클라우드 스토리지(S3/ADLS/GCS 등)에 파일이 계속 쌓이는 환경이라면, “신규 파일만 증분으로 읽어서 Delta로 적재”하는 패턴이 거의 표준입니다.
Databricks Auto Loader는 이런 상황을 위해 만들어진 기능으로, 클라우드 스토리지에 새 파일이 도착할 때마다 증분(incremental) + 효율적으로 처리합니다. Source
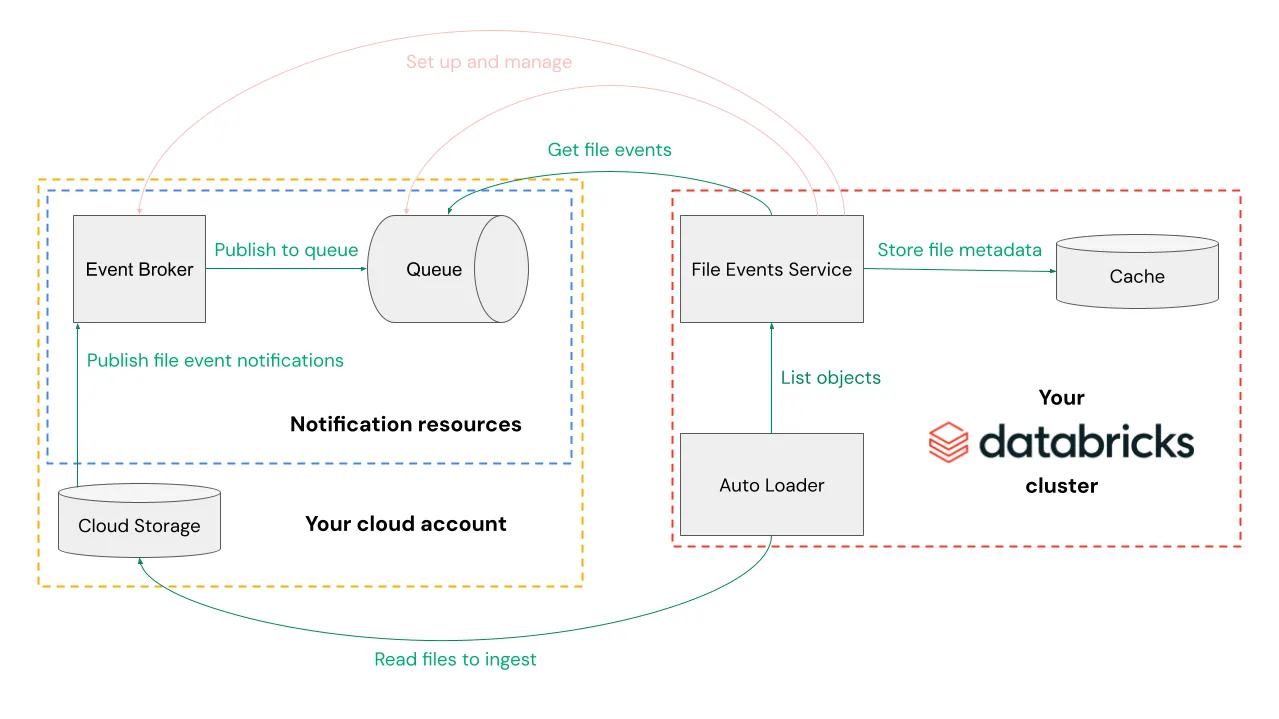
파일 이벤트 기반(file events)으로 새 파일을 감지하는 개념도 Source
목차
- 1. Auto Loader란? (cloudFiles 소스)
- 2. 언제 Auto Loader를 쓰나?
