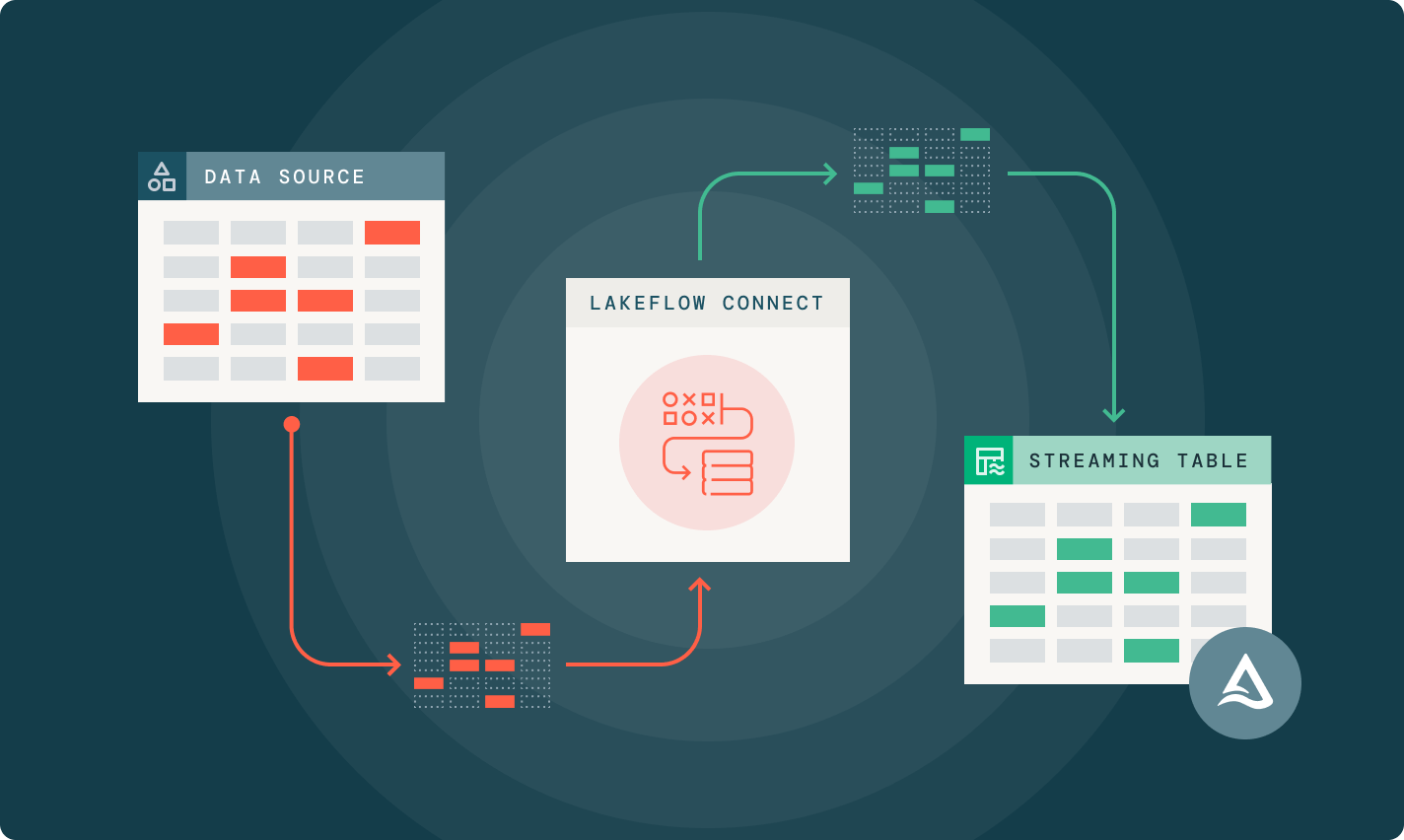
Databricks에서 “Lakeflow Connector”라고 부르는 경우, 보통 Lakeflow Connect의 커넥터(Connector)—특히 Managed connectors(완전 관리형 커넥터)—를 의미합니다.
목표는 간단합니다: SaaS / DB / 파일 / 메시지 버스 등의 데이터를 Databricks Lakehouse(Delta)로 쉽고 효율적으로 적재(ingestion) 하는 것. Source
Lakeflow Connect는 Databricks 데이터 적재를 “관리형”으로 단순화하는 방향을 강조합니다. Source
목차
- 1. Lakeflow Connect 한 줄 정의
- 2. 커넥터 종류: Managed vs Standard (그리고 언제 무엇을?)
