데이터팀/BI팀이 아니더라도 “지난달 결제 전환율이 뭐야?” 같은 질문을 자연어로 던지면, 시스템이 알아서 SQL을 만들고 DB에서 조회해 결과를 보여주는 흐름이 Text-to-SQL입니다. 핵심은 단순히 SQL을 생성하는 게 아니라, 스키마를 정확히 이해하고(정확도), 실행 가능한 쿼리만 만들고(신뢰성), 권한/보안까지 지키는 것(안전성)입니다.
1) Text-to-SQL의 기본 개념
Text-to-SQL은 사용자의 자연어 질문(NL Query)을 데이터베이스가 이해할 수 있는 SQL로 변환하는 기술/시스템입니다. (최근엔 LLM + RAG + 검증 루프 형태가 사실상 표준 패턴이 되어가고 있어요.)
2) 왜 어려운가? (실무에서 터지는 3가지 문제)
1) 스키마 인지 부족: 테이블/컬럼이 수백~수천 개면 LLM이 “어떤 컬럼이 실제로 존재하는지”부터 헷갈립니다. 그래서 스키마 인코딩/링킹이 중요해졌고, 이 축을 강하게 다룬 연구가 RAT-SQL 입니다. 이 논문은 “보지 못한 스키마(새 DB)에 일반화”가 핵심 난점임을 명시합니다. Source
2) 문법적으로 깨진 SQL: LLM은 종종 괄호, JOIN, GROUP BY 조건 등을 틀려서 실행 불가 SQL을 내놓습니다. 이를 “디코딩 단계에서” 강제 제약으로 막는 접근이 PICARD 입니다(토큰을 한 글자/조각씩 뽑을 때, 불가능한 토큰을 거부). Source
3) 보안/권한 문제(특히 SQL Injection + 데이터 유출): Text-to-SQL은 “사용자 입력 → SQL” 경로가 생기기 때문에, 검증/권한/파라미터 바인딩 같은 전통 보안 원칙을 그대로 적용해야 합니다. OWASP는 Prepared Statement(파라미터 쿼리), Stored Procedure(안전 구성), Allow-list 검증 등을 핵심 방어로 권고합니다. Source
3) 대표 벤치마크: Spider 데이터셋
Text-to-SQL 성능 비교에서 가장 유명한 벤치마크 중 하나가 Spider 입니다. 단순 문자열 비교가 아니라 SQL을 절(clause) 단위로 분해해 set 비교를 하는 등 구조적 정확도를 보려는 평가 체계를 제공합니다. Source
이미지 출처: Yale LILY Lab Spider
4) 실무용 Text-to-SQL 아키텍처(권장)
아래는 “그냥 LLM에 물어보기”를 넘어, 실제 제품에서 안정적으로 굴리는 권장 아키텍처입니다.
