데이터 엔지니어링과 분석 작업에서 효율적인 워크플로우 관리는 매우 중요합니다. 데이터브릭스(Databricks)에서는 DAG(Directed Acyclic Graph)라는 개념을 통해 복잡한 데이터 처리 작업을 체계적으로, 시각적으로 관리할 수 있습니다. 이 글에서는 데이터브릭스에서 DAG가 무엇인지, 어떻게 활용할 수 있는지 상세히 알아보겠습니다.
DAG란 무엇인가?
DAG는 'Directed Acyclic Graph'의 약자로, '방향성 비순환 그래프'라는 의미입니다. 여기서:
- Directed(방향성): 각 작업 간의 관계에 방향이 있습니다. 즉, 작업 A가 작업 B에 선행해야 한다는 것을 명확히 표현할 수 있습니다.
- Acyclic(비순환): 그래프 내에 순환 구조가 없습니다. 이는 작업 A → 작업 B → 작업 C → 작업 A와 같이 무한히 반복되는 구조가 생기지 않도록 합니다.
- Graph(그래프): 노드(작업)와 엣지(작업 간의 관계)로 구성된 구조입니다.
데이터브릭스에서 DAG는 데이터 처리 워크플로우를 시각적으로 표현하고 관리하는 방식으로, 특히 Apache Spark 실행 엔진과 Databricks Workflows에서 중요한 역할을 합니다.
데이터브릭스에서 DAG의 두 가지 측면
데이터브릭스에서 DAG는 크게 두 가지 측면에서 활용됩니다:
- Apache Spark 실행 엔진의 DAG: Spark가 내부적으로 데이터 처리 작업을 최적화하기 위해 사용하는 실행 계획
- Databricks Workflows에서의 DAG: 여러 작업(Task)을 조율하고 관리하기 위한 시각적 워크플로우 구조
이 두 측면을 각각 자세히 살펴보겠습니다.
1. Apache Spark 실행 엔진의 DAG
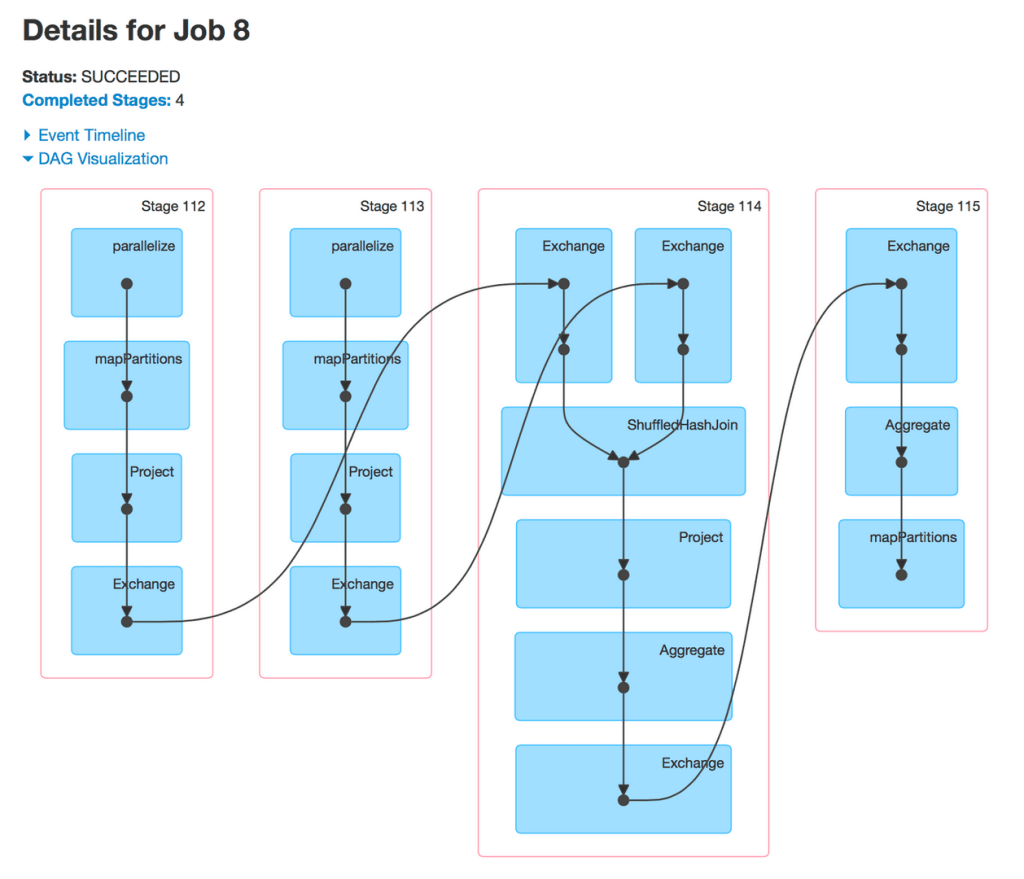
Apache Spark에서 DAG는 Spark의 실행 엔진이 데이터 처리 작업을 어떻게 최적화하고 실행할지를 나타내는 내부적인 실행 계획입니다. 사용자가 Spark 코드를 작성하면, Spark는 이를 논리적 실행 계획으로 변환한 후 최적화된 물리적 실행 계획(DAG)으로 전환합니다.
