
웹 개발과 테스팅 분야에서 빠질 수 없는 도구, 셀레니움(Selenium)에 대해 알아보겠습니다. 반복적인 웹 작업을 자동화하고 싶거나, 웹 애플리케이션을 테스트하고 싶다면 이 글이 도움이 될 것입니다!
셀레니움이란? 🤔
- *셀레니움(Selenium)**은 웹 브라우저를 자동으로 제어할 수 있게 해주는 오픈소스 도구입니다. 마치 사람이 직접 마우스를 클릭하고 키보드를 타이핑하는 것처럼, 프로그램이 웹 페이지와 상호작용할 수 있게 해줍니다.
주요 특징
- 크로스 브라우저 지원: Chrome, Firefox, Safari, Edge 등 모든 주요 브라우저 지원
- 다양한 언어 지원: Python, Java, C#, Ruby, JavaScript 등
- 무료 오픈소스: 상업적 용도로도 자유롭게 사용 가능
- 강력한 커뮤니티: 전 세계 개발자들이 사용하는 검증된 도구
셀레니움으로 할 수 있는 일들 ✨
1. 웹 애플리케이션 테스팅
- 로그인/로그아웃 테스트
- 폼 제출 테스트
- 페이지 네비게이션 테스트
- UI 요소 검증
2. 웹 스크래핑
- 동적 콘텐츠 수집
- 페이지네이션 처리
- AJAX 요청 처리
3. 반복 작업 자동화
- 데이터 입력 자동화
- 보고서 생성 자동화
- 온라인 쇼핑 자동화
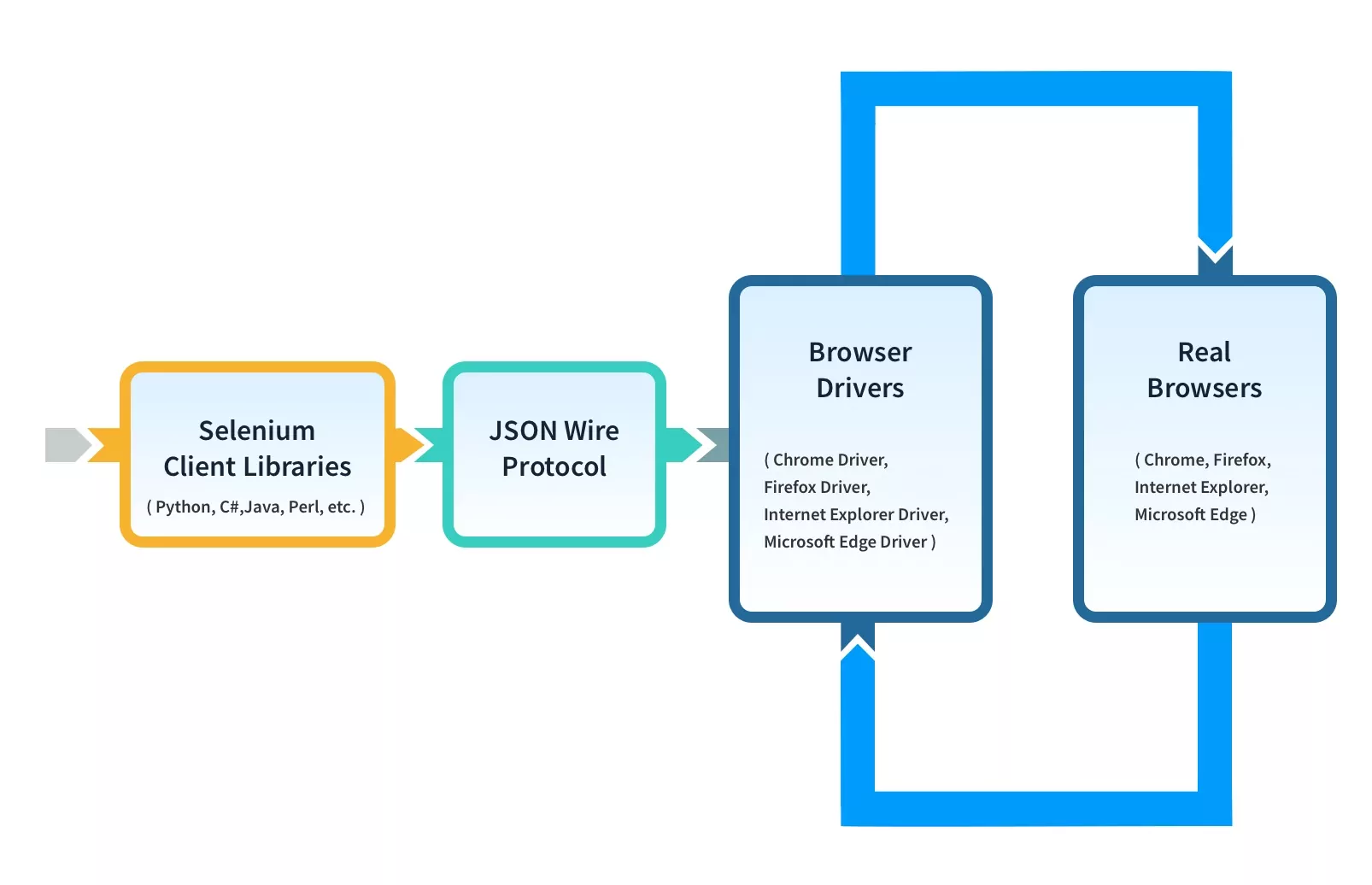
셀레니움 설치하기 📦
Python 환경에서 설치
Copy# 셀레니움 설치
pip install selenium
# 브라우저 드라이버 자동 관리 도구 설치
pip install webdriver-manager
필요한 브라우저 드라이버
셀레니움은 각 브라우저별로 드라이버가 필요합니다:
- Chrome: ChromeDriver
- Firefox: GeckoDriver
- Safari: SafariDriver
- Edge: EdgeDriver
webdriver-manager를 사용하면 드라이버를 자동으로 다운로드하고 관리할 수 있습니다!
기본 사용법 🛠️
1. 기본 브라우저 열기
Copyfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Chrome 브라우저 자동 설정
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 웹 페이지 열기
driver.get("https://www.google.com")
# 페이지 제목 출력
print(driver.title)
# 브라우저 종료
driver.quit()
2. 요소 찾기와 상호작용
Copyfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
# 브라우저 설정
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
try:
# Google 검색 페이지로 이동
driver.get("https://www.google.com")
# 검색창 찾기
search_box = driver.find_element(By.NAME, "q")
# 검색어 입력
search_box.send_keys("셀레니움 사용법")
