데이터 엔지니어링 분야에서 가장 중요한 도구 중 하나로 자리 잡은 Apache Airflow에 대해 알아보겠습니다. 복잡한 데이터 워크플로우를 쉽게 관리하고 싶으신가요? 데이터 파이프라인 작업을 자동화하고 모니터링하는 효과적인 방법을 찾고 계신가요? 그렇다면 Airflow가 해답이 될 수 있습니다.
Airflow란 무엇인가?
Apache Airflow는 프로그래밍 방식으로 워크플로우를 작성, 예약 및 모니터링하기 위한 오픈 소스 플랫폼입니다. 원래 Airbnb의 엔지니어링 팀에서 개발되었으며 2016년 Apache Software Foundation의 일부가 되었습니다.
Airflow는 파이썬 코드로 데이터 파이프라인을 정의할 수 있게 해주며, 이를 통해 복잡한 의존성이 있는 작업들을 쉽게 관리할 수 있습니다. 데이터 엔지니어링, ETL(Extract, Transform, Load) 작업, 데이터 분석, 머신러닝 파이프라인 등 다양한 데이터 워크플로우를 관리하는 데 이상적인 도구입니다.
Airflow의 핵심 개념
1. DAG (Directed Acyclic Graph)
Airflow의 중심에는 DAG(Directed Acyclic Graph)라는 개념이 있습니다. DAG는 방향이 있고 순환하지 않는 그래프로, 작업(Task)들과 그들 간의 의존성을 나타냅니다.
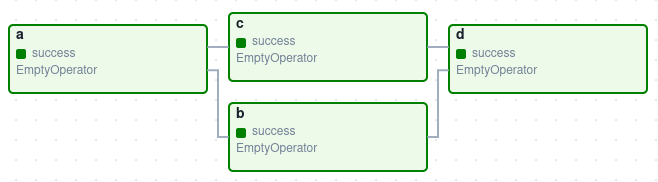
DAG의 주요 특징:
- 방향성(Directed): 각 작업은 특정 방향으로 실행됩니다 (A → B → C).
- 비순환성(Acyclic): 순환 경로가 없어 무한 루프에 빠지지 않습니다.
- 그래프(Graph): 노드(작업)와 에지(의존성)로 구성된 구조입니다.
2. 작업(Task)과 오퍼레이터(Operator)
Airflow에서 작업(Task)은 실행 가능한 최소 단위입니다. 작업은 주로 오퍼레이터(Operator)를 통해 정의됩니다.
주요 오퍼레이터 유형:
- BashOperator: Bash 명령어 실행
- PythonOperator: Python 함수 실행
- SQLOperator: SQL 쿼리 실행
- EmailOperator: 이메일 전송
- DockerOperator: Docker 컨테이너 실행
- Custom Operators: 필요에 따라 직접 정의할 수 있는 사용자 정의 오퍼레이터
3. 센서(Sensor)
센서는 특별한 유형의 오퍼레이터로, 특정 조건이 충족될 때까지 기다리는 역할을 합니다.
