Generative pertaining model trained by Unlabeled data
fine-tuning with labeled data로 간추릴 수 있을 것 같다.
Transformer에 대한 선행 공부를 하면 좋을 듯하다.
Abstract

대량의 unlabeled data가 존재하지만, labeled data의 수가 부족해 훈련된 모델이 정삭적으로 작동하는데 어려움이 존재했다.
본 논문은 unlabeled data에서 generative pre-training 시킨 language model으로부터,
각 특정 task에 맞게 fine-tuning 시키는 방식을 소개한다.
모델 구조의 최소한의 변화를 줌과 동시에 테스크에 맞게 인풋을 transformation시켜 효과적인 transfer를 할 수 있다고 한다.
자세한 내용은 밑에서 소개하겠다.
Introduction
기존 대부분의 딥러닝 방법은 labeled data를 필요로 한다.
하지만 아래와 같은 이유로, unlabeled data 학습이 필요하다.
Raw text(unlabeled corpus)에서 효과적으로 학습하는 것은 자연어 모델의 supervised learning에 대한 의존을 완화시키는데 중요한 역할을 한다.
Unlabeled data를 사용하는 것이 데이터 라벨링을 하는 작업보다 시간과 비용을 아낄 수 있다.
더 나아가, unlabeled data로 좋은 representation을 학습함을로써,
해당 테스크에 labeled 데이터가 주어졌을 때, 더 좋은 성능을 기대할 수 있다.
Pertained word embedding의 사용이 NLP task에서 좋은 성능을 보이는 것이 이 증거라고 할 수 있겠다.
하지만, Unlabeled text에서 Word-level 정보 수준을 넘어서 활용하는 것은 두가지 이유에서 어렵다고 한다.
1. 어떤 목적함수를 사용할 지, 즉 가장 효과적인 최적화 target 지정에 대해 어려움이 있다.
2. 목적 테스크에 대해 어떤 방식으로 finetuning 할 지에 대한 정답이 없다.본 논문에서는 unsupervised pre-training과 supervised fine-tuning의 조합인, semi-supervised 접근법을 제공한다.
목표는 다양한 종류의 테스크를 적은 adaptation으로 transfer를 할 수 있는, 보편적인 표현을 배우는 것에 있다고 한다.
과정은 다음과 같다.
- 레이블이 없는 데이터에서 언어 모델링을 사용해, 신경망의 초기 파라미터를 학습한다.
- 이후 target task에 대해 위에서 학습된 파라미터를 적용 시킨다.
모델 아케텍쳐로는, 기계 번역, 문서 생성, 구문 분석 등과 같은 다양한 테스크에서 강력한 성능을 수행하는 Transformer를 사용한다.
Long-term dependencies를 다룰 수 있는, 더 구조적으로 튼튼한 메모리를 제공하며 순환 신경망보다 전이학습에 더 좋기에 선택했다고 한다.
특정 task별로, 구조화된 text input을 단일 연속 토큰 시퀀스로 처리하는 Traversal-style에서 착안한 input adaptation을 사용한다.
Natural language inference, question answering, semantic similarity, text classification 네가지의 task에서 평가를 했다.
Related Work
Semi-supervised learning for NLP
기존 연구에서는,
1. unlabeled data를 단어 수준, 혹은 구문 수준의 통계치를 계산해 지도 학습 모델에 feature로써 사용했다.
2. 레이블이 없는 corpus에서 훈련된 단어 임베딩의 이점을 입증했다.
하지만 기존 연구들은 단어 수준의 정보를 transfer하는데 중점이 되어 왔다.
그래도 최근에는 레이블이 없는 데이터로 구문, 문장 수준의 임베딩을 시도해 왔다고 한다.
Unsupervised pre-training
GPT에서 비지도 학습은 지도학습을 위한 좋은 초기 파라미터 값을 찾는 것이다.
Unsupervised pre-training에 대한 초기 연구는 이미지 분류나 회귀 테스크에서 사용되어 왔다.
이후에는 pre-training이 규제 기법으로 작용하여 깊은 신경망에서 더 좋은 일반화를 가능하게 했다.
기존 연구 중, LSTM을 사용해 language model을 만들고 타겟 테스크에 맞게 지도 학습을 시도한 연구가 본 논문의 작업과 유사하다.
하지만 앞서 말했듯 순환 신경망은 long term dependencies의 문제가 존재한다는 한계점이 있다.
