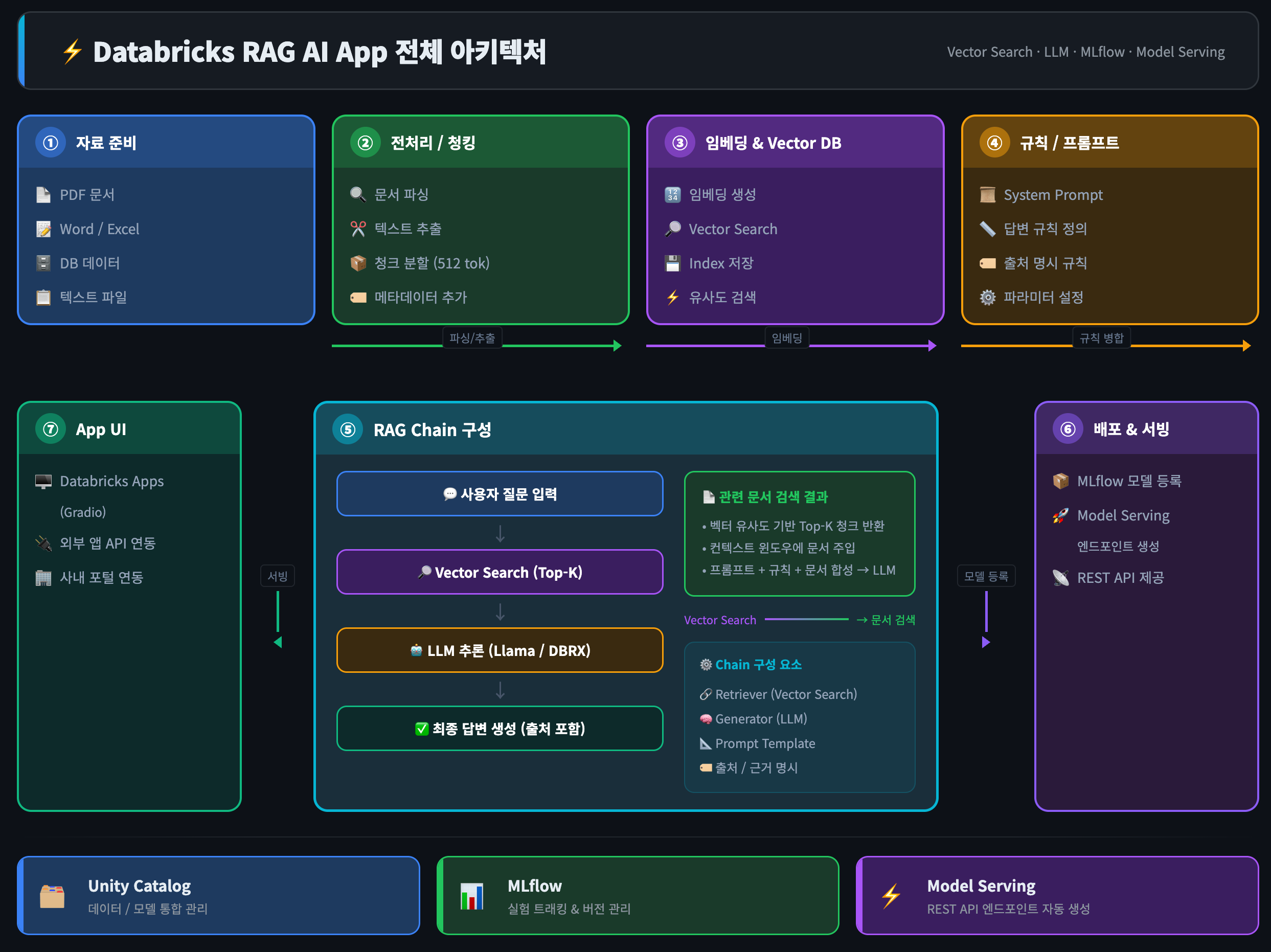
전체 아키텍처 개요
자료 업로드 → 청킹/임베딩 → Vector Store 저장
↓
사용자 질문 → 관련 문서 검색 → LLM 답변 생성 → 앱 UI단계별 과정
1단계: 환경 준비
Databricks에서 필요한 것들
- Unity Catalog - 데이터/모델 관리
- MLflow - 모델 트래킹
- Databricks Vector Search - 벡터 DB
- Model Serving - API 엔드포인트
- Foundation Model API - LLM (DBRX, Meta Llama, 외부 GPT-4 등)
2단계: 자료 준비 및 전처리
# PDF, Word, Excel, 텍스트 등 수집
# Databricks 볼륨(Unity Catalog)에 업로드
raw_docs = spark.read.format("binaryFile")
.load("/Volumes/catalog/schema/volume/docs/")청킹(Chunking) 처리
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50
)
chunks = splitter.split_documents(documents)3단계: 임베딩 & Vector Search 저장
# Databricks Vector Search 엔드포인트 생성
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient()
vsc.create_endpoint(name="my_rag_endpoint")
# Delta Table → Vector Index 자동 동기화
vsc.create_delta_sync_index(
endpoint_name="my_rag_endpoint",
index_name="catalog.schema.doc_index",
source_table_name="catalog.schema.chunked_docs",
pipeline_type="TRIGGERED", # or CONTINUOUS
primary_key="id",
embedding_source_column="content",
embedding_model_endpoint_name="databricks-bge-large-en"
)4단계: 규칙/프롬프트 설정 (핵심!)