- 3. Managed Connector의 핵심 개념(구성요소)
- 4. “증분 적재(Incremental ingestion)”가 기본인 이유
- 5. 기본 사용법: UI로 빠르게 시작하기
- 6. 권한/사전 준비 체크리스트(초보자 함정 방지)
- 7. 운영 팁(스키마 진화, 비용, 삭제 시 동작)
- 8. 자주 묻는 비교: Lakehouse Federation / Delta Sharing / Auto Loader
- 참고자료
1. Lakeflow Connect 한 줄 정의
Lakeflow Connect는 로컬 파일, 엔터프라이즈 애플리케이션(SaaS), 데이터베이스, 클라우드 스토리지, 메시지 버스 등 다양한 소스에서 Databricks로 데이터를 간단하고 효율적으로 ingest 할 수 있도록 제공되는 커넥터 제품군(및 프레임워크)입니다. Source
또한 Databricks는 “어느 정도까지 관리(Managed)할 것인지” 선택지를 제공합니다:
- 완전 관리형(fully-managed) 커넥터: UI/API로 빠르게 구축, 유지보수 부담 최소화
- 더 커스터마이즈가 필요한 경우: Lakeflow Spark Declarative Pipelines 또는 Structured Streaming으로 내려가서 구현 Source
2. 커넥터 종류: Managed vs Standard (그리고 언제 무엇을?)
Databricks 문서 기준으로 큰 갈래는 두 가지입니다.
2.1 Managed connectors (완전 관리형)
- SaaS(예: Salesforce, ServiceNow 등) 또는 DB(예: SQL Server 등)에서 관리형 ingestion pipeline을 만들어줍니다.
- Unity Catalog 거버넌스 + Serverless compute + Lakeflow Spark Declarative Pipelines 기반으로 동작합니다. Source
문서에 예시로 나오는 “지원 커넥터”에는 Google Analytics, Salesforce, ServiceNow, SharePoint, SQL Server, Workday 등이 포함됩니다. Source
2.2 Standard connectors (표준 커넥터)
- 클라우드 오브젝트 스토리지 / 메시지 버스 등에서 더 높은 커스터마이징이 필요할 때 선택합니다. Source
실무 추천 흐름(문서 가이드): “가장 관리형 레이어부터 시작하고, 요구사항이 안 맞으면 아래 레이어로 내려가라”는 방향을 제시합니다. Source
3. Managed Connector의 핵심 개념(구성요소)
Managed connector는 “커넥터 하나”라기보다 Unity Catalog + 파이프라인 + 목적지 테이블을 묶어주는 관리형 ingestion 시스템에 가깝습니다.
Databricks 문서에서는 Managed connector가 Unity Catalog로 거버넌스되고, serverless compute 및 Lakeflow Spark Declarative Pipelines로 구동된다고 설명합니다. Source
3.1 SaaS 커넥터 구성요소(개념)
- Connection
- Ingestion pipeline
- Destination tables
(이 구성요소 분리는 Azure Databricks 문서에서 명시적으로 정리되어 있습니다.) Source
3.2 DB 커넥터 구성요소(개념)
DB 커넥터는 네트워크/변경 추적 때문에 보통 더 많은 부품이 필요합니다:
- Connection
- Ingestion gateway
- Staging storage(UC volume)
- Ingestion pipeline
- Destination tables Source
Managed connector는 UI에서 “테이블 선택 → 목적지 지정 → 스케줄” 등 파이프라인 생성을 안내합니다. Source
4. “증분 적재(Incremental ingestion)”가 기본인 이유
Lakeflow Connect(Managed connectors)의 큰 장점은 증분 적재가 기본 설계라는 점입니다.
문서에 따르면:
- 첫 실행: 선택된 데이터를 전체 적재(full ingest)
- 동시에 소스 변경을 추적(track changes)
- 이후 실행: 가능하면 변경분만 적재(only changed data) Source
그리고 “어떤 방식으로 변경을 추적하느냐”는 소스에 따라 달라집니다. 예를 들어 SQL Server는 change tracking / CDC를 사용할 수 있고, Salesforce 커넥터는 커서 컬럼을 선택하는 식으로 접근합니다. Source
5. 기본 사용법: UI로 빠르게 시작하기
아래는 Managed connector를 UI로 시작할 때의 “기본 흐름”입니다(초보자용).