Auxiliary training objectives
비지도 학습을 보조적 목적으로 사용하는 것도 준지도 학습의 대안이 될 수 있다.
본 논문도 auxiliary objective를 사용하긴 하지만, 본 논문의 비지도 사전 학습은 target task와 연관된 언어적 측면을 학습할 수 있다는 점에서 차이가 있다.
Framework
학습은 위에서 언급했듯이,
레이블이 없는 데이터 corpus에서 비지도 사전학습을 진행하고, 이후 target task에 맞게 fine-tuning을 시키는 방식이다.
Unsupervised pre-training
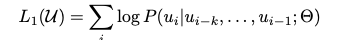
로 구성된 신경망 네트워크를 사용해, 의 context window size를 가진, 레이블이 없는 corpus 를 사용해 probability 를 계산한다.

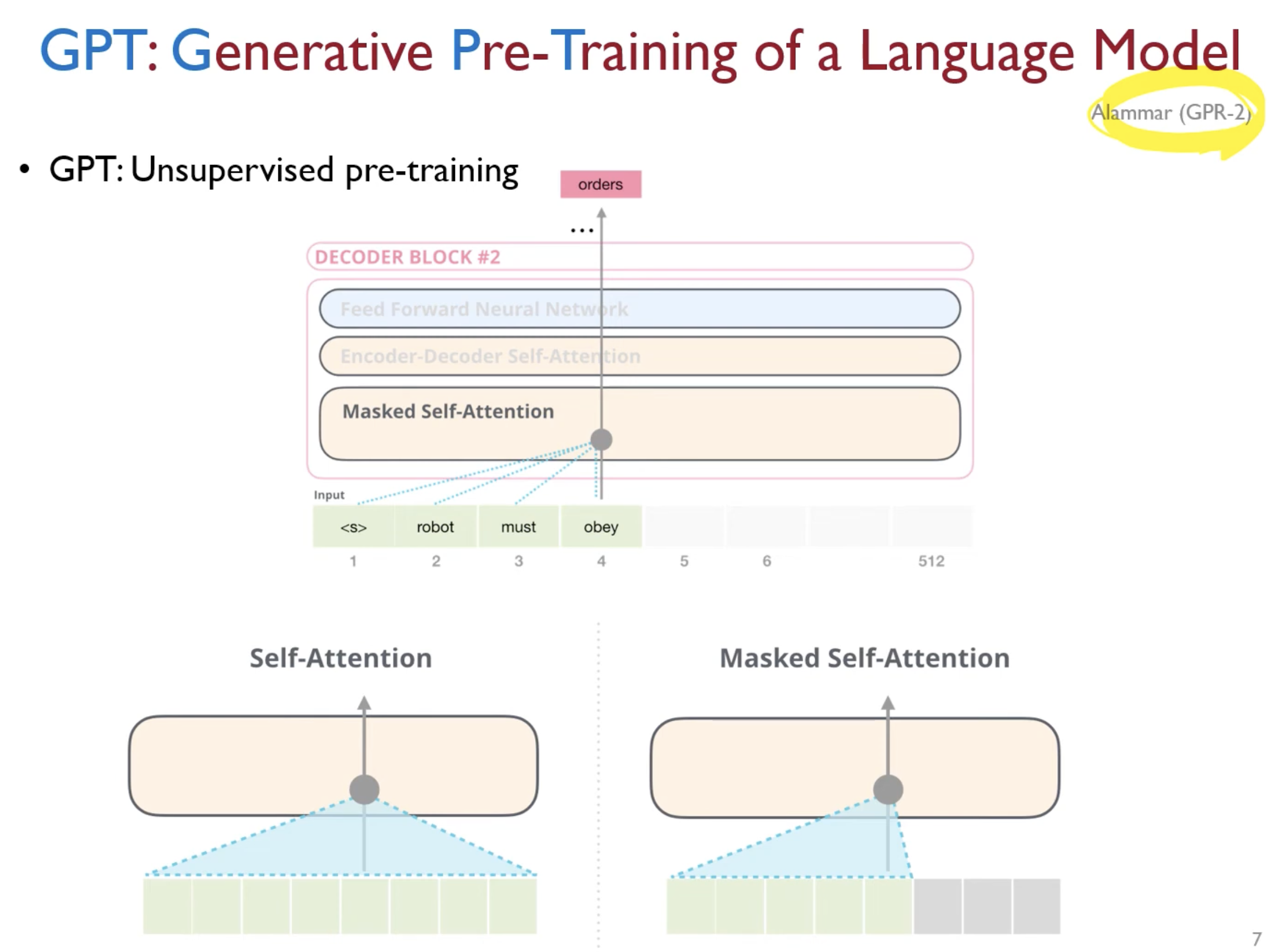
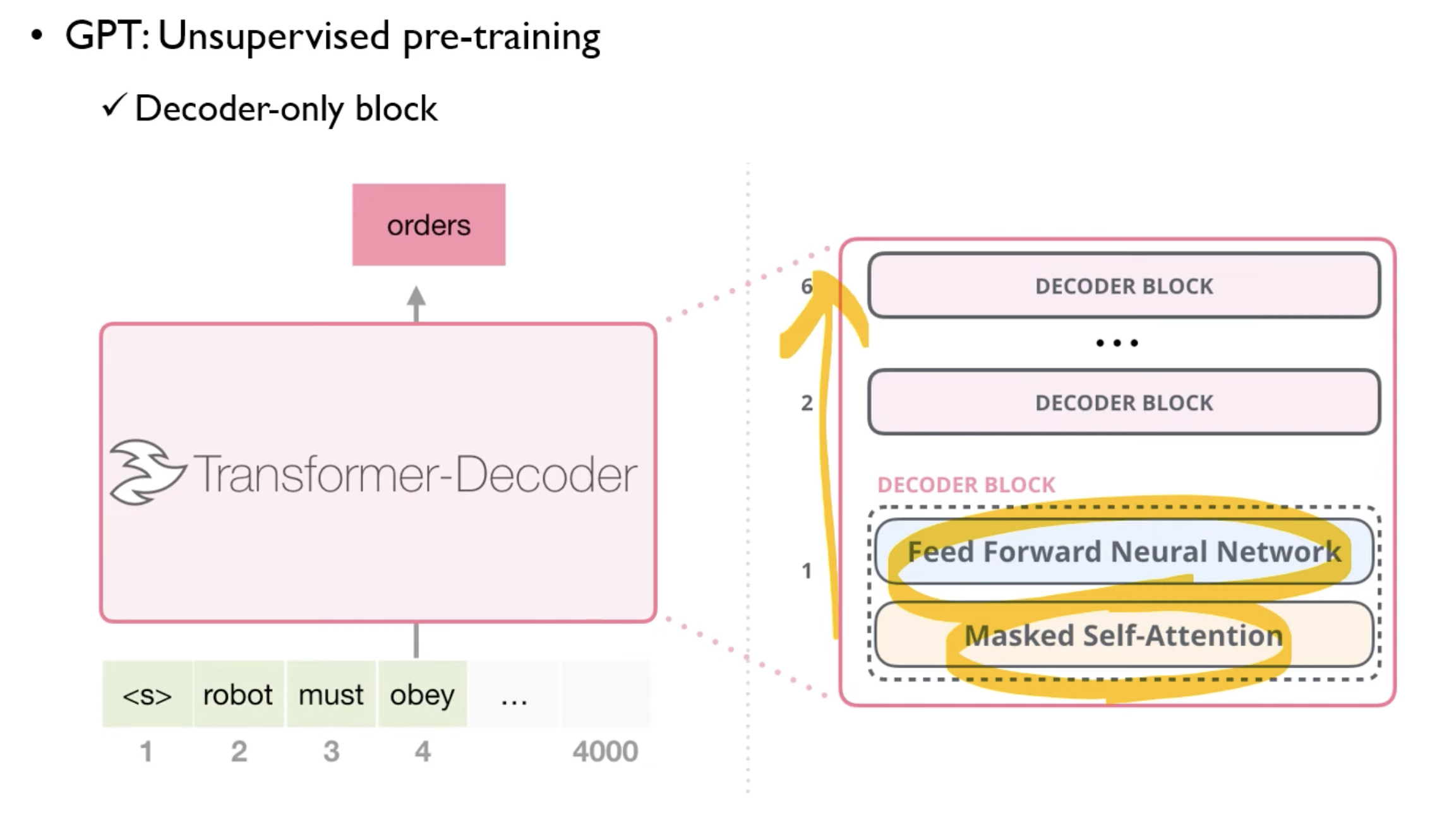
Multi-layer Transformer decoder를 사용한다.
