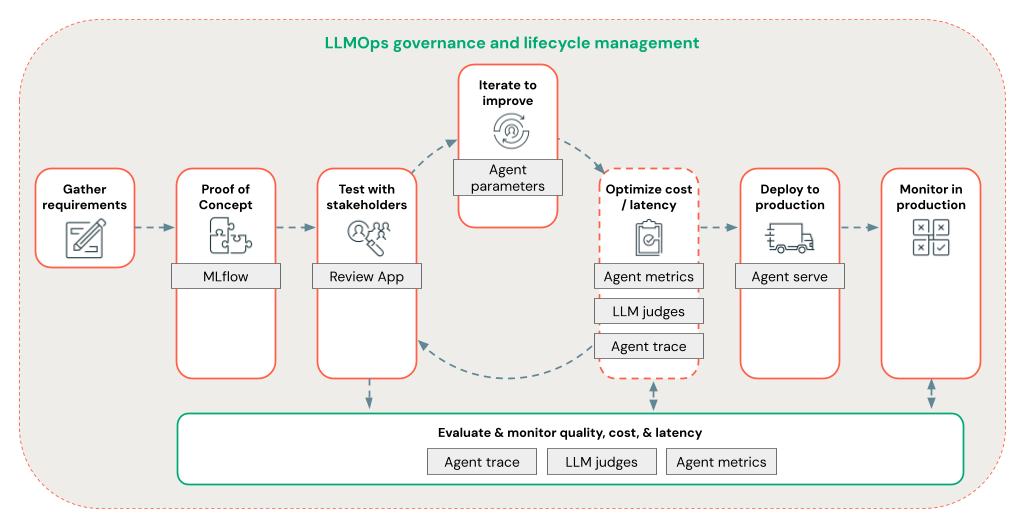
RAG란 무엇인가?(https://www.genspark.ai/agents?id=81bda275-568d-4996-a72f-066d7f18b7bb2. 데이터브릭스 RAG의 특징과 이점(https://www.genspark.ai/agents?id=81b
23.데이터브릭스에서 물리뷰(Materialized View) 사용하기

물리뷰(Materialized View)란?(https://www.genspark.ai/agents?id=81bda275-568d-4996-a72f-066d7f18b7bb2. 물리뷰의 작동 방식(https://www.genspark.ai/agents?
24.AWS DMS란? 데이터브릭스와 연동방법
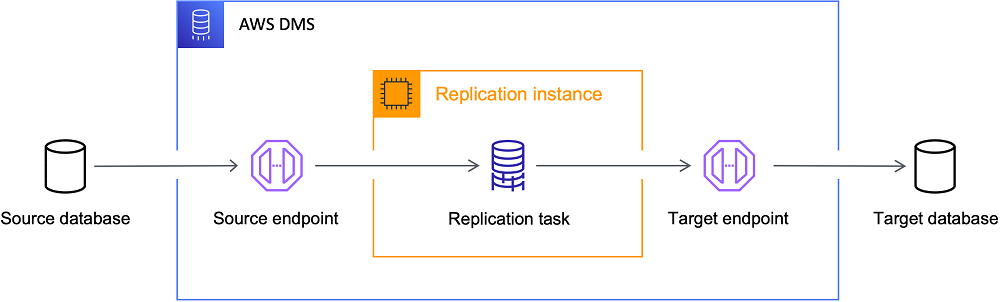
AWS DMS(Database Migration Service)는 관계형 데이터베이스, 데이터 웨어하우스, NoSQL 데이터베이스 및 기타 유형의 데이터 스토어를 AWS 클라우드로 안전하게 마이그레이션할 수 있는 관리형 서비스입니다. AWS DMS는 데이터베이스 마이그
25.데이터 메시[Data Mesh]란? 실제 활용 가이드

Data Mesh Principles and Logical Architecture출처: Martin Fowler – Data Mesh Principles and Logical Architecture Source많은 조직이 데이터 레이크/웨어하우스/레이크하우스를 구축했는
26.📦 Parquet과 Avro란? — 빅데이터 파일 포맷 완전 정복