Step 0) 어떤 커넥터를 쓸지 결정
FAQ 기준으로 예시로 언급되는 managed connector는 Salesforce, SQL Server, ServiceNow, Google Analytics 등입니다. Source
Step 1) (중요) Unity Catalog의 “Connection” 만들기
Databricks 문서(Managed ingestion 연결 안내)에 따르면, Catalog Explorer에서 다음 순서로 Connection을 만듭니다:
- Databricks workspace에서 Catalog > Create > Create a connection
- Connection name 지정
- Connection type에서 소스 선택
- Authentication 정보 입력
- Create connection Source
팁: 비관리자 사용자가 파이프라인을 만들게 할 거라면, 관리자가 먼저 Connection을 만들어 두는 구조를 권장하고, 이 경우 권한(Privileges) 요구사항이 따로 정리되어 있습니다. Source
Step 2) Ingestion pipeline 생성
FAQ에 따르면 Managed connector는 공통적으로 Databricks APIs와 Declarative Automation Bundles로 파이프라인 생성이 가능하며, 일부 커넥터는 UI에서도 생성 경로를 제공합니다(예: Add data, Jobs & Pipelines 등). Source
Step 3) 적재할 객체 선택(테이블/리포트 등) + 목적지 지정(UC Catalog/Schema)
SQL Server 커넥터 예시 블로그에서는 “복제할 테이블 선택 → 목적지(UC 내 catalog/schema) 설정 → 스케줄/알림” 형태의 단계를 소개합니다. Source
Step 4) 스케줄 설정 후 실행(첫 실행은 Full load일 가능성 높음)
Managed connector는 첫 실행에 전체 적재를 수행하고, 이후 변경분 위주로 적재하는 증분 방식이 기본입니다. Source
6. 권한/사전 준비 체크리스트(초보자 함정 방지)
“왜 UI에서 막히지?”의 대부분은 Unity Catalog 권한에서 시작합니다.
Managed ingestion 연결 문서에는 대표 시나리오별로 필요한 권한이 정리되어 있습니다. 예를 들어:
- Admin이 connection + pipeline을 같이 만들면
CREATE CONNECTION(metastore),USE CATALOG(target), 그리고 소스 유형(SaaS/DB)에 따라USE SCHEMA,CREATE TABLE,CREATE VOLUME등이 필요합니다. Source - Non-admin이 기존 connection을 사용하려면
USE CONNECTION이 필요합니다. Source
또한 DB 커넥터는 네트워크 요구사항(예: Private Link, VNet/VPC 피어링, 온프레미스 연결은 Direct Connect/ExpressRoute 등) 고려가 필요하다는 점이 Azure 문서에 설명되어 있습니다. Source
7. 운영 팁(스키마 진화, 비용, 삭제 시 동작)
7.1 스키마 진화(Schema evolution)
FAQ에 따르면 Managed connectors는 기본적으로 새 컬럼/삭제 컬럼을 자동으로 처리합니다(옵트아웃 가능).
예: 새 컬럼이 생기면 다음 파이프라인 실행 시 자동으로 ingest하고, 삭제 컬럼은 자동 drop 대신 inactive로 처리하는 식의 정책이 있습니다. Source
7.2 비용(과금 모델) 감 잡기
Managed connector는 “compute 기반 과금”이며, SaaS는 serverless 인프라 기반 DBU 과금이 발생할 수 있고, DB 커넥터는 gateway가 classic/serverless 모드에 따라 과금이 섞일 수 있다고 FAQ에서 설명합니다. Source
7.3 파이프라인 삭제하면 테이블은?
FAQ에 따르면 ingestion pipeline을 삭제하면 destination tables도 drop됩니다. 운영에서는 특히 주의가 필요합니다. Source
8. 자주 묻는 비교: Lakehouse Federation / Delta Sharing / Auto Loader
“Lakeflow Connect 말고 다른 선택지는?”에 대해 FAQ가 명확히 비교를 제공합니다.
- Lakehouse Federation: 데이터를 “복사해서 적재”하지 않고 외부를 직접 질의(데이터 이동 최소화) Source
- Delta Sharing: 플랫폼/클라우드 간 라이브 데이터 공유 Source
- Auto Loader: S3/ADLS/GCS 같은 클라우드 오브젝트 스토리지에 도착하는 파일을 증분으로 ingest (단, Managed connector처럼 완전 관리형 파이프라인은 아님) Source
참고자료
- Lakeflow Connect(ingestion 개요/레이어/지원 소스): https://docs.databricks.com/aws/en/ingestion/overview
- Managed connectors 개요 + 증분 적재 설명: https://docs.databricks.com/aws/en/ingestion/lakeflow-connect/
- Managed connectors FAQ(지원 커넥터, UI 생성 경로, 스키마 진화, 비용 등): https://docs.databricks.com/aws/en/ingestion/lakeflow-connect/faq
- Managed ingestion source 연결(“Create a connection” 흐름/권한 요구사항): https://docs.databricks.com/aws/en/connect/managed-ingestion
- SQL Server 커넥터 예시 워크플로우(게이트웨이/CDC/스케줄): https://www.databricks.com/blog/lakeflow-connect-efficient-and-easy-data-ingestion-using-sql-server-connector
- (Azure Databricks) Managed connectors 구성요소/네트워크 개요: https://learn.microsoft.com/en-us/azure/databricks/ingestion/lakeflow-connect/