# Enter 키 누르기
search_box.send_keys(Keys.RETURN)
# 3초 대기
time.sleep(3)
# 첫 번째 검색 결과 클릭
first_result = driver.find_element(By.CSS_SELECTOR, "h3")
first_result.click()
# 5초 대기
time.sleep(5)
finally:
# 브라우저 종료
driver.quit()
3. 다양한 요소 선택 방법
Copyfrom selenium.webdriver.common.by import By
# ID로 찾기
element = driver.find_element(By.ID, "myId")
# 클래스명으로 찾기
element = driver.find_element(By.CLASS_NAME, "myClass")
# 태그명으로 찾기
element = driver.find_element(By.TAG_NAME, "div")
# CSS 선택자로 찾기
element = driver.find_element(By.CSS_SELECTOR, ".myClass > div")
# XPath로 찾기
element = driver.find_element(By.XPATH, "//div[@class='myClass']")
# 링크 텍스트로 찾기
element = driver.find_element(By.LINK_TEXT, "클릭하세요")
# 부분 링크 텍스트로 찾기
element = driver.find_element(By.PARTIAL_LINK_TEXT, "클릭")
실전 예제: 로그인 자동화 🔑
Copyfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
def auto_login(username, password, login_url):
# 브라우저 설정
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
try:
# 로그인 페이지로 이동
driver.get(login_url)
# 요소가 로드될 때까지 대기 (최대 10초)
wait = WebDriverWait(driver, 10)
# 사용자명 입력 필드 찾기 및 입력
username_field = wait.until(
EC.presence_of_element_located((By.NAME, "username"))
)
username_field.send_keys(username)
# 비밀번호 입력 필드 찾기 및 입력
password_field = driver.find_element(By.NAME, "password")
password_field.send_keys(password)
# 로그인 버튼 클릭
login_button = driver.find_element(By.XPATH, "//button[@type='submit']")
login_button.click()
# 로그인 성공 확인 (예: 대시보드 페이지 제목 확인)
wait.until(EC.title_contains("Dashboard"))
print("로그인 성공!")