"데이터 포맷을 잘못 선택하면, 성능과 비용이 10배 차이납니다."빅데이터 엔지니어링에서 파일 포맷 선택은 파이프라인의 성패를 가릅니다.빅데이터 파일 포맷이란?(2. Apache Parquet란?(3. Apache Avro란?(4. 핵심 차이: Row vs Column
27.🗂️ 데이터브릭스의 DBFS란? — Databricks File System
DBFS(Databricks File System) 는 데이터브릭스 환경에서 클라우드 스토리지를 손쉽게 다루기 위한 분산 파일 시스템입니다.이 글에서는 DBFS의 개념부터 구조, 실제 사용법, 그리고 최신 트렌드인 Unity Catalog와의 비교까지 한 번에 정리합니
28.Databricks RAG 기반 AI 앱 구축 가이드
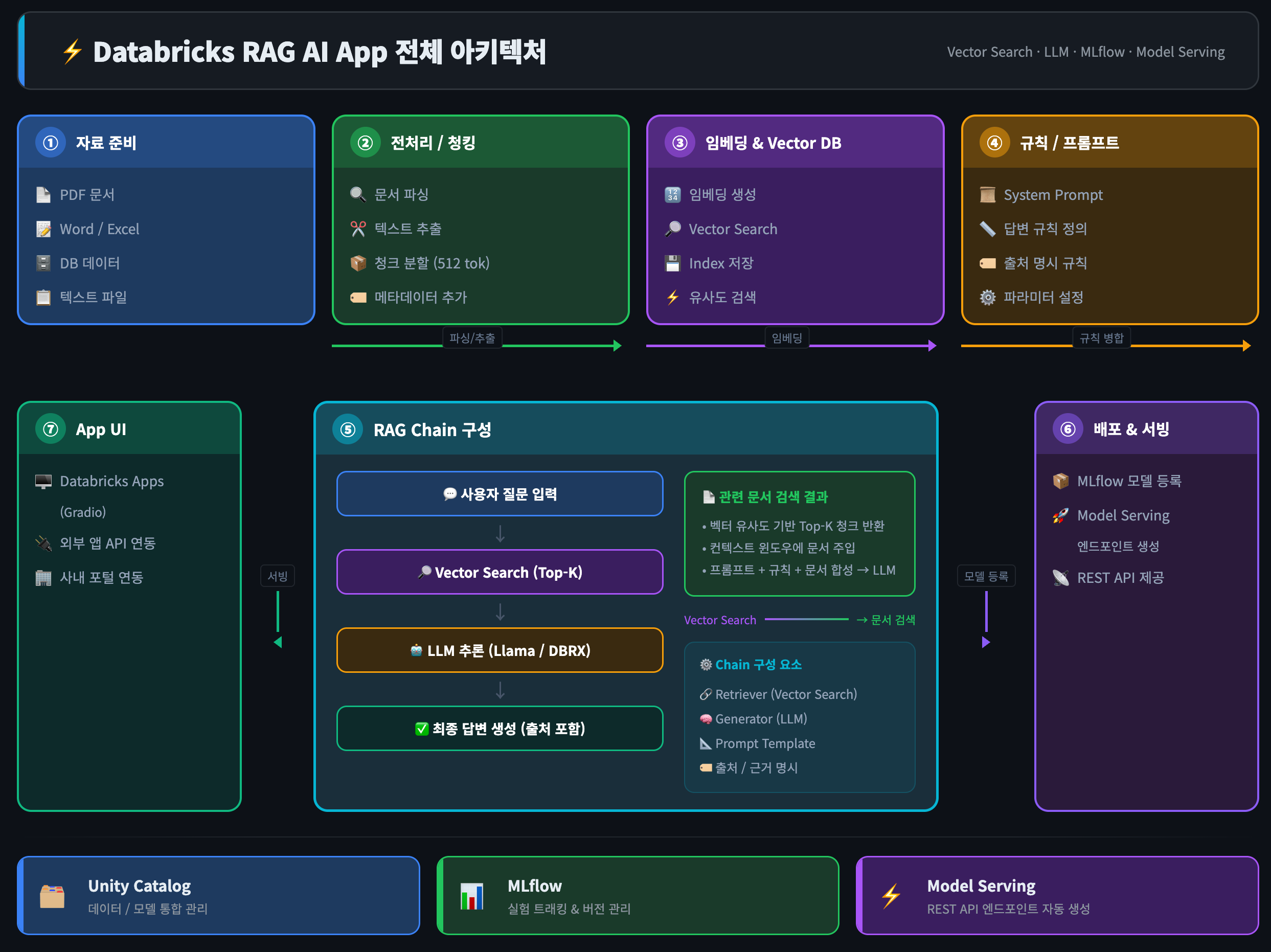
Databricks에서 필요한 것들Unity Catalog - 데이터/모델 관리MLflow - 모델 트래킹Databricks Vector Search - 벡터 DBModel Serving - API 엔드포인트Foundation Model API - LLM (DBRX,
29.데이터브릭스에서 MLflow는 어떻게 동작할까?
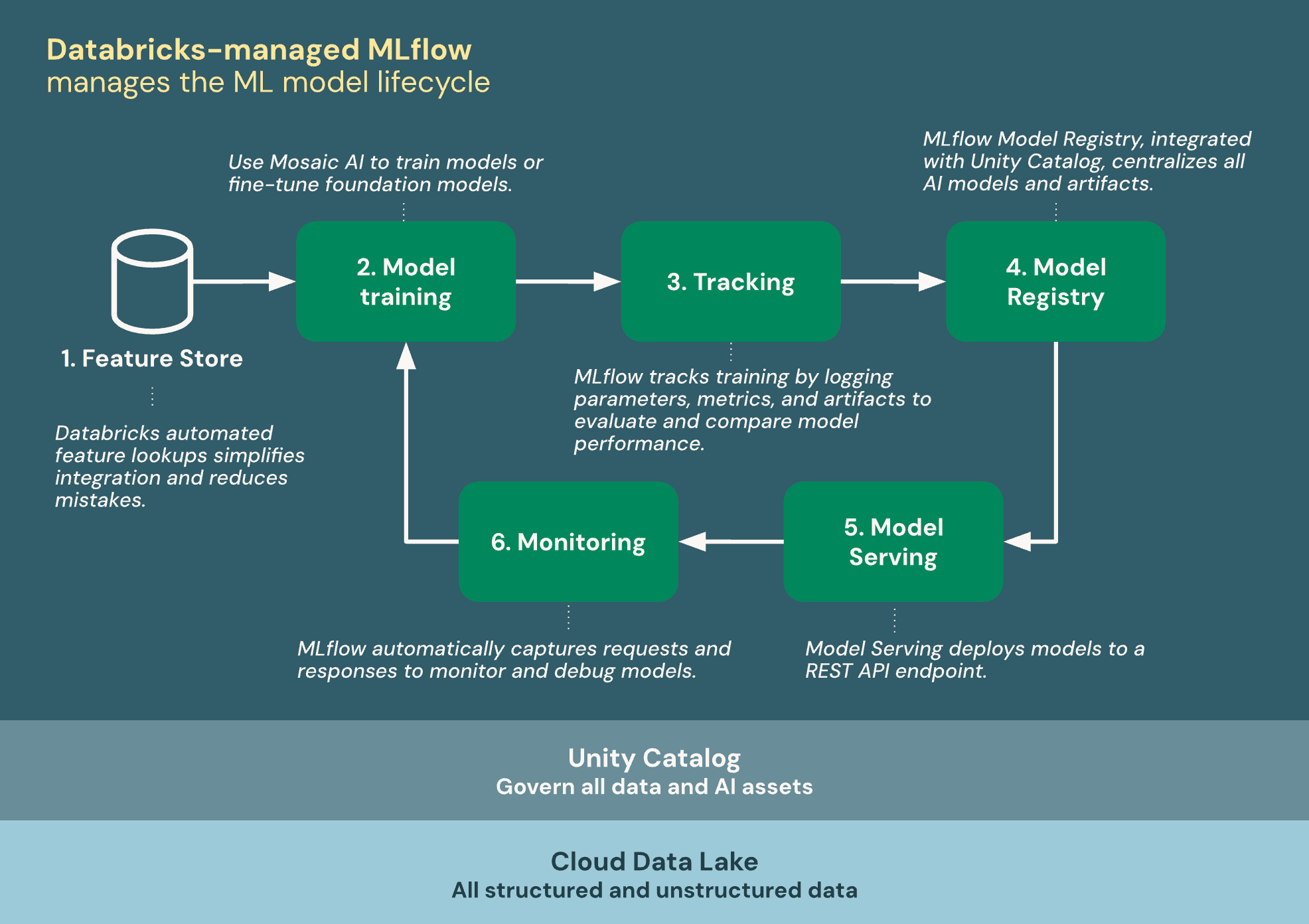
MLOps의 핵심 엔진, MLflow가 Databricks 플랫폼에 어떻게 통합되어 있는지 깊이 파헤쳐봅니다.Databricks 내 MLflow 대시보드 — 실험 추적부터 모델 배포까지 한눈에MLflow는 머신러닝 라이프사이클 전반을 관리하기 위해 Databricks가
30.Databricks AI/BI Genie 완전 정복: 자연어로 데이터와 대화하는 법
