Apache Kafka는 현대적인 데이터 스트리밍 플랫폼의 핵심으로, 대규모 실시간 데이터를 효율적으로 처리할 수 있습니다. 이 글에서는 Kafka의 토픽 설정과 파티션 전략에 대한 모범 사례를 살펴보겠습니다.
카프카 아키텍처 이해하기
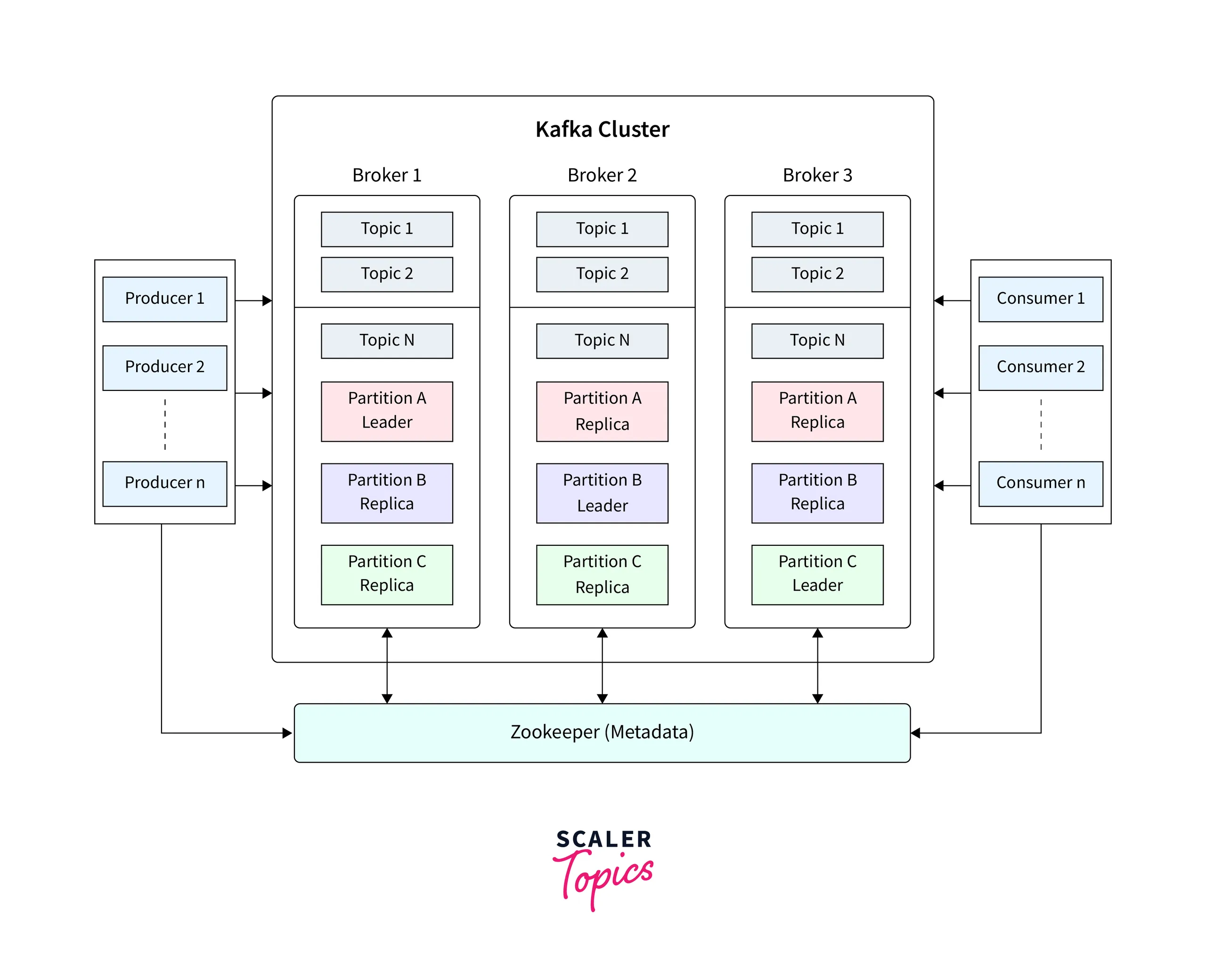
Kafka는 토픽(Topic), 파티션(Partition), 프로듀서(Producer), 컨슈머(Consumer)로 구성된 분산 메시징 시스템입니다. 효율적인 데이터 처리를 위해서는 이러한 구성 요소들을 올바르게 설정하는 것이 중요합니다.