Spark의 DAG는 다음과 같은 구성 요소를 가집니다:
- RDD(Resilient Distributed Dataset) 또는 DataFrame/Dataset에 대한 작업들
- 변환(Transformation) 및 액션(Action) 연산
- 스테이지(Stage): 셔플 작업에 의해 구분되는 실행 단계
- 태스크(Task): 각 파티션에서 실행되는 최소 작업 단위
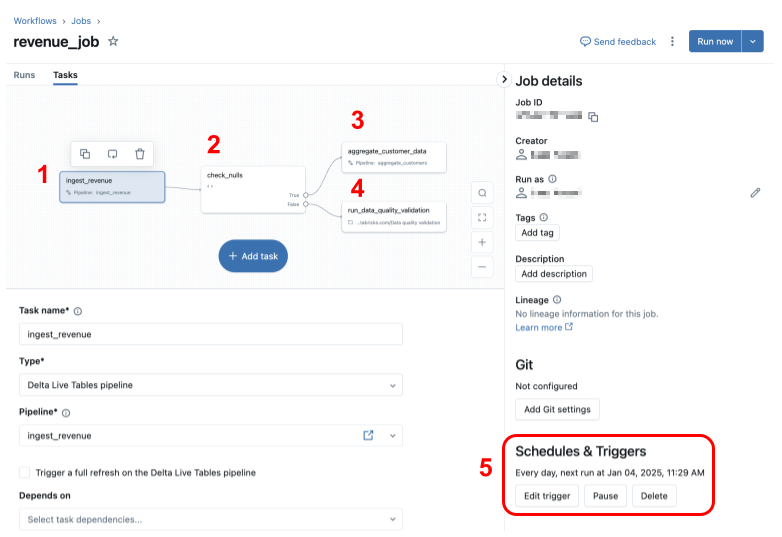
2. Databricks Workflows에서의 DAG
Databricks Workflows는 데이터브릭스에서 제공하는 작업 오케스트레이션 서비스로, 여러 데이터 처리 작업을 조율하고 예약할 수 있게 해줍니다. 여기서 DAG는 작업 간의 종속성과 실행 순서를 시각적으로 표현합니다.
Workflows의 DAG는 다음 특징을 가집니다:
- 작업(Job): 전체 워크플로우를 의미합니다.
- 태스크(Task): 작업 내의 개별 실행 단위입니다(노트북, 파이썬 스크립트, SQL 쿼리 등).
- 종속성(Dependencies): 태스크 간의 실행 순서를 정의합니다.
- 조건부 로직(Conditional Logic): if/else 구문을 통한 분기 처리가 가능합니다.
- 트리거(Trigger): 작업의 실행 시점을 결정합니다(예약, 이벤트 기반).
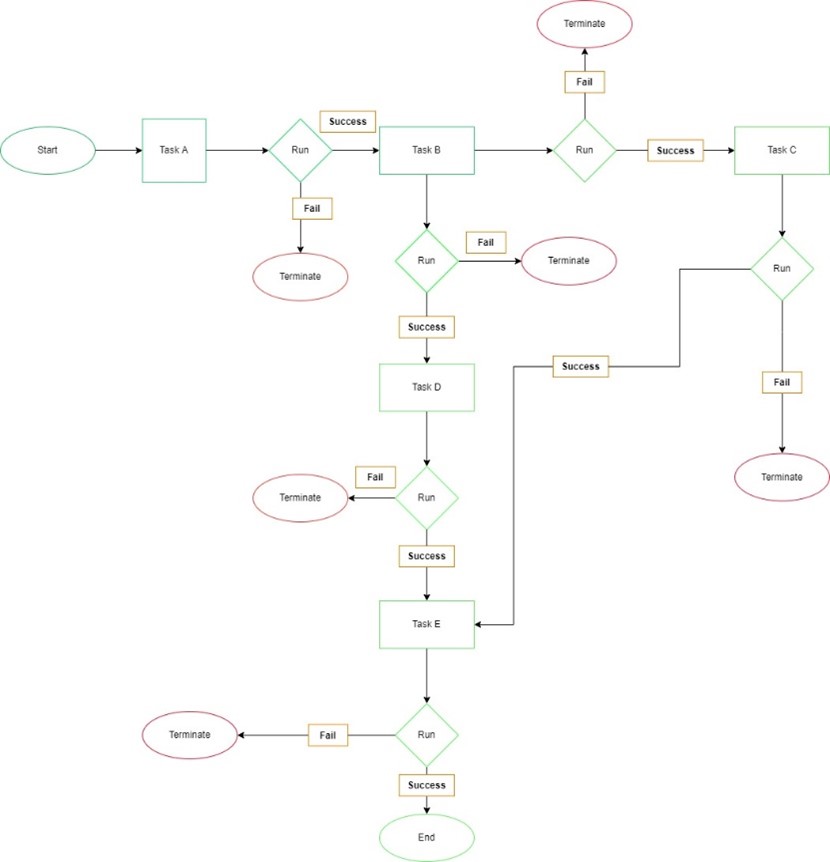
데이터브릭스에서 DAG 사용법
Databricks Workflows에서 DAG 생성하기
데이터브릭스에서 워크플로우 DAG를 생성하는 기본 단계는 다음과 같습니다:
- 워크플로우 생성: 데이터브릭스 UI에서 Workflows 섹션으로 이동하여 새 작업을 생성합니다.