데이터를 분석하기 위해 매번 SQL 쿼리를 짜야 했던 시대는 끝났습니다. Databricks가 2024년 GA(정식 출시)한 AI/BI Genie는 "매출 상위 10개 제품 보여줘"라고 입력하면, 자동으로 SQL을 생성하고 결과를 시각화해주는 대화형 분석 도구입니다.이
31.Databricks 시스템 테이블(System Tables) 완전 가이드
마지막 업데이트: 2026년 3월 | 대상: 데이터 엔지니어, 플랫폼 엔지니어, 데이터 아키텍트Databricks 플랫폼을 운영하다 보면 "지금 우리 클러스터는 얼마나 쓰고 있지?", "저 사람이 어떤 테이블에 접근했지?", "이 파이프라인이 왜 이렇게 느리지?"라는
32.Databricks Auto Loader: Directory Listing vs File Notification 완전 비교
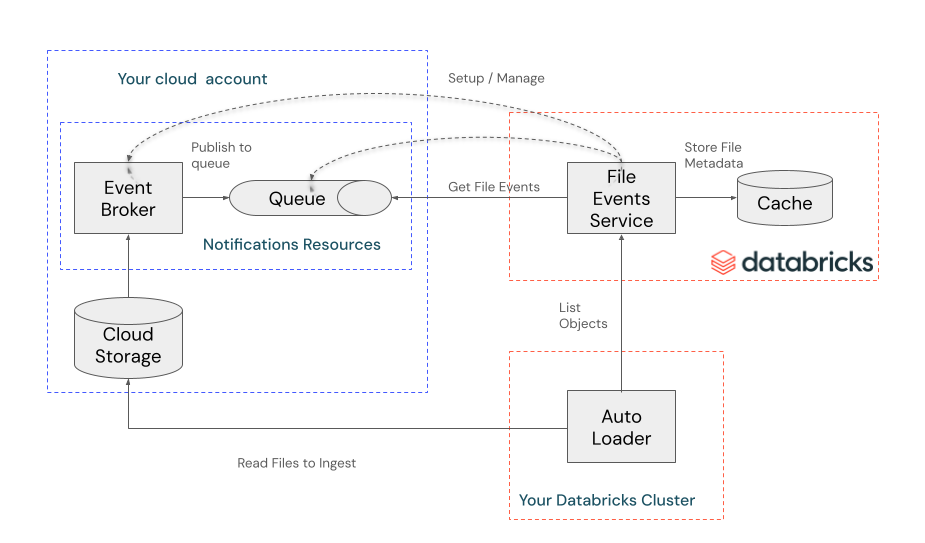
마지막 업데이트: 2026년 3월 | 대상: 데이터 엔지니어, 플랫폼 엔지니어Databricks Auto Loader는 클라우드 오브젝트 스토리지(S3, ADLS, GCS)에 새로 도착하는 파일을 자동으로 감지하고 스트리밍 방식으로 수집하는 핵심 기능이다. 파일을 "어
33.Databricks UDF 성능을 고려한 올바른 사용법
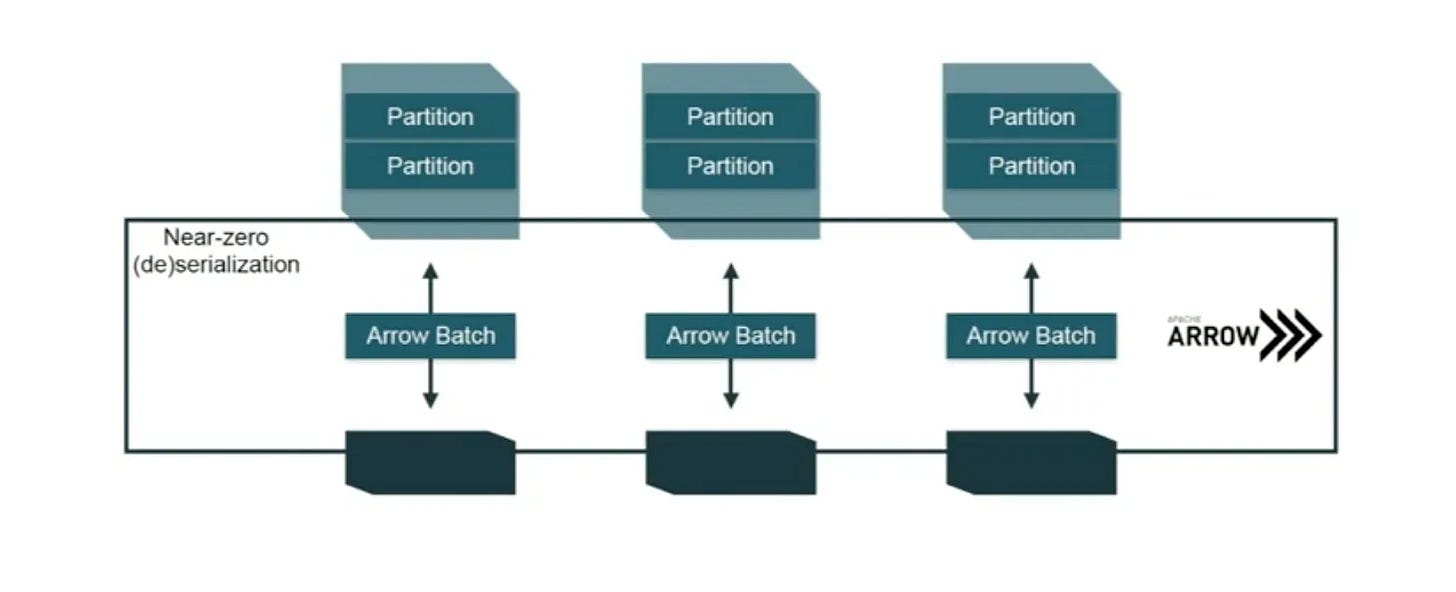
마지막 업데이트: 2026년 3월 | 대상: 데이터 엔지니어, 플랫폼 엔지니어, 분석 엔지니어UDF(User-Defined Function)는 Databricks에서 기본 제공 함수로 표현하기 어려운 비즈니스 로직을 직접 구현할 수 있는 강력한 도구다. 하지만 잘못 사
34.Broadcast Join Optimization 완전 가이드 — Databricks에서 조인 성능을 극대화하는 법