예시:
- FileSensor: 파일이 생성될 때까지 대기
- S3KeySensor: S3 버킷에 특정 키가 생성될 때까지 대기
- HttpSensor: HTTP 요청이 성공할 때까지 대기
- SqlSensor: SQL 쿼리가 특정 결과를 반환할 때까지 대기
4. 실행자(Executor)
실행자는 작업을 실행하는 방식을 결정합니다. Airflow는 다양한 실행자를 지원합니다:
- SequentialExecutor: 기본 실행자, 한 번에 하나의 작업만 실행 (주로 테스트용)
- LocalExecutor: 로컬 병렬 처리를 통해 다중 작업 실행
- CeleryExecutor: 여러 워커 노드에 작업을 분산하여 실행
- KubernetesExecutor: Kubernetes 클러스터에서 작업 실행
- DaskExecutor: Dask 클러스터를 사용하여 작업 실행
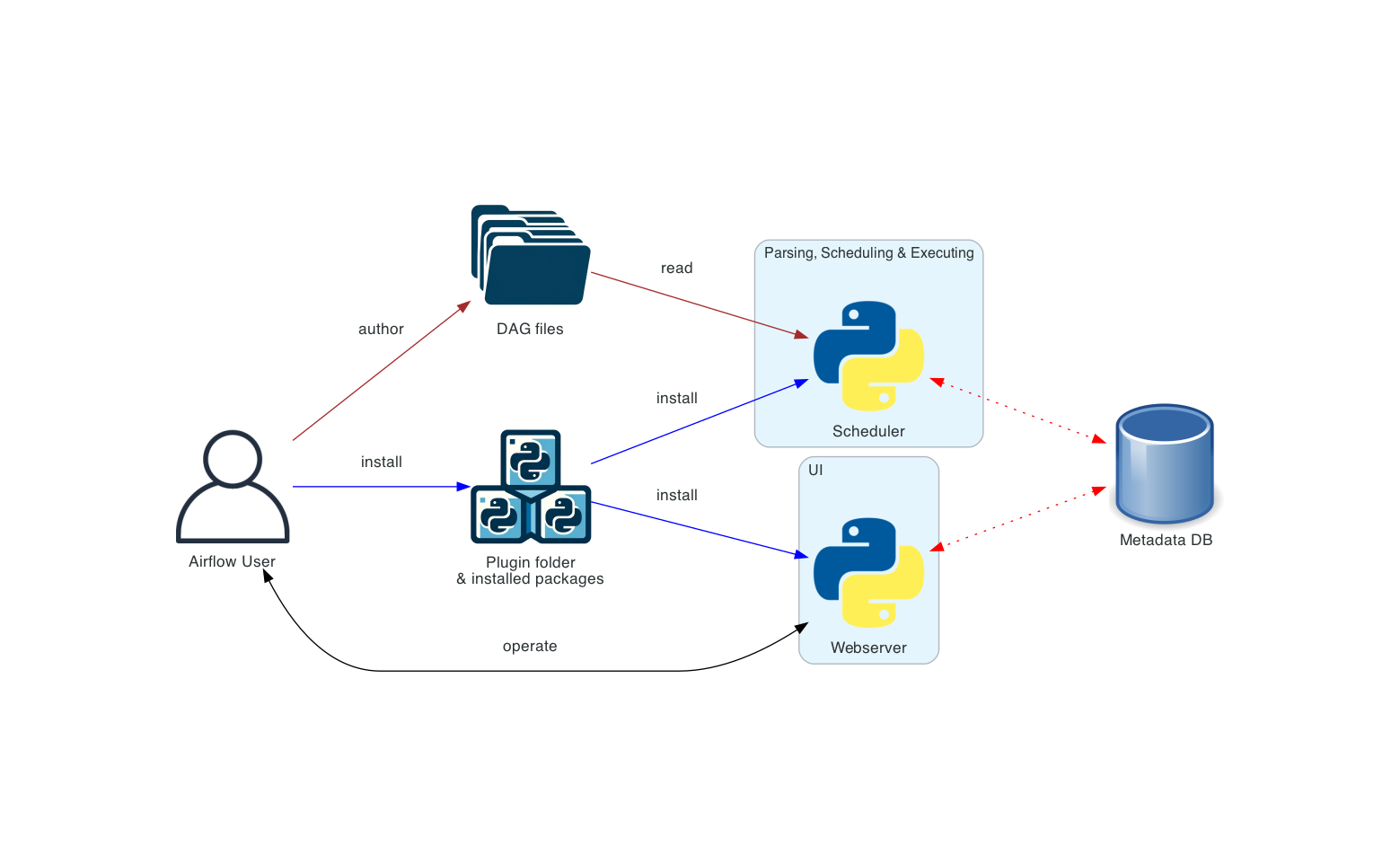
Airflow 아키텍처
Airflow는 다음과 같은 주요 컴포넌트로 구성됩니다:
1. 웹 서버(Web Server)
웹 인터페이스를 제공하여 DAG와 태스크의 상태를 모니터링하고 관리할 수 있게 합니다. 사용자는 이 인터페이스를 통해:
- DAG 및 태스크 실행 상태 확인
- 과거 실행 로그 조회
- 수동으로 DAG 실행
- 태스크 성공/실패 여부 확인
- 메타데이터 정보 조회 및 수정
2. 스케줄러(Scheduler)
Airflow의 핵심 컴포넌트로, 다음 역할을 수행합니다:
- DAG를 주기적으로 스캔하고 활성화된 DAG 감지
- 스케줄에 따라 DAG 실행 트리거
- 실행할 태스크를 결정하고 실행자에게 전달
- 작업 간 의존성 관리
3. 메타데이터 데이터베이스(Metadata Database)
Airflow의 상태 정보를 저장하는 관계형 데이터베이스입니다:
- DAG 정의 및 구성
- 태스크 인스턴스의 상태 및 결과
- 변수, 연결 정보 등 구성 데이터
- 사용자 인증 정보
지원되는 데이터베이스로는 SQLite(개발용), PostgreSQL, MySQL 등이 있습니다.