system_prompt = """
당신은 [회사명] 전용 AI 어시스턴트입니다.
[규칙]
1. 반드시 제공된 문서 내용만을 기반으로 답변하세요
2. 문서에 없는 내용은 "해당 내용은 자료에 없습니다"라고 답하세요
3. 답변 시 출처 문서명을 반드시 명시하세요
4. 외부 지식이나 추측으로 답변하지 마세요
5. 답변은 한국어로 작성하세요
[제공 문서]
{context}
[질문]
{question}
"""5단계: RAG Chain 구성
from langchain.chains import RetrievalQA
from databricks_langchain import ChatDatabricks, DatabricksVectorSearch
# Vector Search 리트리버
retriever = DatabricksVectorSearch(
index_name="catalog.schema.doc_index",
columns=["content", "source_file"]
).as_retriever(search_kwargs={"k": 5})
# LLM 설정
llm = ChatDatabricks(
endpoint="databricks-meta-llama-3-1-70b-instruct",
temperature=0.1 # 낮을수록 규칙 준수
)
# Chain 연결
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type_kwargs={"prompt": system_prompt}
)6단계: MLflow로 모델 등록 & 배포
import mlflow
# Chain 등록
with mlflow.start_run():
mlflow.langchain.log_model(
rag_chain,
artifact_path="rag_chain",
registered_model_name="my_rag_app"
)
# Model Serving 엔드포인트 배포
# Databricks UI → Serving → Create Endpoint
# 또는 API로 자동화7단계: 앱 UI 구성
옵션 1: Databricks Apps (가장 간단) ✅
# Gradio 기반으로 Databricks 내에서 바로 호스팅
import gradio as gr
def chat(message, history):
response = rag_chain.invoke({"query": message})
return response["result"]
app = gr.ChatInterface(
fn=chat,
title="회사 전용 AI 도우미",
description="내부 문서 기반으로만 답변합니다"
)옵션 2: 외부 앱과 API 연동
Databricks Model Serving API
↓
React / Vue / 사내 포털 연동전체 흐름 요약
① 문서 업로드 (Unity Catalog Volume)
② 전처리 + 청킹 (Notebook/Job)
③ 임베딩 → Vector Search Index
④ System Prompt로 규칙 정의
⑤ RAG Chain 구성 (LangChain)
⑥ MLflow 등록 → Model Serving 배포
⑦ Gradio/Databricks Apps or 외부 연동난이도 & 소요 기간 참고
| 단계 | 난이도 | 소요 시간 |
|---|---|---|
| 환경 세팅 | 중 | 1~2일 |
| 데이터 파이프라인 | 중 | 2~3일 |
| RAG Chain 구성 | 중상 | 2~3일 |
| 앱 UI 개발 | 낮~중 | 1~2일 |
| 테스트/튜닝 | 중 | 3~5일 |
총 약 2~3주면 MVP 수준 구현 가능
자료 형태(PDF, DB, Excel 등), 사용자 수, 보안 요구사항에 따라 세부 아키텍처는 달라질 수 있습니다.

AI를 꿈꾸는 BackEnd개발자