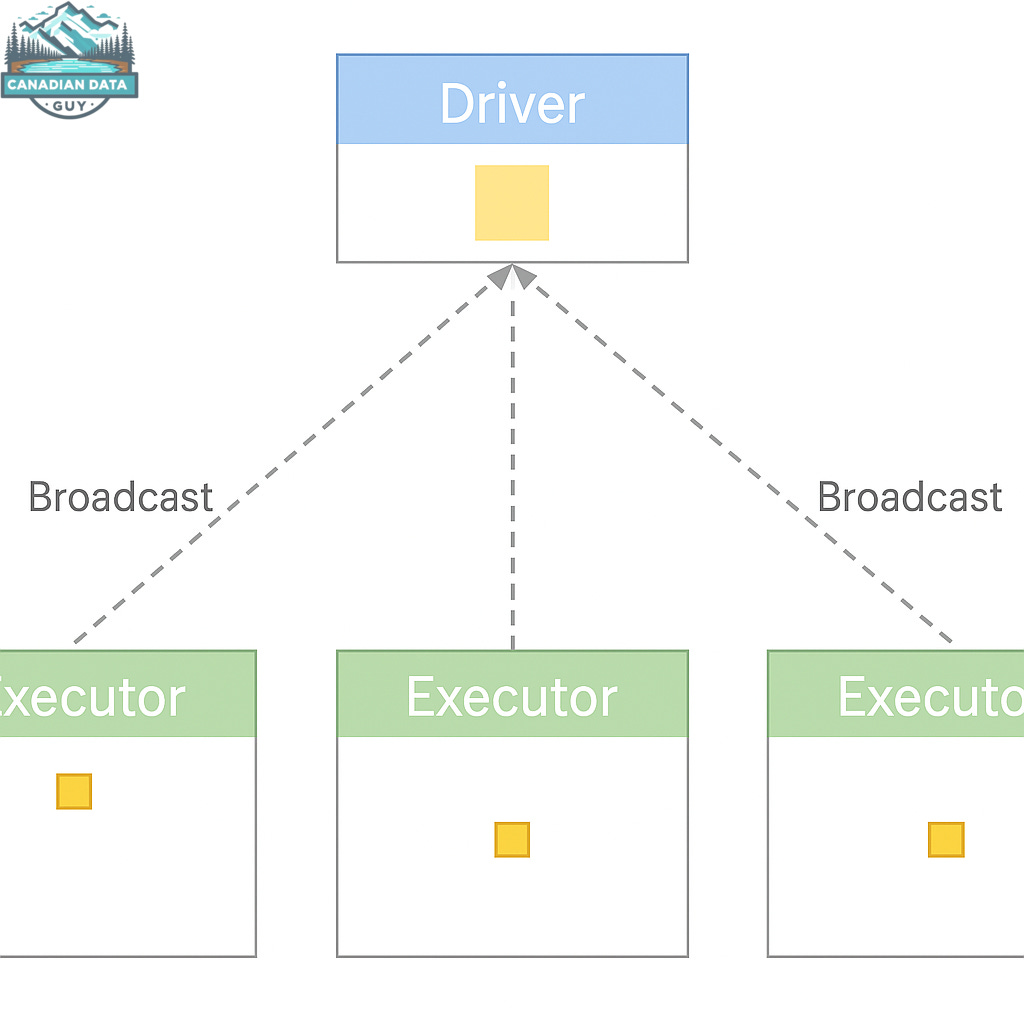
마지막 업데이트: 2026년 3월 | 대상: 데이터 엔지니어, 플랫폼 엔지니어, Spark 성능 튜너대용량 데이터 조인은 Spark/Databricks 워크로드에서 가장 비싼 연산 중 하나다. 수백만 행을 가진 두 테이블을 조인할 때 기본 전략(SortMergeJoin
35.Databricks 메모리 구조와 관리 정책, 오류 대응 완전 가이드
대상 독자: 데이터 엔지니어, Spark 실무자, Databricks 클러스터 운영자난이도: 중급 | 소요 시간: 약 15분Spark 잡이 갑자기 OutOfMemoryError로 죽거나, 멀쩡하던 파이프라인이 특정 데이터 크기를 넘기면서 실패하기 시작했다면, 원인은 거
36.Databricks 메모리 운영 런북: 구조/정책 + 오류 진단/대응 플레이북

장애 접수 5분 안에 확보할 정보10분 트리아지(Driver vs Executor vs Spill/Skew)메모리 구조 “운영자가 필요한 만큼만” (Unified Memory / Off-heap / Overhead)자주 터지는 오류 6종: 증상 → 확인 → 즉시조치 →
37.데이터브릭스로 데이터 가져오기: 방법별 장단점 총정리 (실무 선택 가이드)

데이터브릭스로 “데이터를 가져온다(ingestion)”는 건, 결국 소스(파일/DB/SaaS/메시지버스)의 데이터를 레이크하우스(주로 Delta 테이블) 로 옮겨 분석·ML·서빙까지 이어지게 만드는 일입니다. Databricks는 가장 매니지드(쉬운) 옵션부터 시작하고
38.Databricks의 ZeroBus(Zerobus Ingest)란?