4. 워커(Worker)
실제로 태스크를 실행하는 프로세스입니다. 스케줄러에 의해 할당된 작업을 수행하고 결과를 보고합니다.
5. DAG 파일 저장소
Python으로 작성된 DAG 정의 파일을 저장하는 폴더입니다. 스케줄러는 이 폴더를 주기적으로 스캔하여 새로운 DAG나 변경된 DAG를 감지합니다.
Airflow의 장점
Airflow가 데이터 파이프라인 관리 도구로 널리 사용되는 이유를 살펴보겠습니다.
1. 파이썬 기반 정의
Airflow는 파이썬 코드로 워크플로우를 정의할 수 있어, 동적인 파이프라인 생성이 가능합니다. 이는 XML이나 YAML과 같은 정적 구성 파일보다 훨씬 유연합니다.
Copyfrom datetime import datetime
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
def print_hello():
return 'Hello World!'
dag = DAG(
'hello_world',
description='간단한 hello world DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2023, 1, 1),
catchup=False
)
hello_operator = PythonOperator(
task_id='hello_task',
python_callable=print_hello,
dag=dag
)
2. 강력한 웹 UI
Airflow는 직관적인 웹 인터페이스를 제공하여 DAG와 태스크를 쉽게 모니터링하고 관리할 수 있습니다:
- 그래프 뷰: 작업 간 의존성을 시각적으로 표현
- 트리 뷰: 시간에 따른 실행 상태 표시
- 간트 차트: 태스크 실행 기간 표시
- 코드 뷰: DAG 코드 직접 확인
- 로그 뷰: 태스크별 로그 확인
3. 확장성
Airflow는 다양한 실행자를 지원하여 소규모 로컬 환경부터 대규모 분산 환경까지 확장할 수 있습니다. CeleryExecutor나 KubernetesExecutor를 사용하면 수천 개의 태스크를 병렬로 처리할 수 있습니다.
4. 풍부한 통합 지원
Airflow는 다양한 외부 시스템과의 통합을 위한 광범위한 프로바이더와 오퍼레이터를 제공합니다:
- 클라우드 서비스: AWS, GCP, Azure 등
- 데이터베이스: MySQL, PostgreSQL, MongoDB, Snowflake 등
- 빅데이터 도구: Hadoop, Spark, Hive 등
- 메시징 시스템: Kafka, RabbitMQ 등
- API 및 웹 서비스: REST, SOAP, GraphQL 등
5. 커뮤니티 지원
활발한 오픈 소스 커뮤니티를 가지고 있어 지속적인 개선과 버그 수정이 이루어지며, 다양한 사용 사례와 해결책을 공유할 수 있습니다.
Airflow의 실제 활용 사례
1. ETL(Extract, Transform, Load) 파이프라인
가장 일반적인 사용 사례로, 데이터를 추출하고 변환한 후 데이터 웨어하우스나 데이터 레이크에 적재하는 과정을 자동화합니다.
Copy# ETL 작업 예시
extract_task >> transform_task >> load_task
2. 머신러닝 파이프라인
데이터 전처리, 모델 훈련, 평가, 배포까지 머신러닝 워크플로우 전체를 자동화합니다.