return driver
except Exception as e:
print(f"로그인 실패: {e}")
driver.quit()
return None
# 사용 예시
# driver = auto_login("my_username", "my_password", "https://example.com/login")
대기(Wait) 전략 ⏰
웹 페이지가 로딩되는 시간을 고려해야 합니다:
1. 묵시적 대기 (Implicit Wait)
Copy# 요소를 찾을 때까지 최대 10초 대기
driver.implicitly_wait(10)
2. 명시적 대기 (Explicit Wait)
Copyfrom selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
# 요소가 클릭 가능할 때까지 대기
element = wait.until(EC.element_to_be_clickable((By.ID, "myButton")))
# 요소가 보일 때까지 대기
element = wait.until(EC.visibility_of_element_located((By.CLASS_NAME, "content")))
3. 고정 대기 (Sleep)
Copyimport time
# 3초 대기 (권장하지 않음)
time.sleep(3)
스크린샷 캡처하기 📸
Copy# 전체 페이지 스크린샷
driver.save_screenshot("screenshot.png")
# 특정 요소만 스크린샷
element = driver.find_element(By.ID, "myElement")
element.screenshot("element_screenshot.png")
고급 기능들 🚀
1. 파일 업로드
Copy# 파일 선택 입력 필드에 파일 경로 입력
file_input = driver.find_element(By.TYPE, "file")
file_input.send_keys("/path/to/your/file.pdf")
2. 드롭다운 메뉴 처리
Copyfrom selenium.webdriver.support.ui import Select
# Select 객체 생성
dropdown = Select(driver.find_element(By.ID, "mySelect"))
# 값으로 선택
dropdown.select_by_value("option1")
# 보이는 텍스트로 선택
dropdown.select_by_visible_text("옵션 1")
# 인덱스로 선택
dropdown.select_by_index(0)
3. 알림(Alert) 처리
Copyfrom selenium.webdriver.common.alert import Alert
# 알림 대기
alert = WebDriverWait(driver, 10).until(EC.alert_is_present())
# 알림 텍스트 읽기
alert_text = alert.text
print(alert_text)
# 알림 수락
alert.accept()
# 또는 알림 취소
# alert.dismiss()
4. 새 탭/창 처리
Copy# 현재 창 핸들 저장
original_window = driver.current_window_handle
# 새 탭 열기
driver.execute_script("window.open('');")
# 새 탭으로 전환
driver.switch_to.window(driver.window_handles[1])
# 새 페이지로 이동
driver.get("https://example.com")
# 원래 탭으로 돌아가기
driver.switch_to.window(original_window)
헤드리스 모드 사용하기 👻
화면에 브라우저를 띄우지 않고 백그라운드에서 실행:
Copyfrom selenium.webdriver.chrome.options import Options
# Chrome 옵션 설정
chrome_options = Options()
chrome_options.add_argument("--headless") # 헤드리스 모드
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# 헤드리스 브라우저 실행
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=chrome_options
)
성능 최적화 팁 ⚡
1. 불필요한 리소스 차단
Copychrome_options = Options()
chrome_options.add_argument("--disable-images") # 이미지 로딩 차단
chrome_options.add_argument("--disable-javascript") # JavaScript 차단
chrome_options.add_experimental_option("prefs", {
"profile.managed_default_content_settings.images": 2
})
2. 페이지 로드 전략 설정
Copychrome_options = Options()
chrome_options.add_argument("--page-load-strategy=eager") # DOM 로드 완료 시 즉시 반환
3. 브라우저 재사용
Copy# 세션 단위로 브라우저 재사용
class WebDriver:
def __init__(self):
self.driver = None
def get_driver(self):
if self.driver is None:
self.driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install())
)
return self.driver
def quit(self):
if self.driver:
self.driver.quit()
self.driver = None
에러 처리와 디버깅 🐛
1. 일반적인 예외 처리
Copyfrom selenium.common.exceptions import (
NoSuchElementException,
TimeoutException,
ElementClickInterceptedException
)
try:
element = driver.find_element(By.ID, "myElement")
element.click()
except NoSuchElementException:
print("요소를 찾을 수 없습니다.")
except TimeoutException:
print("시간이 초과되었습니다.")
except ElementClickInterceptedException:
print("요소를 클릭할 수 없습니다.")