4.1 전체 흐름(요약)
flowchart LR
U[User Question] --> G[Guardrails: intent/permission check]
G --> R[Schema & Context Retrieval (RAG)]
R --> P[Prompt Builder: schema + examples + constraints]
P --> L[LLM SQL Generation]
L --> V[Validator: parse / lint / dry-run]
V -->|OK| X[Execute (read-only) + postprocess]
V -->|Error| F[Feedback: error message + retry loop]
F --> L4.2 “Google Cloud”식 품질 개선 포인트 (Google Cloud Blog)
Google Cloud는 Text-to-SQL 정확도를 올리기 위해 (1) 관련 테이블/컬럼의 지능형 검색(벡터 검색 등), (2) 비즈니스 예시를 ICL로 제공, (3) 데이터 샘플링/시맨틱 레이어, (4) self-consistency(여러 후보 생성 후 선택), (5) dry-run/파싱 기반 검증 후 재작성 같은 기법을 조합한다고 정리합니다. Source
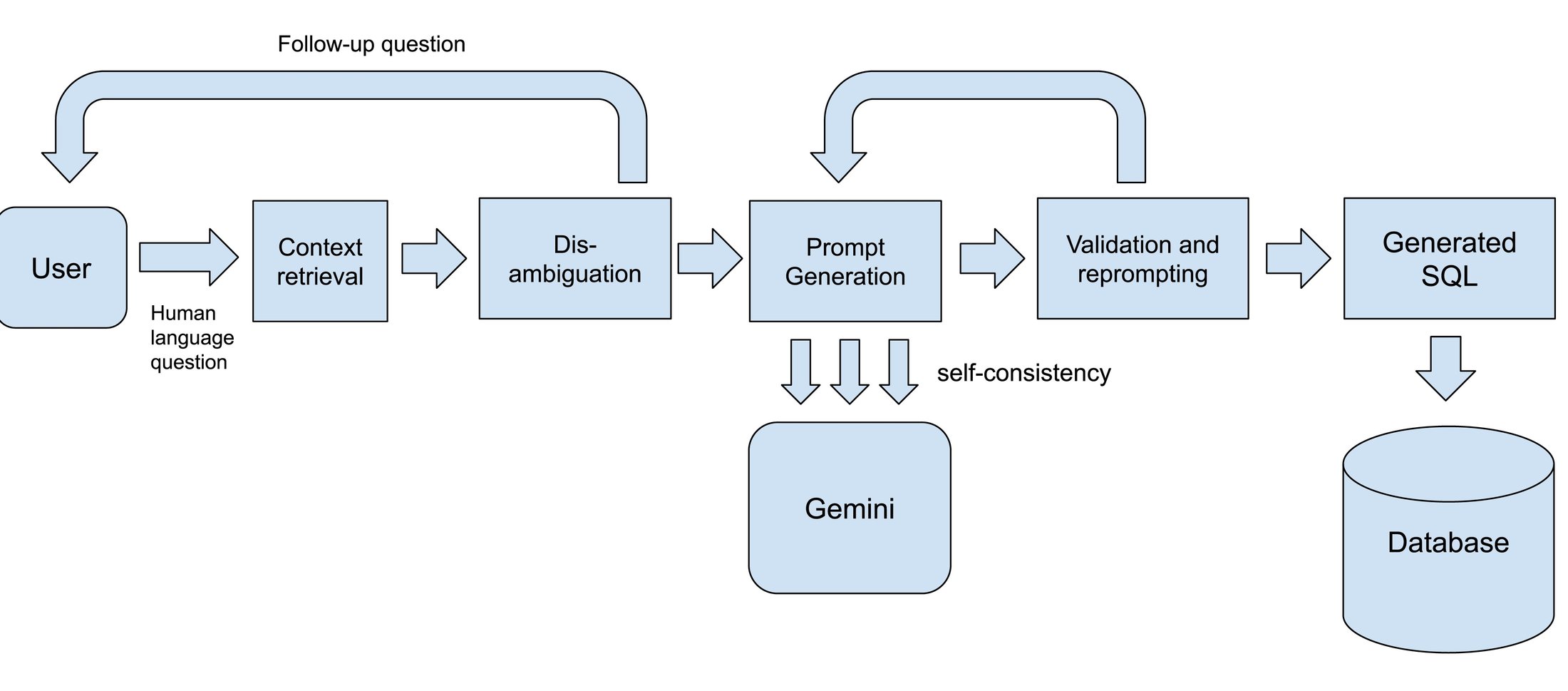
이미지 출처: Google Cloud Blog
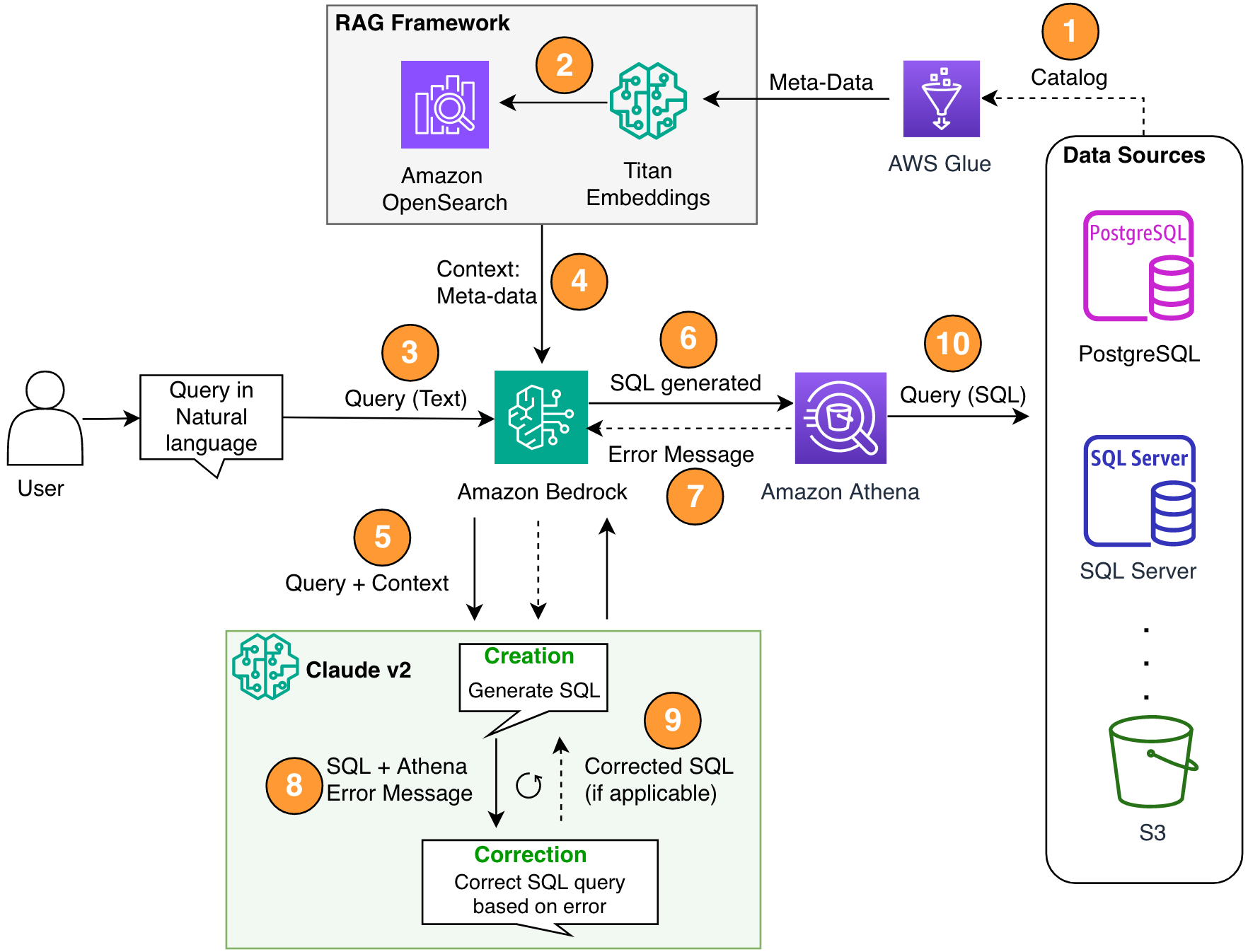
4.3 “AWS”식 견고한 패턴: RAG + 자기수정 루프 (AWS Machine Learning Blog)