Copy# 머신러닝 파이프라인 예시
data_prep >> feature_engineering >> model_training >> model_evaluation >> model_deployment
3. 데이터 품질 검증
데이터 유효성 검사, 중복 검사, 일관성 검사 등을 자동화하여 데이터 품질을 유지합니다.
Copy# 데이터 품질 검증 예시
data_validation_task >> [schema_validation, duplicate_check, null_check] >> report_generation
4. 보고서 생성 및 배포
정기적인 비즈니스 보고서 생성 및 이메일이나 대시보드 시스템으로 배포하는 과정을 자동화합니다.
Copy# 보고서 생성 예시
data_extraction >> report_generation >> [email_notification, dashboard_update]
5. 클라우드 리소스 관리
클라우드 인프라의 리소스 프로비저닝, 스케일링, 모니터링 등을 자동화합니다.
Copy# AWS 리소스 관리 예시
check_resources >> [scale_up_cluster, provision_new_instances] >> verify_deployment
Airflow 사용 시 고려사항 및 모범 사례
1. DAG 설계 모범 사례
- 원자성 태스크: 각 태스크는 단일 책임을 가지도록 설계
- 멱등성: 태스크를 여러 번 실행해도 동일한 결과가 나오도록 설계
- 태스크 의존성: 명확한 의존성 구조로 설계하여 병렬화 극대화
- 오류 처리: 실패 시나리오를 고려한 설계
2. 성능 최적화
- 적절한 실행자 선택: 워크로드에 맞는 실행자 선택
- 리소스 관리: 태스크에 적절한 메모리, CPU 할당
- 병렬화: 독립적인 태스크는 병렬로 실행하도록 설계
- 태스크 그룹화: 작은 태스크를 그룹화하여 오버헤드 감소
3. 보안 고려사항
- 비밀 관리: 암호, API 키 등은 Airflow 변수나 연결 기능을 사용해 안전하게 관리
- 역할 기반 접근 제어(RBAC): 사용자별 적절한 권한 부여
- 네트워크 보안: 적절한 네트워크 격리 및 방화벽 설정
Airflow 설치 및 시작하기
Airflow를 시작하는 방법은 여러 가지가 있습니다. 가장 간단한 방법부터 살펴보겠습니다.
1. 로컬 설치
Copy# pip를 사용한 설치
pip install apache-airflow
# 초기화 및 실행
airflow db init
airflow users create \
--username admin \
--password admin \
--firstname Your \
--lastname Name \
--role Admin \
--email your.email@example.com
# 웹 서버 및 스케줄러 시작
airflow webserver --port 8080
airflow scheduler
2. Docker를 사용한 설치
Copy# docker-compose.yaml 파일 다운로드
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.8.1/docker-compose.yaml'
# 기본 설정
mkdir -p ./dags ./logs ./plugins
echo -e "AIRFLOW_UID=$(id -u)" > .env
# 시작
docker-compose up -d
3. 클라우드 매니지드 서비스
각 클라우드 제공업체는 Airflow의 매니지드 서비스를 제공합니다:
- Google Cloud: Cloud Composer
- AWS: Amazon Managed Workflows for Apache Airflow (MWAA)
- Azure: Azure Data Factory (Airflow 통합)
결론
Apache Airflow는 데이터 엔지니어링 생태계에서 필수적인 도구로 자리 잡았습니다. 복잡한 데이터 워크플로우를 프로그래밍 방식으로 정의하고, 스케줄링하며, 모니터링할 수 있는 강력한 기능을 제공합니다.
Airflow의 핵심 강점은 파이썬 코드로 파이프라인을 정의할 수 있는 유연성, 직관적인 웹 UI, 확장성, 그리고 풍부한 커뮤니티 지원에 있습니다. 이러한 특징들 덕분에 소규모 개발 환경부터 대규모 엔터프라이즈 환경까지 다양한 규모의 데이터 파이프라인을 관리하는 데 이상적인 선택이 되었습니다.
데이터 엔지니어, 데이터 사이언티스트, 그리고 데이터 기반 의사결정을 필요로 하는 모든 조직에게 Airflow는 워크플로우 자동화와 데이터 파이프라인 관리의 복잡성을 크게 줄여주는 도구입니다.