- 3. 지원 소스/포맷
- 4. 기본 적재 코드 (Structured Streaming)
- 5. 스키마 추론/진화 + _rescued_data 이해
- 6. 파일 감지 모드 2가지: Directory Listing vs File Notification(권장)
- 7. 운영(Production) 베스트 프랙티스 체크리스트
- 8. 자주 쓰는 패턴 모음
- 참고자료
1. Auto Loader란? (cloudFiles 소스)
Auto Loader는 클라우드 스토리지에 새 파일이 도착하는 대로 파일을 증분 처리하는 기능입니다. Source
구현 관점에서 핵심은 Auto Loader가 Structured Streaming 소스로 cloudFiles 를 제공한다는 점입니다. “입력 디렉터리 경로를 주면 새 파일을 자동으로 처리”합니다. Source
그리고 Auto Loader는 체크포인트 위치에 RocksDB 기반 키-값 스토어로 발견된 파일 메타데이터를 저장해서, 장애가 나도 exactly-once(정확히 한 번) 처리를 보장하도록 설계되어 있습니다. Source
2. 언제 Auto Loader를 쓰나?
Databricks는 “클라우드 오브젝트 스토리지 또는 Unity Catalog Volume의 파일 기반 적재”에서 대부분의 경우 Auto Loader를 추천합니다.
특히 파이프라인(Lakeflow Spark Declarative Pipelines)에서도 Auto Loader를 권장하며, “증분 + 멱등(idempotent) 적재”에 맞춰 설계됐다고 명시합니다. Source
3. 지원 소스/포맷
지원 소스(경로 스킴)
Auto Loader는 아래 소스에서 파일을 로딩할 수 있습니다. Source
- Amazon S3 (
s3://) - ADLS (
abfss://) - GCS (
gs://) - Azure Blob (
wasbs://) - DBFS (
dbfs:/)
지원 파일 포맷
다음 포맷을 ingest 할 수 있습니다. Source
- JSON, CSV, XML
- PARQUET, AVRO, ORC
- TEXT, BINARYFILE
4. 기본 적재 코드 (Structured Streaming)
Auto Loader의 기본 형태는 아래처럼 “읽기(readStream)에서 cloudFiles”를 사용합니다.
4.1 가장 기본(스키마 추론 + 스키마 위치 + 체크포인트)
Databricks의 “공통 패턴” 문서에 나오는 대표 스니펫 흐름은 다음과 같습니다. Source
(
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", "<path-to-schema-location>")
.load("<path-to-source-data>")
.writeStream
.option("mergeSchema", "true")
.option("checkpointLocation", "<path-to-checkpoint>")
.start("<path_to_target>")
)포인트는 2개입니다.
cloudFiles.schemaLocation: 스키마 추론/진화 메타데이터 저장소 (Auto Loader가_schemas디렉터리에 관리) SourcecheckpointLocation: exactly-once를 위한 상태 저장 위치(RocksDB 포함) Source
5. 스키마 추론/진화 + _rescued_data 이해
5.1 스키마 추론(inference)은 어떻게 동작?
Auto Loader는 최초 스키마 추론 시 처음 발견한 50GB 또는 1000개 파일을 샘플링하고(둘 중 먼저 도달한 기준), 결과를 cloudFiles.schemaLocation 아래 _schemas에 저장합니다. Source
5.2 스키마 진화(evolution)에서 스트림이 “실패”할 수 있음
새 컬럼이 들어오면 UnknownFieldException으로 스트림이 실패할 수 있고, 실패하기 전에 최신 마이크로배치를 기반으로 스키마 위치를 업데이트(새 컬럼을 스키마 끝에 병합)하는 동작이 문서에 설명돼 있습니다. Source
그래서 운영에서는 “스키마 변경으로 실패하면 자동 재시작”을 잡/워크플로우 레벨에서 구성하는 것을 권장합니다. Source
5.3 _rescued_data란?