AWS는 견고한 Text-to-SQL을 위해 (1) DB 메타데이터 기반 RAG, (2) 멀티스텝 self-correction loop, (3) SQL 엔진(Athena)에서 에러를 받아 재프롬프트를 핵심 구성요소로 설명합니다. 즉 “LLM이 SQL을 만들고 → 엔진이 문법/실행 오류를 주고 → 그 오류를 다시 LLM에 먹여 고치게 하는” 반복 구조입니다. Source
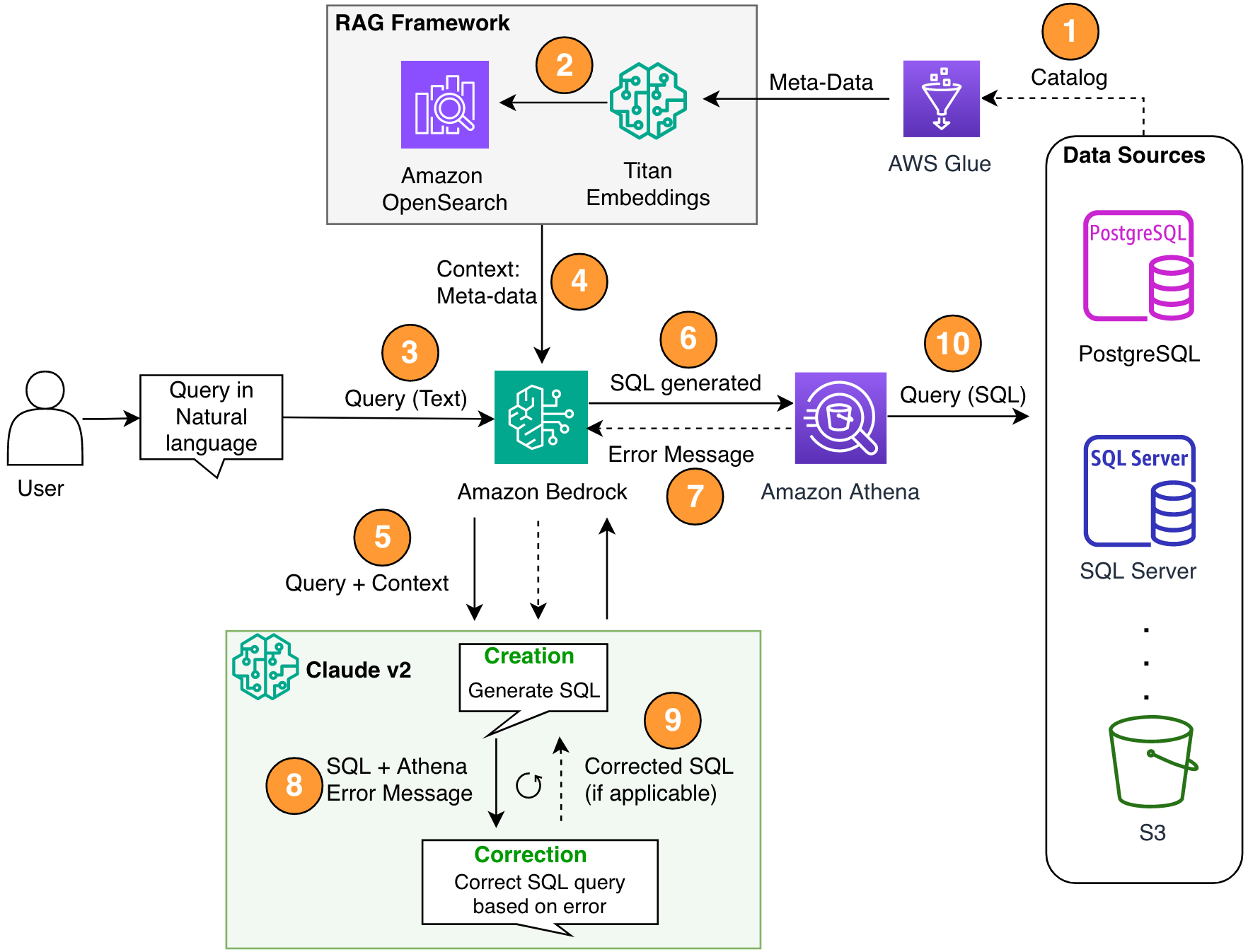
이미지 출처: AWS Machine Learning Blog
5) 사용법(실무 템플릿): “스키마 넣고, 예시 넣고, 검증하고, 실행”
5.1 프롬프트 구성(최소 권장)
- DB Dialect(Postgres/BigQuery/MySQL 등)
- 허용 범위(SELECT only, limit 강제 등)
- 스키마 컨텍스트(관련 테이블/컬럼만!)