Input context tokens에 Multi-headed self-attention을 적용하고, 이후 position wise feedward layer를 통과해 target token에 해당하는 output distribution을 얻는다.
기존 transformer의 디코더 구조에서 encoder-decoder attention이 없는 구조와 유사하다.
Masked self attention을 그대로 사용했다.
위 식에서 는 unlabeled context vector of tokens에 토큰 임베딩을 적용해 position 임베딩과 sum을 한 값.
는 transformer decoder의 인풋으로 들어간다.
은 이전 hidden state의 값을 transformer_block을 통과한 값.
Hidden state의 값과 토큰 임베딩과의 선형 연산 후 softmax를 통과한 값이, 최종적으로 context vector of token 에 대한 probability라고 할 수 있겠다.
Supervised fine-tuning
위에서 를 구하며, 파라미터 를 최적화 한다. 이 파라미터를 이후 target task의 지도 학습에 사용한다.

개의 단어로 이루어진 시퀀스와 그에 대한 정답이 주어져 있을 때에 대한 확률값은 번째에 해당하는 단어의 hidden state block에 linear layer를 한번 씌우고 소프트맥스를 통과한 값이다.
즉 는 주어진 토큰의 시퀀스에 따라서 정답이 무엇인지에 대한 확률값을 최대화 하는 목적 함수.

Pre-trained된 language modeling을 fine-tuning 시 추가적인 목적(auxiliary objective)으로 사용했을 때 지도학습에서의 일반화 성능 향상을 얻을 수 있었다고 한다. 또한 수렴(최적화)의 가속화 효과 또한 얻었다고 한다.
L1은 unlabeled data에 대한 language model의 목적함수 (pre-training) L1(U)
c는 supervised learning에 대한 corpus
fine-tuning 시에 필요한 추가적인 파라미터로는 Wy와 delimiter token에 대한 임베딩 뿐이다.
Task-specific input transformations
Pre-trained 모델이 text의 연속적인 시퀀스로 학습이 되었고,
question answering, textual entailment 같은 특정 테스크는 문장 쌍, triplet 같은 정해진 구조의 인풋이 필요하다.
즉, task에 맞게 input을 수정하는 작업이 필요하다.
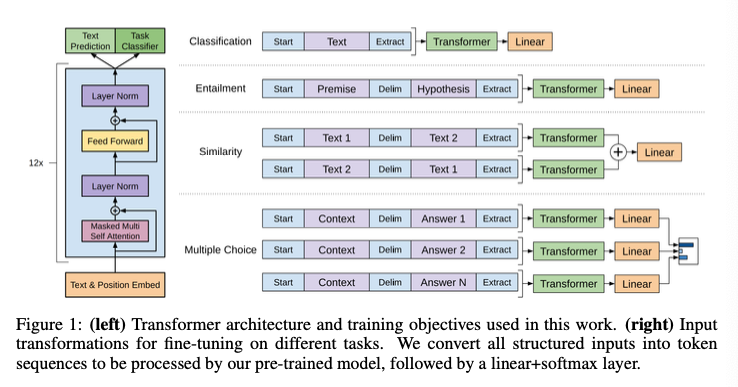
정해진 구조의 인풋을 사전 훈련된 모델도 접근할 수 있는 순서화된 시퀀스(ordered sequence)로 변환하는 Traversal-style 접근법을 사용했다.
이 방식을 사용함으로써 input transformation은 모델 구조에 extensive한 변화를 주지 않을 수 있었다.
Figure 1이 이 traversal-style을 시각화 한 것.
Textual entailment
Premise 와 Hypothesis 토큰 시퀀스와, 사이에 delimiter token을 concatenate한 input을 transformer에 투입한다.
Similarity
Text1, Text2 token과 사이에 delimiter token을 concatenate한 두가지 인풋을 각각 독립적으로 처리해 두 시퀀스에 대해 concat한 후 linear layer를 통과시킨다.
Entailment task와 굳이 다른 인풋 구조를 사용한 이유는, 실험 과정에서 이러한 구조가 더 이득을 취할 수 있기에 이와 같이 한 것으로 보인다.
Question Answering and Commonsense Reasoning
Context document 와 question , 그리고 possible answer의 세트 토큰과 delimiter token으로 구성된 인풋을 독립적으로 transformer와 linear를 통과한 후, softmax를 취해 확률값을 구한다.
Experiments
Unsupervised pre-training
BookCorpus dataset을 사용했다.
