트래픽 분산 환경 구성 전에 인덱스 및 캐시부터 적용할 것!
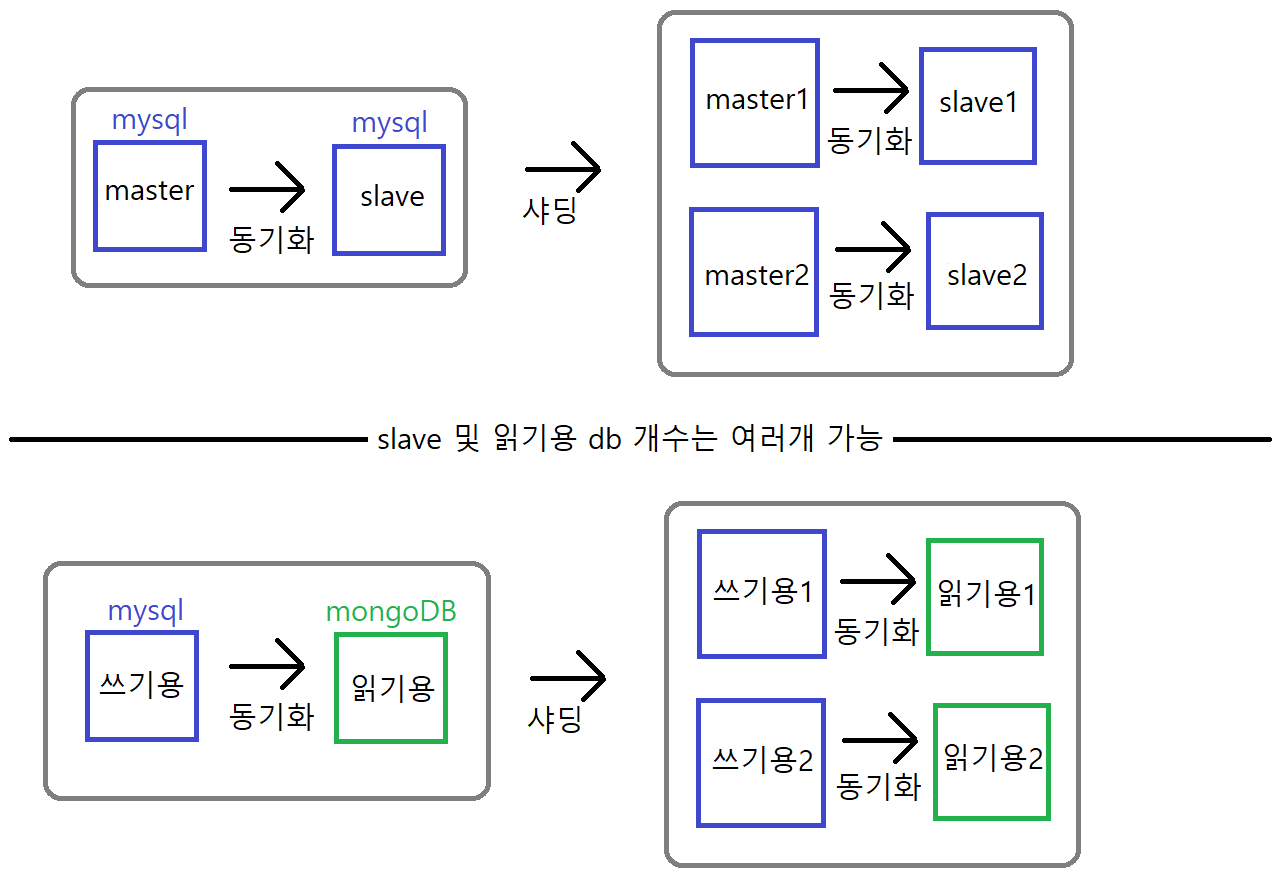
트래픽 분산을 위해 db가 최소 2개는 필요하다.
ex) 쓰기용 db & 읽기용 db
db 만드는 건 쉬운데 그 후가 어렵다.
db 만든 후 다음과 같은 일을 어떻게 할지 정해야한다.
- db 간 데이터 동기화
- 분산을 위해 테이블 분리
- 분리한 테이블에 어떤 방식으로 트래픽을 나눌지 (로드 밸런싱)
CQRS
CQRS는 클래스를 쓰기용, 읽기용으로 분리하라는 '코딩' 가이드
다만 클래스가 분리 되면 db를 분리해도 헷갈리지 않는다.