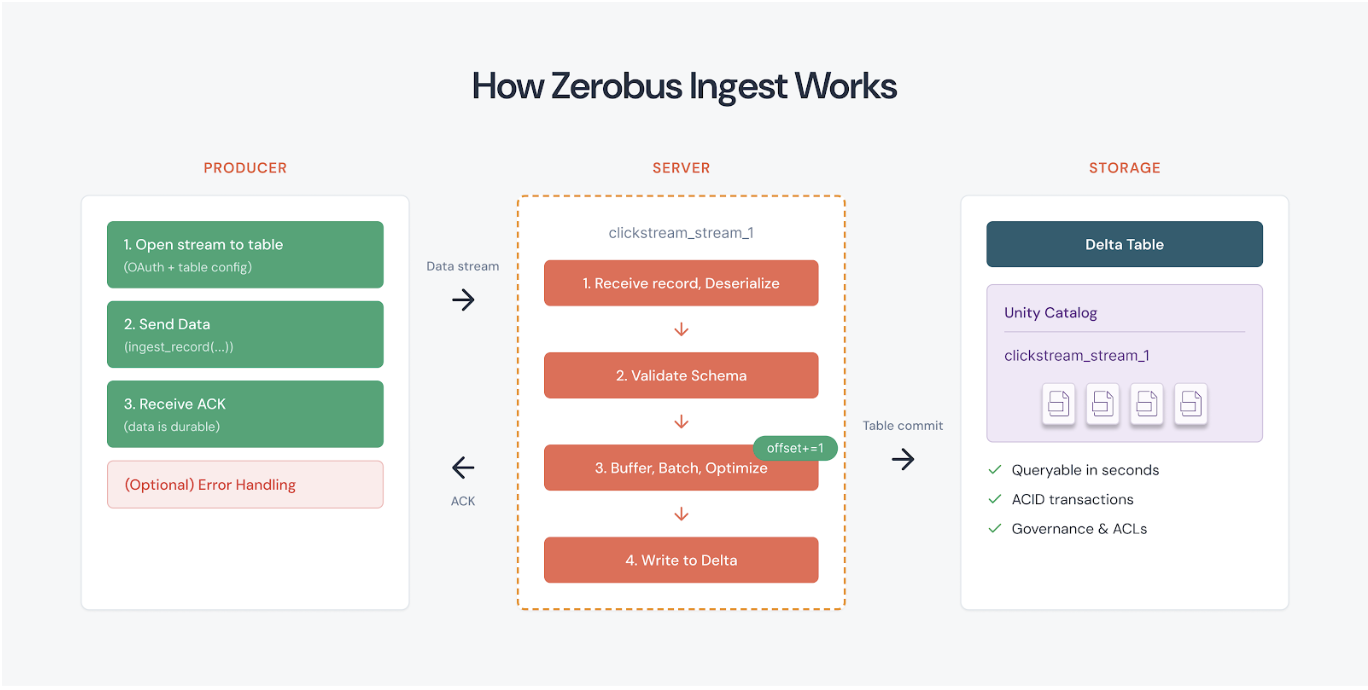
Zerobus Ingest(ZeroBus)는 Databricks의 Lakeflow Connect에 포함된 기능으로, 한 문장으로 요약하면 “Kafka 같은 메시지 버스 없이, 데이터 생산자가 이벤트 데이터를 Unity Catalog의 Delta 테이블로 직접(push)
39.데이터브릭스에서 힌트란?
Databricks SQL의 “힌트(Hint)”는 옵티마이저가 실행 계획(Execution Plan)을 만들 때 참고하도록 주는 ‘권고(guide)’입니다. 즉, 힌트를 줬다고 해서 항상 그대로 실행되는 것은 아니며, 조인 타입/전략 지원 여부 등에 따라 무시될 수 있
40.Databricks에서 Accumulator 제대로 쓰기 (feat. 함정과 베스트 프랙티스)

Databricks 노트북에서 데이터 품질 체크(에러 레코드 수), 간단한 카운팅/합산, 디버깅용 메트릭을 분산 실행(Executors) 중에 모으고 싶을 때가 있습니다. 이때 가장 먼저 떠오르는 게 Spark의 Accumulator(누적기) 인데요.하지만 “돌아가긴