Pre-trained된 language model은 18.4의 낮은 perplexity를 얻을 수 있었다.
perplexity는 언어 모델의 분기계수로, 한가지를 골라야 하는 task에서 선택지의 갯수를 뜻한다.
즉 perplexity가 낮다는 것은, 복잡도가 낮은, 좋은 성능이라는 뜻으로 보면 되겠다.
Supervised fine-tuning
앞서 말한 네가지의 task natural language inference, question answering, semantic similarity, text classification에 대해 실험을 진행했다.
Figure1에서 소개한대로, input transformation을 진행했다.
각 테스크에서 대부분 높은 성능을 기록했다.
Analysis
Impact of number of layers transferred, Zero-shot Behaviors
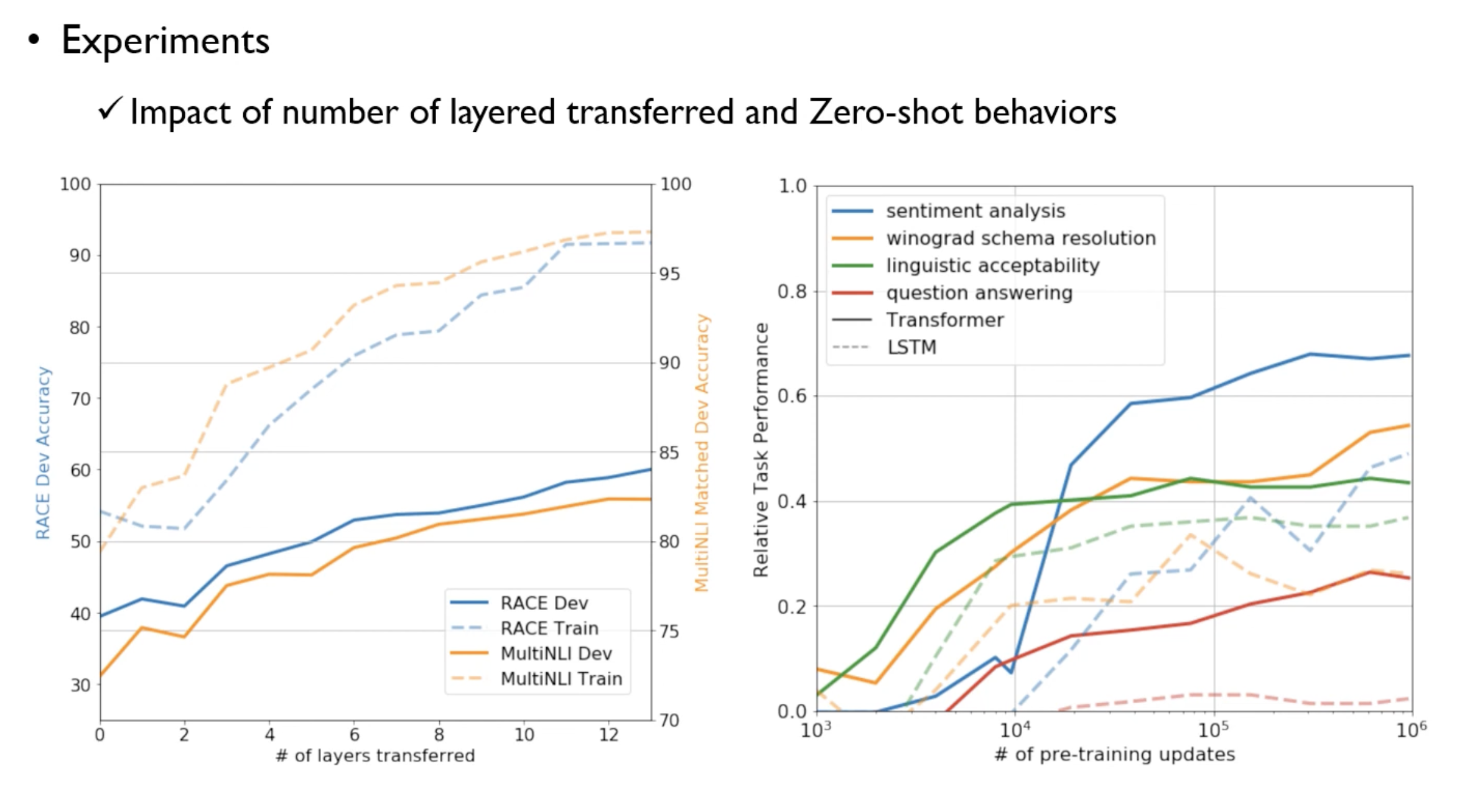
왼쪽은 디코딩블락을 몇개를 쌓아야 하는지에 대한 실험이다.
unsupervised language model(점선)과 추가적인 fine tuned model(실선)을 보여준다.
layer를 쌓을 수록 성능이 증가했으며, fine-tuning된 모델의 성능이 더 높았다.