1. 카프카 토픽이란?
토픽은 Kafka에서 메시지를 분류하는 논리적인 단위입니다. 데이터베이스의 테이블과 유사하게, 특정 유형의 데이터를 저장하고 관리하는 공간으로 생각할 수 있습니다.
토픽의 주요 특징
- 메시지 스트림: 시간 순서대로 정렬된 메시지의 연속적인 흐름
- 파티셔닝: 각 토픽은 여러 파티션으로 나뉘어 병렬 처리 가능
- 보존 정책: 메시지의 보관 기간을 설정 가능
- 복제: 데이터 안정성을 위한 복제 메커니즘 제공
2. 파티션의 이해
파티션은 Kafka의 확장성과 병렬 처리의 핵심입니다. 각 파티션은 독립적으로 작동하며, 메시지를 순서대로 저장합니다.
파티션의 작동 방식
- 순차 저장: 각 파티션 내에서 메시지는 순서가 보장됩니다
- 오프셋: 각 메시지는 파티션 내에서 고유한 오프셋을 가집니다
- 병렬 처리: 여러 컨슈머가 서로 다른 파티션을 동시에 읽을 수 있습니다
- 로드 밸런싱: 파티션은 브로커 간에 분산되어 부하를 분산합니다
3. 파티션 수 결정 전략
파티션 수는 Kafka 클러스터의 성능에 직접적인 영향을 미칩니다. 적절한 파티션 수를 선택하는 것이 중요합니다.
파티션 수 결정 시 고려사항
✅ 처음에는 작게 시작하기
- 초기에는 1-3개의 파티션으로 시작하는 것을 권장합니다
- 파티션은 나중에 증가시킬 수 있지만 감소는 불가능합니다
- 초보자는 파티션 수를 과대평가하는 경향이 있으니 주의가 필요합니다
✅ 처리량 기반 계산
파티션 수 = max(예상 프로듀서 처리량 / 파티션당 프로듀서 처리량,
예상 컨슈머 처리량 / 파티션당 컨슈머 처리량)✅ 병렬 처리 고려
- 컨슈머 그룹의 동시 처리를 위해 파티션 수를 설정합니다
- 일반적으로 파티션 수는 동시 컨슈머 수와 일치시키는 것이 이상적입니다
- 파티션이 컨슈머보다 적으면 일부 컨슈머는 유휴 상태가 됩니다
4. 파티션 키 전략
파티션 키는 메시지가 어떤 파티션에 저장될지 결정하는 중요한 요소입니다.
파티션 키 선택 방법
1. 키가 있는 경우
- Kafka는 키의 해시값을 사용하여 파티션을 결정합니다
- 같은 키를 가진 메시지는 항상 같은 파티션에 저장됩니다
- 순서 보장이 필요한 경우 적합합니다 (예: 사용자 ID, 주문 ID)
// 예시: 사용자 ID를 키로 사용
producer.send(new ProducerRecord<>("user-events", userId, eventData));2. 키가 없는 경우
- Kafka는 라운드 로빈(Round-Robin) 방식으로 파티션을 선택합니다
- 모든 파티션에 균등하게 메시지를 분산합니다
- 순서가 중요하지 않은 로그 데이터에 적합합니다
Medium Article on Kafka Partitioning
3. 커스텀 파티셔너
- 특정 비즈니스 로직에 따라 파티션을 선택할 수 있습니다
- 예: 지역별, 우선순위별 파티셔닝
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// 커스텀 로직 구현
return customPartitionLogic(key);
}
}5. 복제 전략 (Replication)
복제는 Kafka의 내결함성(Fault Tolerance)을 보장하는 핵심 메커니즘입니다.