41.Databricks Lakeflow Connector란? (개념 + 기본 사용법)
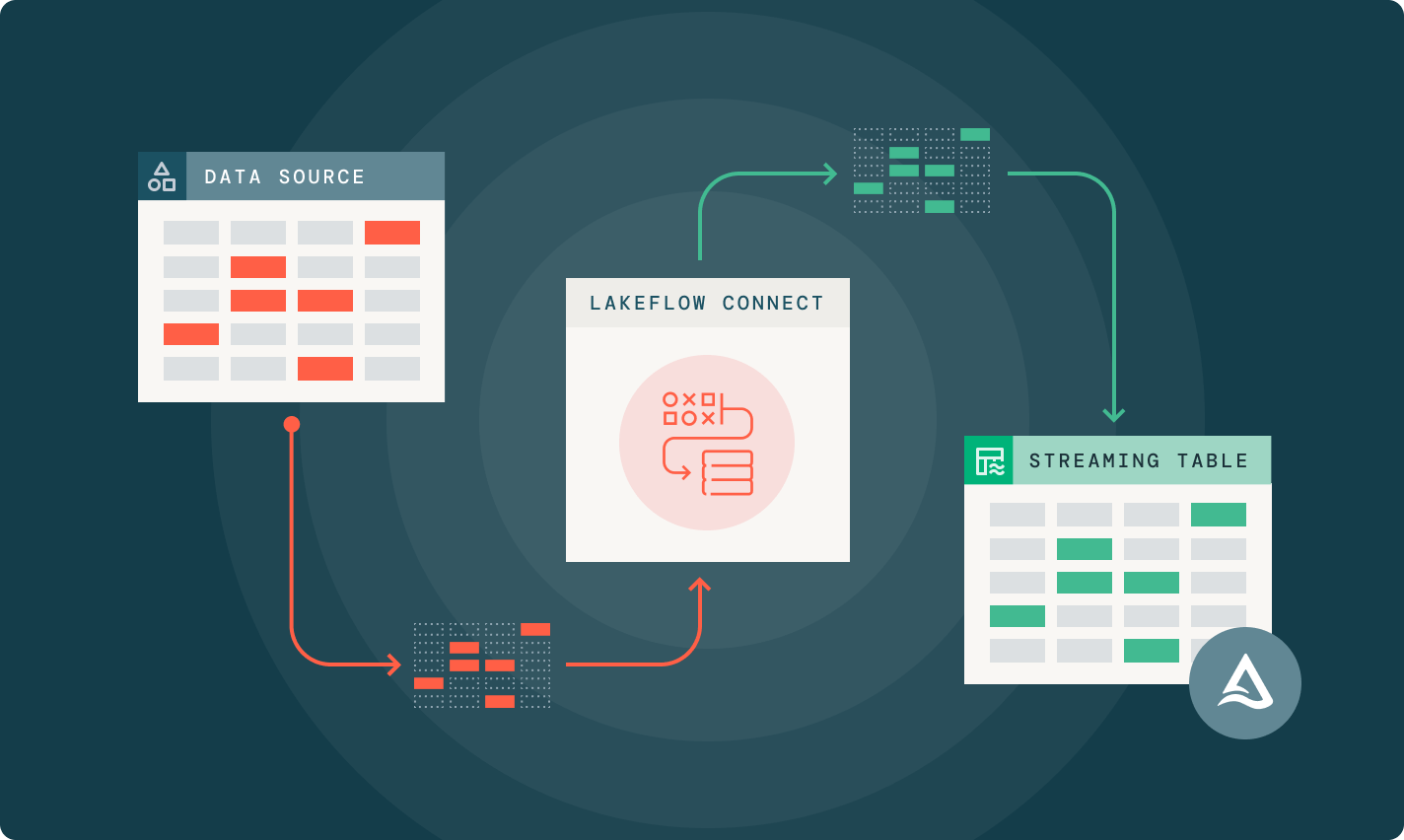
Databricks에서 “Lakeflow Connector”라고 부르는 경우, 보통 Lakeflow Connect의 커넥터(Connector)—특히 Managed connectors(완전 관리형 커넥터)—를 의미합니다.목표는 간단합니다: SaaS / DB / 파일 /
42.Databricks 압축 알고리즘과 ZSTD(Zstandard) 전환 방법 (Delta/Parquet 기준)

Databricks에서 테이블(특히 Delta Lake)은 내부적으로 Parquet 데이터 파일을 생성하고, 이 Parquet 파일은 압축 코덱(codec) 을 사용해 저장 비용과 I/O를 최적화합니다. Spark는 Parquet 쓰기 시 사용할 압축 코덱을 설정으로
43.Databricks Auto Loader로 데이터 적재하기 (cloudFiles 기반 실전 가이드)