except Exception as e:
print(f"예상치 못한 오류: {e}")
2. 디버깅 도구
Copy# 현재 URL 확인
print(f"현재 URL: {driver.current_url}")
# 페이지 소스 확인
print(driver.page_source)
# 요소 정보 확인
element = driver.find_element(By.ID, "myElement")
print(f"요소 텍스트: {element.text}")
print(f"요소 속성: {element.get_attribute('class')}")
print(f"요소 위치: {element.location}")
print(f"요소 크기: {element.size}")
모범 사례 (Best Practices) 📋
1. Page Object Model 패턴
Copyclass LoginPage:
def __init__(self, driver):
self.driver = driver
self.username_field = (By.NAME, "username")
self.password_field = (By.NAME, "password")
self.login_button = (By.XPATH, "//button[@type='submit']")
def enter_username(self, username):
self.driver.find_element(*self.username_field).send_keys(username)
def enter_password(self, password):
self.driver.find_element(*self.password_field).send_keys(password)
def click_login(self):
self.driver.find_element(*self.login_button).click()
def login(self, username, password):
self.enter_username(username)
self.enter_password(password)
self.click_login()
2. 설정 파일 사용
Copy# config.py
class Config:
IMPLICIT_WAIT = 10
EXPLICIT_WAIT = 10
HEADLESS = False
BROWSER = "chrome"
BASE_URL = "https://example.com"
# 사용
from config import Config
driver.implicitly_wait(Config.IMPLICIT_WAIT)
driver.get(Config.BASE_URL)
3. 로깅 설정
Copyimport logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
filename='selenium.log'
)
logger = logging.getLogger(__name__)
try:
driver.get("https://example.com")
logger.info("페이지 로드 성공")
except Exception as e:
logger.error(f"페이지 로드 실패: {e}")
실제 프로젝트 예제: 뉴스 스크래핑 📰
Copyimport csv
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
def scrape_news():
# 브라우저 설정
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options
)
news_data = []
try:
# 뉴스 사이트로 이동
driver.get("https://news.example.com")
# 뉴스 기사 목록 대기
wait = WebDriverWait(driver, 10)
articles = wait.until(
EC.presence_of_all_elements_located((By.CLASS_NAME, "news-article"))
)
for article in articles[:10]: # 상위 10개 기사만
try:
title = article.find_element(By.CLASS_NAME, "title").text
summary = article.find_element(By.CLASS_NAME, "summary").text
link = article.find_element(By.TAG_NAME, "a").get_attribute("href")
news_data.append({
"title": title,
"summary": summary,
"link": link
})
except Exception as e:
print(f"기사 처리 중 오류: {e}")
continue
# CSV 파일로 저장
with open("news_data.csv", "w", newline="", encoding="utf-8") as csvfile:
fieldnames = ["title", "summary", "link"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(news_data)
print(f"{len(news_data)}개의 뉴스 기사를 수집했습니다.")
finally:
driver.quit()
# 실행
scrape_news()
자주 발생하는 문제와 해결법 🔧
1. "Element not found" 오류
Copy# 해결법: 명시적 대기 사용
wait = WebDriverWait(driver, 10)
element = wait.until(EC.presence_of_element_located((By.ID, "myElement")))
2. "Element not clickable" 오류
Copy# 해결법: 요소가 클릭 가능할 때까지 대기
wait = WebDriverWait(driver, 10)
element = wait.until(EC.element_to_be_clickable((By.ID, "myButton")))
element.click()
3. 팝업 광고 처리
Copy# 해결법: 팝업 차단 옵션 추가
chrome_options = Options()
chrome_options.add_argument("--disable-popup-blocking")
chrome_options.add_argument("--disable-notifications")
마무리 🎯
셀레니움은 웹 자동화의 강력한 도구입니다. 처음에는 복잡해 보일 수 있지만, 기본 개념을 이해하고 꾸준히 연습하면 다양한 웹 작업을 자동화할 수 있습니다.
핵심 포인트 요약
- 올바른 대기 전략 사용 - 묵시적/명시적 대기 조합
- 예외 처리 필수 - NoSuchElementException 등
- Page Object Model 패턴으로 코드 구조화
- 헤드리스 모드로 성능 최적화
- 리소스 정리 - 반드시
driver.quit()호출
다음 단계
- pytest와 결합한 자동화 테스트
- Selenium Grid를 이용한 병렬 테스트
- Docker와 함께 사용하는 컨테이너 기반 테스트
- CI/CD 파이프라인에 통합
웹 자동화의 세계는 무궁무진합니다. 셀레니움으로 반복 작업을 자동화하고, 더 창의적인 일에 시간을 투자해보세요! 🚀
참고 자료:

AI를 꿈꾸는 BackEnd개발자