오른쪽은 zero-shot behaviors에서 pre-training을 더 할 수록 성능이 좋아짐을 보여주는 그래프이다.
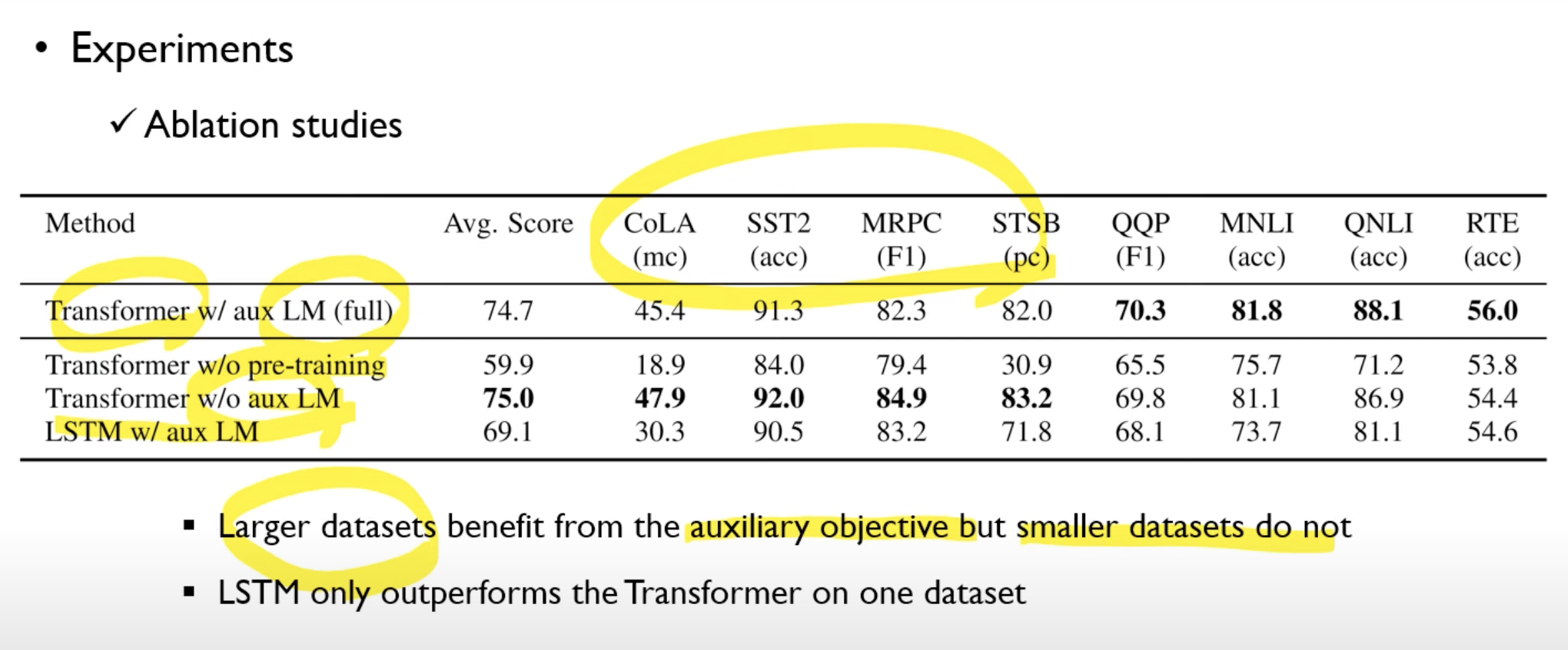
Ablation studies
아까 손실함수에서, 큰 데이터셋을 사용하는 경우에는 language model의 손실함수도 사용하는 것이 좋지만, 적은 데이터셋에서는 없는 것이 좋다고 한다.
Inference :
https://ffighting.net/deep-learning-paper-review/language-model/gpt-1/
DSBA 강필성 교수님 유튜브 https://www.youtube.com/watch?v=o_Wl29aW5XM