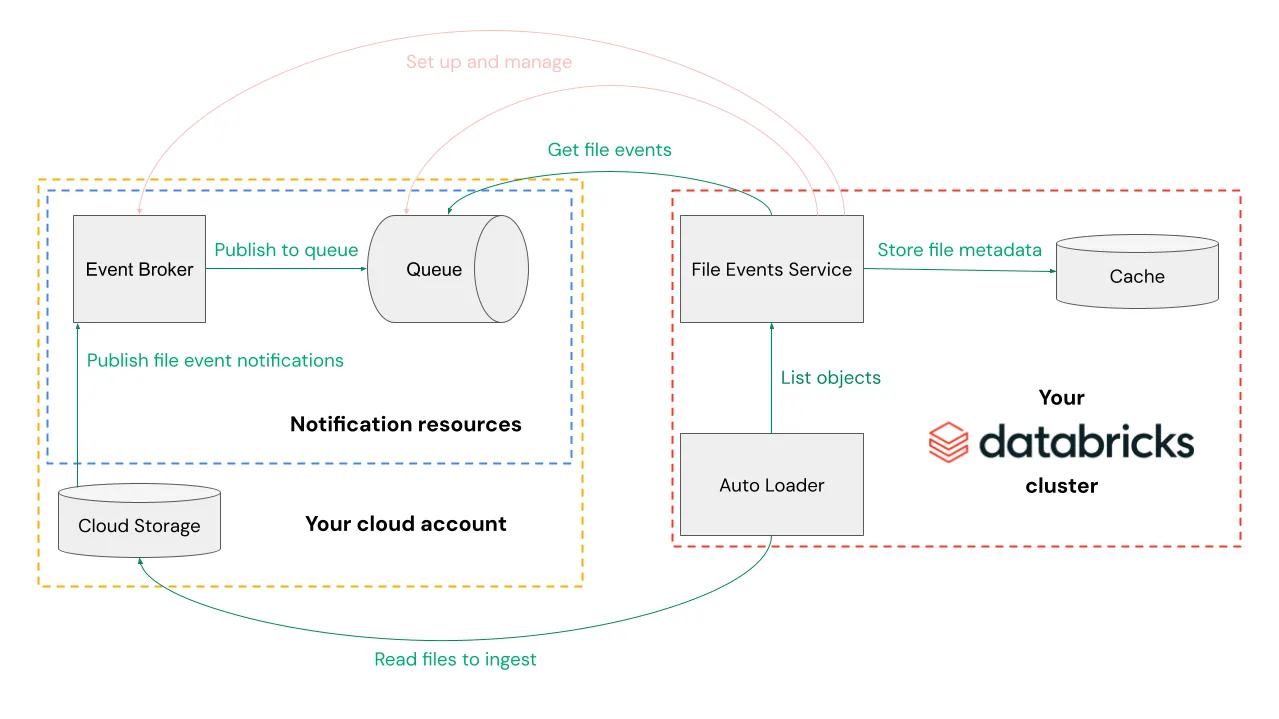
클라우드 스토리지(S3/ADLS/GCS 등)에 파일이 계속 쌓이는 환경이라면, “신규 파일만 증분으로 읽어서 Delta로 적재”하는 패턴이 거의 표준입니다.Databricks Auto Loader는 이런 상황을 위해 만들어진 기능으로, 클라우드 스토리지에 새 파일이 도
44.Databricks Lakebase란? 장단점과 Lakehouse 연동 방법 총정리

Databricks가 말하는 Lakebase는 한마디로, Lakehouse와 긴밀하게 통합된 운영용 Postgres 데이터베이스입니다. 기존 Databricks가 강했던 분석·AI·데이터 엔지니어링 영역에 더해, 이제는 애플리케이션이 직접 읽고 쓰는 OLTP(온라인 트
45.데이터브릭스 Lakehouse Federation이란? JDBC 연결과의 차이점
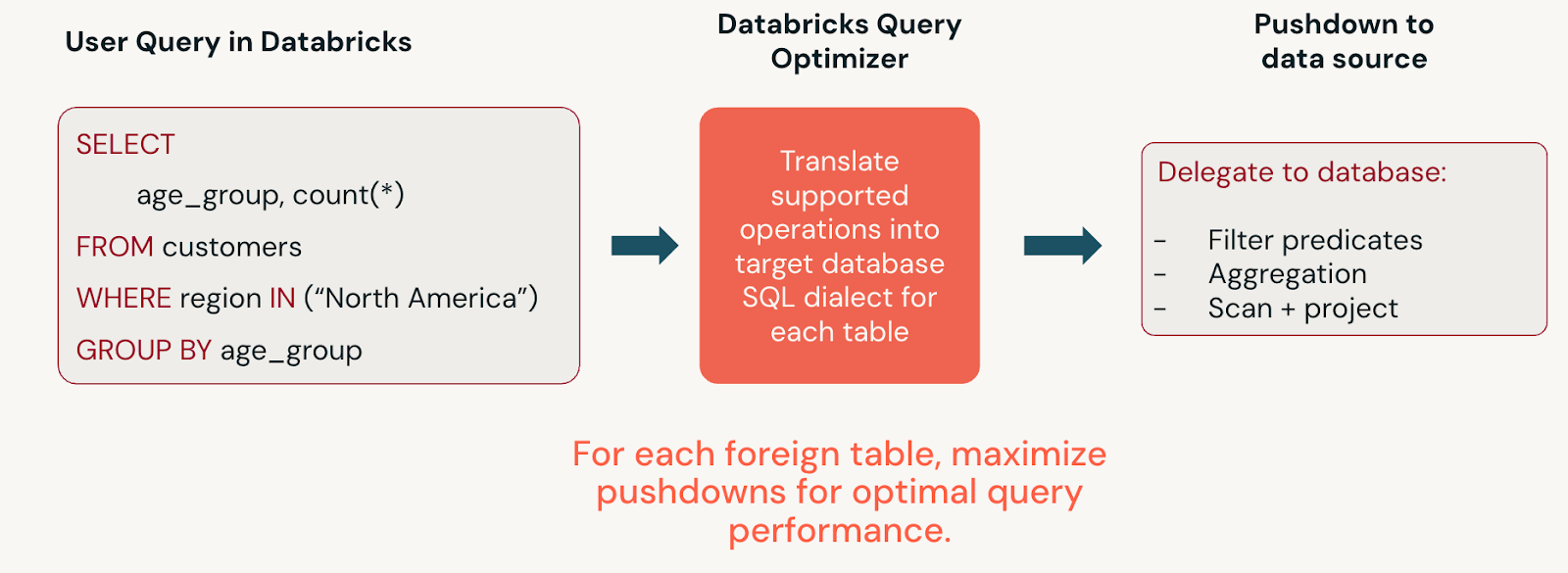
데이터 플랫폼을 운영하다 보면 “외부 DB에 있는 데이터를 꼭 다 적재해야만 분석할 수 있을까?”라는 질문을 자주 하게 됩니다. 이때 Databricks의 Lakehouse Federation은 데이터를 대규모로 복제하지 않고도 외부 데이터 소스를 조회할 수 있게 해주