Auto Loader는 스키마와 맞지 않는 데이터를 버리지 않도록 _rescued_data 컬럼(기본명)을 사용합니다. 이 컬럼에는 다음 이유로 파싱되지 않은 데이터가 JSON blob 형태로 들어갑니다. Source
- 스키마에 없는 컬럼(새 컬럼)
- 타입 불일치(type mismatch)
- 컬럼명 대소문자 불일치(case mismatch)
6. 파일 감지 모드 2가지: Directory Listing vs File Notification(권장)
Auto Loader는 새 파일을 찾는 방식이 두 가지입니다. Source
6.1 Directory listing mode
- 입력 디렉터리를 “리스트업(listing)”해서 새 파일을 찾음
- 추가 권한 설정 없이 빠르게 시작 가능 Source
6.2 File notification mode (권장)
- 클라우드의 “파일 이벤트 + 큐”를 활용
- directory listing보다 성능/확장성이 좋고 비용도 줄일 수 있어 권장된다고 문서에 명시 Source
- 특히 file events 기반 file notification으로의 마이그레이션을 권장합니다. Source
File events → 큐/알림 기반으로 새 파일을 감지하는 구성 개념 Source
7. 운영(Production) 베스트 프랙티스 체크리스트
문서 기반으로 “실제로 장애/비용/누락을 줄이는” 포인트만 추려서 체크리스트로 정리합니다.
7.1 체크포인트 위치에 수명주기(Lifecycle) 정책 금지
Databricks는 체크포인트 위치에 lifecycle policy가 적용되어 파일이 정리되면 스트림 상태가 손상(corrupted) 될 수 있다고 경고합니다. Source
7.2 file events(파일 이벤트) 기반을 우선
Auto Loader는 file events를 사용하면 디렉터리 listing 비용을 줄일 수 있고, 운영 효율이 좋아진다고 안내합니다. Source
7.3 “연속 실행” 대신 배치성 실행(AvailableNow) 고려
낮은 지연(latency)이 꼭 필요하지 않다면, Databricks는 Lakeflow Jobs로 Trigger.AvailableNow를 써서 배치 잡처럼 실행하는 방식을 권장합니다. Source
7.4 directory listing을 어쩔 수 없이 쓴다면 cleanSource 고려
directory listing 기반에서 소스 폴더에 파일이 계속 쌓이면 탐색 비용이 증가하므로, 처리 완료 파일을 옮기거나 삭제하는 cloudFiles.cleanSource 사용을 추천합니다. Source
8. 자주 쓰는 패턴 모음
8.1 “스키마는 알고 있는데, 예상치 못한 컬럼은 살려두고 싶다” → rescue 모드
패턴 문서에서 cloudFiles.schemaEvolutionMode = rescue 예시를 제공합니다. Source
(
spark.readStream.format("cloudFiles")
.schema(expected_schema)
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaEvolutionMode", "rescue")
.load("<path-to-source-data>")
.writeStream
.option("checkpointLocation", "<path-to-checkpoint>")
.start("<path_to_target>")
)이 경우 스키마에 없는 데이터/타입 불일치 등은 _rescued_data로 들어가 “누락 없는 적재”에 유리합니다. Source
8.2 “엄청 많은 파일(백필/마이그레이션)”에도 확장
Auto Loader는 수십억 파일 처리(백필/마이그레이션)와 시간당 수백만 파일 수준의 근실시간 적재까지 확장 가능하다고 설명합니다. Source
참고자료
- What is Auto Loader? (개념/지원 소스/포맷/체크포인트 & RocksDB exactly-once)
https://docs.databricks.com/aws/en/ingestion/cloud-object-storage/auto-loader/ - Schema inference & evolution /
_rescued_data
https://docs.databricks.com/aws/en/ingestion/cloud-object-storage/auto-loader/schema - File detection modes (directory listing vs file notification 권장, file events)
https://docs.databricks.com/aws/en/ingestion/cloud-object-storage/auto-loader/file-detection-modes - Production recommendations (checkpoint lifecycle 주의, AvailableNow 권장 등)
https://docs.databricks.com/aws/en/ingestion/cloud-object-storage/auto-loader/production - Common patterns (추천 스니펫 모음)
https://docs.databricks.com/aws/en/ingestion/cloud-object-storage/auto-loader/patterns - Load data in pipelines (파이프라인에서 Auto Loader 권장)
https://docs.databricks.com/aws/en/ldp/load