- 첫 번째 태스크 구성: 노트북, SQL, Python 스크립트 등 첫 번째 태스크를 추가합니다.
- 추가 태스크 구성: 필요한 만큼 태스크를 추가하고 각각의 설정을 구성합니다.
- 태스크 간 종속성 설정: 태스크 간의 실행 순서를 설정하여 DAG 구조를 만듭니다.
- 조건부 로직 추가(선택 사항): if/else 태스크를 통해 조건부 실행 흐름을 만듭니다.
- 트리거 설정: 일정, 이벤트 등 워크플로우의 트리거 조건을 설정합니다.
다음은 간단한 데이터 처리 워크플로우 DAG 예시입니다:
Copy# 이 코드는 Databricks Workflows UI에서 시각적으로 구성하는 것을 코드로 표현한 개념적인 예시입니다
# 1. 데이터 수집 태스크
ingest_task = NotebookTask(
notebook_path="/path/to/ingest_notebook",
parameters={"data_source": "s3://my-bucket/data"}
)
# 2. 데이터 변환 태스크
transform_task = NotebookTask(
notebook_path="/path/to/transform_notebook",
parameters={}
)
# 3. 데이터 검증 태스크
validate_task = NotebookTask(
notebook_path="/path/to/validate_notebook",
parameters={}
)
# 4. 데이터 적재 태스크
load_task = NotebookTask(
notebook_path="/path/to/load_notebook",
parameters={"destination": "delta://my-table"}
)
# 종속성 설정: 수집 -> 변환 -> 검증 -> 적재
transform_task.depends_on(ingest_task)
validate_task.depends_on(transform_task)
load_task.depends_on(validate_task)
프로그래매틱 방식으로 워크플로우 DAG 관리하기
데이터브릭스는 UI 외에도 프로그래매틱 방식으로 워크플로우 DAG를 관리할 수 있는 다양한 도구를 제공합니다:
- Databricks CLI: 커맨드 라인 인터페이스를 통한 작업 관리
- Databricks Asset Bundles: 코드로 작업을 정의하고 관리
- REST API: HTTP 요청을 통한 작업 생성 및 관리
- Databricks SDK: 프로그래밍 언어를 통한 작업 관리
예를 들어, Databricks CLI를 사용하여 작업을 생성하는 방법은 다음과 같습니다:
Copy# JSON 파일에 작업 정의
cat > job.json << EOF
{
"name": "데이터 처리 파이프라인",
"email_notifications": {
"on_failure": ["user@example.com"]
},
"tasks": [
{
"task_key": "ingest",
"notebook_task": {
"notebook_path": "/path/to/ingest_notebook",
"base_parameters": {
"data_source": "s3://my-bucket/data"
}
}
},
{
"task_key": "transform",
"notebook_task": {
"notebook_path": "/path/to/transform_notebook"
},
"depends_on": [
{
"task_key": "ingest"
}
]
}
]
}
EOF
# Databricks CLI를 사용하여 작업 생성
databricks jobs create --json-file job.json
데이터브릭스 DAG의 고급 기능
1. 조건부 워크플로우
Databricks Workflows는 if/else 구문을 통한 조건부 실행을 지원합니다. 이를 통해 이전 태스크의 결과에 따라 다른 경로로 워크플로우를 진행할 수 있습니다.
Copy# 조건부 작업 흐름의 개념적인 예시
if_task = IfElseTask(
condition="${tasks.validate.result == 'PASS'}",
true_task="load_to_production",
false_task="send_alert"
)
2. 반복 워크플로우
For Each 태스크를 통해 컬렉션의 각 항목에 대해 동일한 작업을 반복 실행할 수 있습니다.