46.[Databricks]의 [Zerobus Ingest]란? 개념, 장점, 사용법 정리
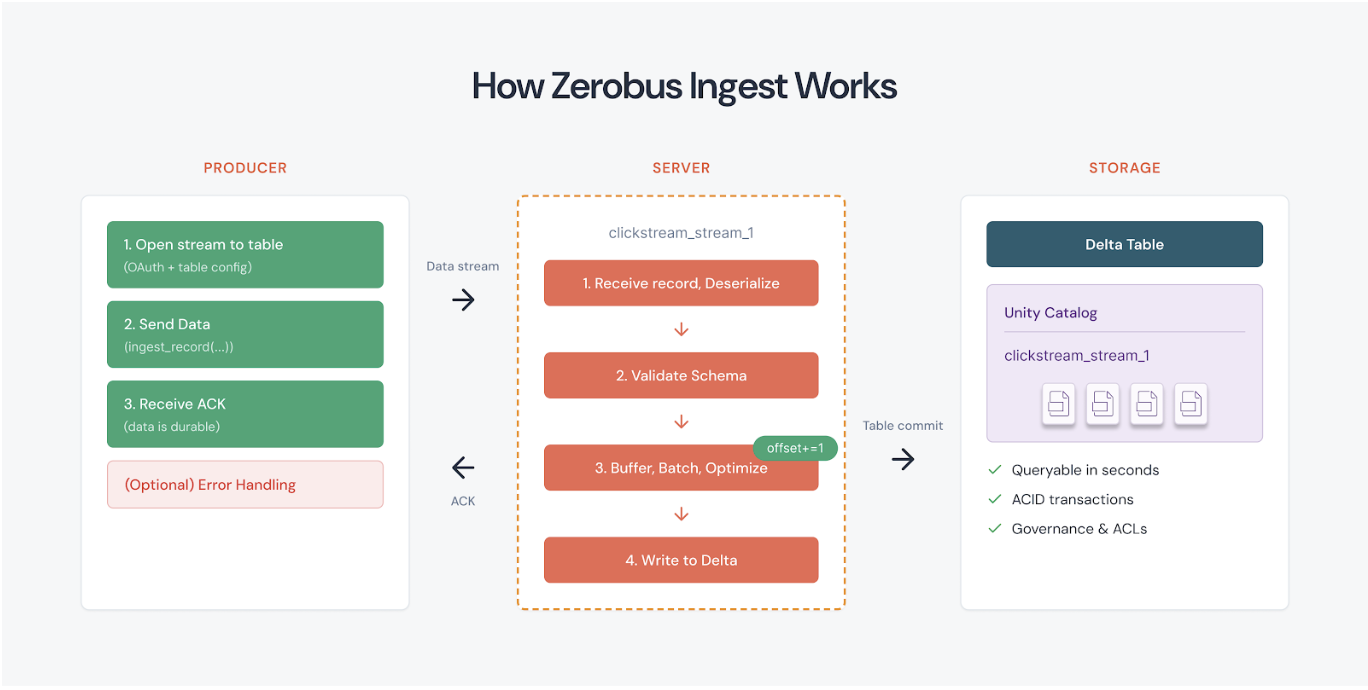
실시간 이벤트 데이터를 레이크하우스로 넣을 때 많은 팀이 보통 Kafka 같은 메시지 버스를 먼저 떠올립니다. 그런데 Databricks는 이 중간 계층 자체를 줄이는 방향으로 Zerobus Ingest를 내놓았습니다. Zerobus Ingest는 프로듀서가 데이터를
47.Databricks Zerobus Ingest를 Private Link로 내부 통신하는 방법
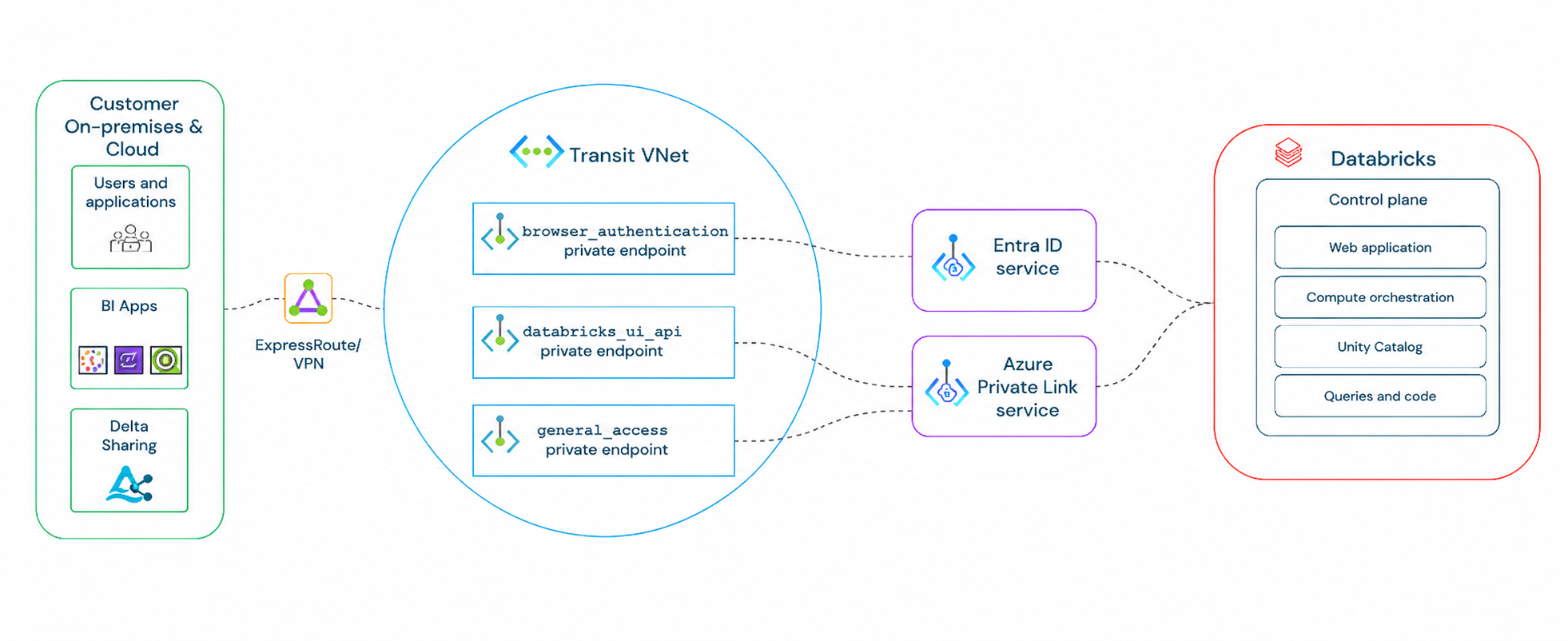
메시지 브로커 없이 이벤트를 바로 Delta 테이블로 밀어 넣고 싶다면 Zerobus Ingest가 꽤 강력한 선택지다. 핵심은 프로듀서 애플리케이션이 Zerobus 엔드포인트에 직접 연결해 데이터를 쓰는 구조라는 점이고, 이 연결을 인터넷이 아니라 사설 네트워크 경로