→ db 분리를 시도해볼만 함
CQRS 적용 안 해도 DB 분리 가능하지만
@Transactional을 메서드마다 달아줘야 해서 불편
데이터 동기화
db 복제
db 복제는 'db 레벨에서' 동기화하는 db가 제공하는 기능
ex) mysql의 Replicatoin
mysql에서는 원본을 Master라 부르고, 복사본을 Slave라 부름
복제 방식은 바이너리 로그를 통해 실시간으로 복제
스프링 & mysql Replicatoin 설정법
https://dgjinsu.tistory.com/51
p6spy 쓰는 중이면 yml 설정 필요
https://velog.io/@uhan2/%EC%82%AC%EB%82%B4-%EC%84%9C%EB%B9%84%EC%8A%A4-%EC%9E%A5%EC%95%A0-%ED%95%B4%EA%B2%B0-%EC%9D%BC%EB%8C%80%EA%B8%B0
보통 db 복제는 이중화가 아니라, 데이터 동기화 '기능'을 얘기한다.
이벤트 또는 배치
'어플리케이션 레벨'에서 동기화 (개발자가 코드로 구현)
쓰기용, 읽기용 db 소포트웨어가 서로 다를 때 쓰는 방법이다.
ex) 쓰기용은 mysql, 읽기용은 mongoDB 쓰는 경우
ex) 읽기용은 읽기에 최적화된 mongoDB, ElasticSearch를 쓰기도 함
이벤트 (실시간)
쓰기용 db가 변경됐다는 실시간 이벤트 발행 → 이벤트 리스너가 읽기용 db에 반영
ps) 모놀리스는 도메인 다 있으니까 코드 호출로 해도 됨.
배치 (백그라운드 비실시간)
스프링 스케줄러로 1~5분 간격으로 동기화하기
다만 동기화가 늦기에 비추
https://sihyung92.oopy.io/architecture/woowa-msa-travel
가격 비교 (2025-11-05)
| db.t4g.medium | vCPU | RAM(GB) | 월 가격(₩) |
|---|---|---|---|
| aws rds (mysql) | 2 | 4 | ₩52,000 |
| aws documentDB | 2 | 4 | ₩120,000 |
rds (master+slave) = \104,000
rds + docuementDB = \172,000
mongoDB가 읽기 성능이 좋아서 비싼건 알지만
rds (master+slave+slave) 구조가 \156,000이라 더 싸고 효율도 좋을텐데
굳이 mongoDB 써야하나 싶은데,
mongoDB는 조인을 대채할 수있는 장점이 있다.
또한 row 수가 많을때 rdb보다 성능이 좋다는 논문이 있다.
참고로 aws documentDB는 저게 제일 싼 인스턴스
테이블 분리
파티셔닝은 특정 시기 또는 종류 데이터를 찾을 때 빠르다. ex) 로그
특정 데이터가 아니라 균등하게 조회가 일어나면, 복제로 Slave를 여러개 만드는 게 낫다.
https://www.youtube.com/watch?v=VAhZa30j8hA
파티셔닝 종류는 수직과 수평이있다
수평 파티셔닝 (row)
ex) row 수를 10→5개로 쪼개서 숨겨진 테이블까지 총 2개 사용
- mysql이 지원하는 기능
- 보이는 테이블은 하나인데 물리적으로 나뉘어져 있다.
실제로 테이블 만들고 확인해보시면 이해되실 겁니다!
CREATE TABLE orders (
id BIGINT NOT NULL AUTO_INCREMENT,
order_date DATE NOT NULL,
customer_name VARCHAR(50),
amount DECIMAL(10, 2),
PRIMARY KEY (id, order_date)
)
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
INSERT INTO orders (order_date, customer_name, amount) VALUES
('2023-03-14', 'Alice', 100.00),
('2023-11-01', 'Bob', 150.50),
('2024-02-25', 'Charlie', 200.00),
('2024-07-10', 'David', 350.75),
('2025-01-01', 'Eve', 500.00),
('2025-09-15', 'Frank', 120.00),
('2026-01-05', 'Grace', 180.00);
SELECT * FROM orders;
EXPLAIN SELECT * FROM orders WHERE order_date = '2024-07-10';수직 파티셔닝 (컬럼)
ex) 컬럼 수를 4→2개로 쪼개서 보이는 테이블을 2개 사용
컬럼이 쪼개지므로 테이블 구조가 바뀜
- mysql이 지원하지 않음
- 직접 보이는 테이블을 여러개 만들어야 함
- 쓰는 사례를 못 찾음
샤딩 (row & db)
ex) row 수를 10→5개로 쪼개서 테이블을 2개 사용. 다만 '다른 db에' 테이블 저장
수평 파티셔닝은 '하나의 db'에서 테이블 분리하는 것
목적
ps) 조회 트래픽은 읽기용 db를 scale out하여 해결
분산 방법
1) Hash Based Sharding (aka. key Based Sharding)
ps) 균등하게 트래픽이 분산되서 얘를 주로 사용
2) Range Based Sharding
PK의 범위를 기준으로 어느 db로 보낼지 결정
3) Directory Based Sharding
특정 샤드 키가 어느 db로 갈지 별도 테이블에 정해둔다.