Copy# For Each 작업 흐름의 개념적인 예시
for_each_task = ForEachTask(
items=["item1", "item2", "item3"],
task="process_item",
parameters={"item_name": "{{item}}"}
)
3. 오류 처리 및 재시도 정책
태스크 실행 실패 시의 동작을 정의할 수 있습니다:
- 재시도 횟수 및 간격 설정
- 시간 초과 설정
- 실패 시 알림 구성
Copy# 재시도 정책 설정 예시
task = NotebookTask(
notebook_path="/path/to/notebook",
parameters={},
retry_policy={
"max_retries": 3,
"min_retry_interval_millis": 60000 # 1분
},
timeout_seconds=3600 # 1시간
)
Apache Airflow와 데이터브릭스 워크플로우 비교
데이터브릭스 워크플로우 외에도 Apache Airflow를 사용하여 데이터브릭스 작업을 오케스트레이션할 수 있습니다. 두 접근 방식의 주요 차이점은 다음과 같습니다:
Apache Airflow
- DAG를 Python 코드로 정의
- 다양한 시스템과의 통합 지원
- 강력한 스케줄링 기능
- 풍부한 운영자(Operator) 생태계
- 독립적인 오케스트레이션 시스템
Airflow DAG 예시:
Copyfrom airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'airflow'
}
with DAG('databricks_workflow',
start_date = days_ago(2),
schedule_interval = None,
default_args = default_args
) as dag:
task1 = DatabricksRunNowOperator(
task_id = 'ingest_data',
databricks_conn_id = 'databricks_default',
job_id = 123456 # 데이터브릭스 작업 ID
)
task2 = DatabricksRunNowOperator(
task_id = 'transform_data',
databricks_conn_id = 'databricks_default',
job_id = 123457 # 데이터브릭스 작업 ID
)
task1 >> task2 # 종속성 설정
데이터브릭스 워크플로우
- 데이터브릭스 내부에 통합된 시스템
- 시각적 DAG 구성 인터페이스
- 노트북, SQL, Python 스크립트 등 직접 통합
- 조건부 로직 기본 지원
- 가벼운 설정과 관리
두 시스템 중 어떤 것을 선택할지는 다음과 같은 요소에 따라 결정할 수 있습니다:
- 기존 인프라 및 통합 요구사항
- 팀의 기술 숙련도
- 워크플로우의 복잡성
- 다른 시스템과의 통합 필요성
데이터브릭스 DAG 모니터링 및 관찰성
데이터브릭스는 워크플로우 DAG의 실행을 모니터링하고 관찰하기 위한 다양한 기능을 제공합니다:
- UI 기반 모니터링: 웹 인터페이스에서 작업 실행 상태, 히스토리, 로그 확인
- 알림: 이메일, 슬랙, 웹훅 등을 통한 작업 실행 상태 알림
- 시스템 테이블: SQL 쿼리를 통한 작업 실행 데이터 접근 및 분석
- 메트릭 및 로그: 각 태스크의 성능 메트릭 및 로그 수집
데이터브릭스 DAG 사용 시 제한사항
데이터브릭스 워크플로우 DAG를 사용할 때 주의해야 할 몇 가지 제한사항이 있습니다:
- 작업 영역당 동시 실행 태스크 수는 2,000개로 제한됩니다.
- 작업 영역은 시간당 최대 10,000개의 작업을 생성할 수 있습니다.
- 작업 영역은 최대 12,000개의 저장된 작업을 포함할 수 있습니다.
- 하나의 작업은 최대 1,000개의 태스크를 포함할 수 있습니다.
결론
데이터브릭스에서 DAG는 데이터 처리 워크플로우를 효율적으로 구성하고 관리하는 핵심 개념입니다. Apache Spark의 내부 실행 엔진에서부터 Databricks Workflows의 시각적 작업 관리까지, DAG는 데이터 엔지니어링 작업을 체계화하고 최적화하는 데 중요한 역할을 합니다.
이 글에서 살펴본 대로, 데이터브릭스에서 DAG를 사용하면 복잡한 데이터 처리 워크플로우를 시각적으로 명확하게 표현하고, 조건부 로직이나 반복 작업 같은 고급 기능을 활용할 수 있으며, 프로그래매틱 방식으로도 관리할 수 있습니다.
데이터 엔지니어링 작업의 복잡성이 증가함에 따라, DAG 기반의 워크플로우 관리는 점점 더 중요해지고 있습니다. 데이터브릭스의 DAG 기능을 효과적으로 활용하면 더욱 안정적이고 유지보수가 용이한 데이터 파이프라인을 구축할 수 있을 것입니다.
참고 자료