- 비즈니스 규칙/용어 사전
- 출력 포맷 강제(JSON으로
sql,reason,tables_used등)
예시(개념):
You are a data assistant. Generate a single SQL query.
Rules:
- Read-only SELECT only. No INSERT/UPDATE/DELETE/DDL.
- Must include LIMIT 100 unless user asks otherwise.
- Use only the provided schema. Do not hallucinate columns.
Schema:
- orders(order_id, user_id, created_at, total_amount, status)
- users(user_id, signup_date, country)
Question:
"지난 30일간 국가별 매출 합계를 보여줘"5.2 “검증”이 제품 퀄리티를 만든다
권장 검증 체크리스트:
- SQL 파서/린터로 문법 검증
- 실제 엔진에 dry-run(가능하면 실행 계획만)
- 결과 row 수 상한, 쿼리 시간 제한
- 접근 가능한 테이블/컬럼 allow-list 확인
Google Cloud도 dry-run/파싱으로 결정적 신호를 얻고, 이를 재작성 프롬프트로 넣는 방식을 강조합니다. Source
6) 보안: Text-to-SQL에서 특히 중요한 것들 (OWASP)
Text-to-SQL은 “LLM이 SQL을 만든다”는 특수성이 있어도, 보안 원칙은 바뀌지 않습니다.
- Prepared Statements(파라미터 바인딩) 권장
- Stored Procedure(올바르게 구성된 경우)
- Allow-list 입력 검증(테이블명/정렬키처럼 바인딩 불가한 곳)
- “모든 입력 escape”는 강력 비권장으로 분류됩니다. Source
실무 팁(자주 먹히는 조합):
- DB 계정은 read-only + 최소 권한(least privilege)
- 민감 컬럼은 뷰/시맨틱 레이어로 가리고, RAG에도 노출 최소화
- 쿼리 실행 전 정책 엔진(예:
SELECT *금지, 특정 테이블 접근 금지)
7) (옵션) 연구 관점에서의 구성요소: RAT-SQL과 PICARD
- RAT-SQL: 보지 못한 DB 스키마에 일반화하기 어려운 문제를 “관계 인지 self-attention”으로 풀어 스키마 인코딩/링킹을 개선하는 프레임워크를 제안합니다. Spider에서 정확도를 크게 끌어올렸다고 요약합니다. Source
- PICARD: SQL처럼 제약된 형식 언어에서 LLM이 invalid 출력을 내는 문제를 “증분 파싱 기반 제약 디코딩”으로 완화합니다. Spider/CoSQL에서 성능 향상을 보고합니다. Source
8) 마무리: 추천 구현 순서(가장 빠르게 가치 내는 로드맵)
1) 스키마/메타데이터 RAG부터 붙이기 (정확도 체감이 큼)
2) 검증(dry-run) + 에러 피드백 루프로 “실행 가능 SQL” 만들기
3) 권한/보안(OWASP + 최소권한)을 제품 요구사항으로 고정
4) 이후 self-consistency, 예시 학습(ICL), 시맨틱 레이어로 고도화 Source
원하시면, 사용 중인 환경에 맞춰서(예: BigQuery / Postgres / MySQL, 또는 dbt/semantic layer 유무) 프롬프트 템플릿 + RAG에 넣을 “스키마 요약 포맷” + 검증/재시도 정책까지 한 번에 블로그용 예제로 다듬어드릴게요. 어떤 DB와 SQL 방언을 쓰시나요?