복제 팩터(Replication Factor) 설정
권장 설정
- 프로덕션 환경: 최소 3
- 중요한 데이터: 3 이상
- 개발/테스트 환경: 1-2
복제의 장점
- ✅ 브로커 장애 시 데이터 손실 방지
- ✅ 고가용성 보장
- ✅ 자동 장애 복구(Failover)
리더와 팔로워
- 리더(Leader): 모든 읽기/쓰기 요청 처리
- 팔로워(Follower): 리더의 데이터를 복제하여 백업
- ISR (In-Sync Replicas): 리더와 동기화된 복제본들의 집합
6. 토픽 설정 모범 사례
6.1 보존 정책 (Retention Policy)
# 시간 기반 보존 (7일)
retention.ms=604800000
# 크기 기반 보존 (1GB)
retention.bytes=1073741824
# 압축 정책
cleanup.policy=delete # 또는 compact보존 정책 선택 가이드
- 로그 데이터: 시간 기반 삭제 (7-30일)
- 이벤트 소싱: 무제한 보존 또는 압축
- 메트릭 데이터: 짧은 보존 기간 (1-7일)
6.2 성능 최적화 설정
# 배치 크기 증가로 처리량 향상
batch.size=32768
# 압축 활성화로 네트워크 대역폭 절약
compression.type=snappy # 또는 lz4, zstd
# 버퍼 메모리 설정
buffer.memory=67108864
# acks 설정 (내구성 vs 성능)
acks=all # 가장 안전, acks=1 (빠름), acks=0 (가장 빠름)6.3 명명 규칙
일관된 토픽 명명 규칙을 사용하면 관리가 쉬워집니다:
<환경>.<서비스>.<데이터타입>.<버전>
예시:
- prod.user-service.events.v1
- dev.payment-service.transactions.v2
- staging.analytics.metrics.v17. 파티션 전략의 함정 피하기
⚠️ 주의해야 할 안티패턴
1. 데이터 스큐(Data Skew)
- 문제: 특정 파티션에 데이터가 집중되는 현상
- 해결: 균등 분산을 보장하는 키 선택, 커스텀 파티셔너 사용
2. 과도한 파티션 수
- 문제: 메타데이터 오버헤드, 리밸런싱 지연
- 해결: 실제 필요한 만큼만 생성, 점진적 증가
3. 파티션 수 감소 시도
- 문제: Kafka는 파티션 수 감소를 지원하지 않음
- 해결: 신중한 초기 설계, 새 토픽 생성 및 마이그레이션
8. 확장성을 위한 계획
스케일 아웃 전략
# 파티션 추가 (기존 토픽)
kafka-topics.sh --alter --topic my-topic \
--partitions 6 \
--bootstrap-server localhost:9092
# 파티션 재할당으로 브로커 간 균형 유지
kafka-reassign-partitions.sh --generate \
--topics-to-move-json-file topics.json \
--broker-list "0,1,2,3,4,5"컨슈머 그룹 확장
- 컨슈머 수 = 파티션 수 (최적)
- 컨슈머 수 > 파티션 수 (일부 유휴 상태)
- 컨슈머 수 < 파티션 수 (컨슈머당 여러 파티션 처리)
9. 모니터링 및 유지보수
주요 메트릭
# 처리량 모니터링
- MessagesInPerSec
- BytesInPerSec
- BytesOutPerSec
# 지연 모니터링
- ConsumerLag
- RequestLatencyMs
# 파티션 상태
- UnderReplicatedPartitions
- OfflinePartitionsCount유지보수 팁
- 정기적인 파티션 밸런싱 확인
- 컨슈머 랙(Lag) 모니터링으로 처리 지연 감지
- 디스크 사용량 추적 및 보존 정책 조정
- 브로커 리소스 (CPU, 메모리, 네트워크) 모니터링
10. 실전 체크리스트
토픽 생성 전 확인사항
- 데이터 접근 패턴 분석 완료
- 적절한 파티션 수 계산
- 파티션 키 전략 수립
- 복제 팩터 결정 (최소 3 권장)
- 보존 정책 설정
- 명명 규칙 준수
- 압축 타입 선택
- 모니터링 설정 완료
프로덕션 배포 전 체크
- 부하 테스트 수행
- 장애 복구 시나리오 테스트
- 백업 및 복구 전략 수립
- 알람 및 모니터링 구성
- 문서화 완료
결론
Apache Kafka의 토픽 설정과 파티션 전략은 시스템 성능과 확장성에 결정적인 영향을 미칩니다. 다음 핵심 원칙을 기억하세요:
- 작게 시작하여 점진적으로 확장 - 파티션은 나중에 추가 가능하지만 감소는 불가능
- 데이터 패턴에 맞는 키 전략 - 순서가 중요하면 키 사용, 그렇지 않으면 라운드 로빈
- 적절한 복제로 안정성 확보 - 프로덕션 환경에서는 최소 3개의 복제본
- 지속적인 모니터링 - 컨슈머 랙, 처리량, 파티션 밸런스 추적
- 확장성을 염두에 둔 설계 - 미래의 성장을 고려한 아키텍처
Kafka를 효과적으로 활용하면 대규모 실시간 데이터 처리 시스템을 안정적으로 운영할 수 있습니다. 이 가이드가 여러분의 Kafka 여정에 도움이 되기를 바랍니다! 🚀
참고 자료:
