T5 : Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
PaperReview
Abstract
NLP 분야에서, 모델이 하위 작업에서 Fine-tunning 되기 전에, Data-rich Task에 대해 먼저 Pre-train되는 Transfer Learning은 영향력 있는 기술로 부상했다.
본 논문은 모든 텍스트 기반 언어 문제를 Text to Text로 취급하는 통합 프레임워크를 도입하여 다양한 실험을 통해 NLP를 위한 전이 학습 기술의 환경을 탐구한다.
아래와 같은 요인들을 실험.
Comparing pre-training objectives,
architectures,
unlabeled data sets,
transfer approaches,
and other factors
objective라는 단어가 자주 등장하는데, 목적이라고 읽기보단 방법론으로 생각하며 논문을 읽었다.
Introduction
자연어 처리(NLP) 작업을 수행하기 위해 모델을 훈련하려면, 모델이 다운스트림 테스크에서 적합한 방식으로 텍스트를 처리할 수 있어야 한다.
이는 모델이 텍스트를 "이해"할 수 있도록 하는 범용적인 지식을 개발하는 것으로 볼 수 있다.
본 논문의 기본 아이디어는 모든 자연어 처리 문제를 text to text 문제로 처리했다. 즉, 텍스트를 입력으로 취하고 새로운 텍스트를 출력으로 생성하는 것.
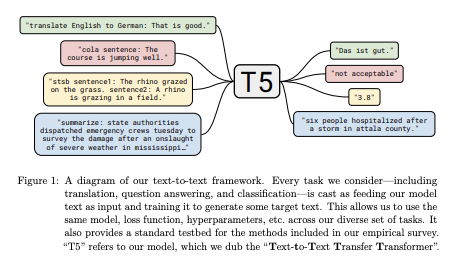
저자들의 목표는 새로운 방법론을 제안하는 것이 아니라 해당 task가 어디에 있는지(현 기술력의 좌표)에 대한 포괄적인 관점을 제공하는 것임.
Setup & Experiments
Text to Text
보통 generation task에서 사용하는 방식인데, T5에서는 generation뿐만 아니라 classification, regression 문제도 Text-to-Text로 풀고자 함.
조건을 지정하고 출력 텍스트를 생성하는 형식.
“translate English to German: That is good.”
and would be trained to output “Das ist gut.”
하나의 접근 방식을 사용함으로써 다양한 다운스트림 테스크에 대해서도 동일한 모델과 방법론, 학습 절차 등을 적용할 수 있게 되기에 비교가 수월하다.
인풋과 아웃풋의 포멧을 통일해서, 평가와 실험을 수월하게 했다고 보면 될듯하다.
Model : Transformer Encoder & Decoder
Transformer의 인코더 디코더 구조를 사용했다.
- 단순화된 레이어 정규화
Layer Norm시 사용되는 추가적인 bias를 사용하지 않고 rescale만 진행
- Relative position embedding 사용
효율성을 위해 모델의 모든 레이어에서 position embedding 파라미터를 공유.
상대적인 포지션 임베딩은 키와 쿼리의 오프셋, 즉 거리에 따라서 임베딩이 달라짐.
Dataset : C4

Colossal Clean Crawled Corpus라는 의미로, 이전에 GPT-3의 학습에 사용되었던 Common Crawl에 몇가지 cleaning 기법들을 적용해서 만든 데이터셋.
저자들의 경험적 규칙에 따라 웹에서 크롤링한 데이터를 필터링해서 Unlabed corpus 데이터 형태로 사용
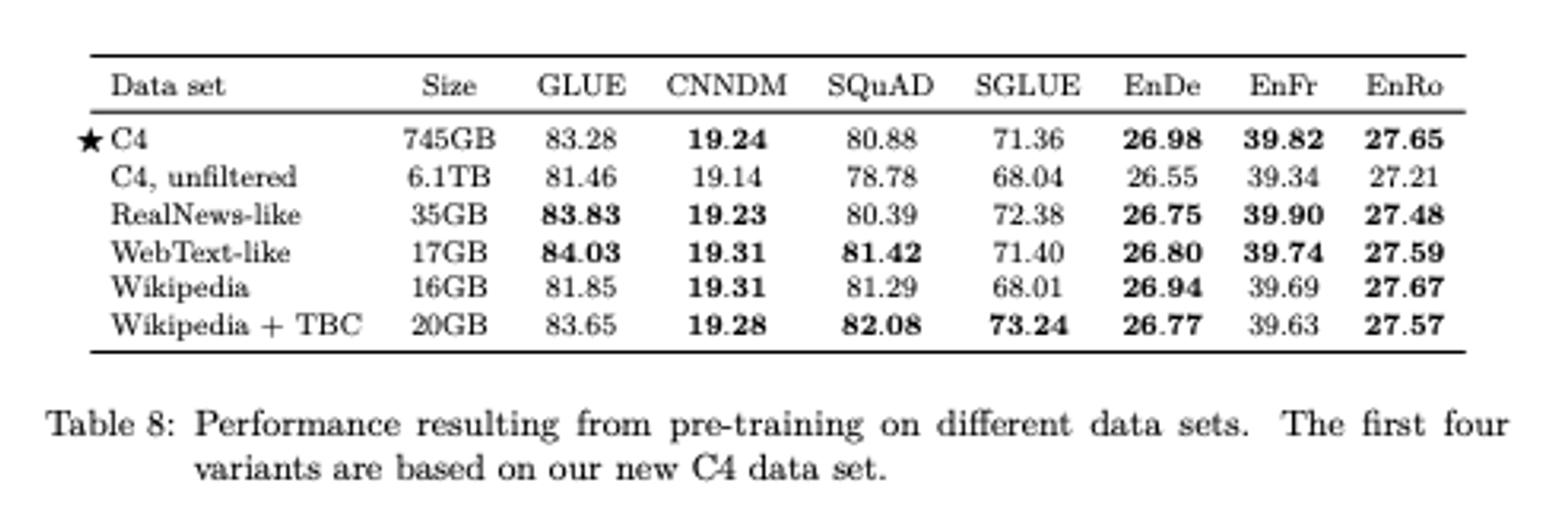
C4가 아닌 다른 데이터셋은 도메인에 특화되어 성능이 높게 나타나는 경우가 많다는 것을 발견함.
도메인에 국한되지 않은 pre training이 목표이므로, 일반화된 데이터셋을 사용해야 하기 때문에 이 부분은 개선이 필요한듯 하다.
Objective : Denoishing Span

BERT의 일부 토큰 마스크 방식인 Denoishig Object(마스킹된 언어 모델)에서 착안.
원래 BERT의 경우에서 일부 토큰을 랜덤한 비율로 뽑아 마스크 토큰으로 대체했는데, 본 모델에서 사용한 방식은 토큰 별이 아닌, span 별로 대체해서 사용.
Objective : Why Denoising Span ?
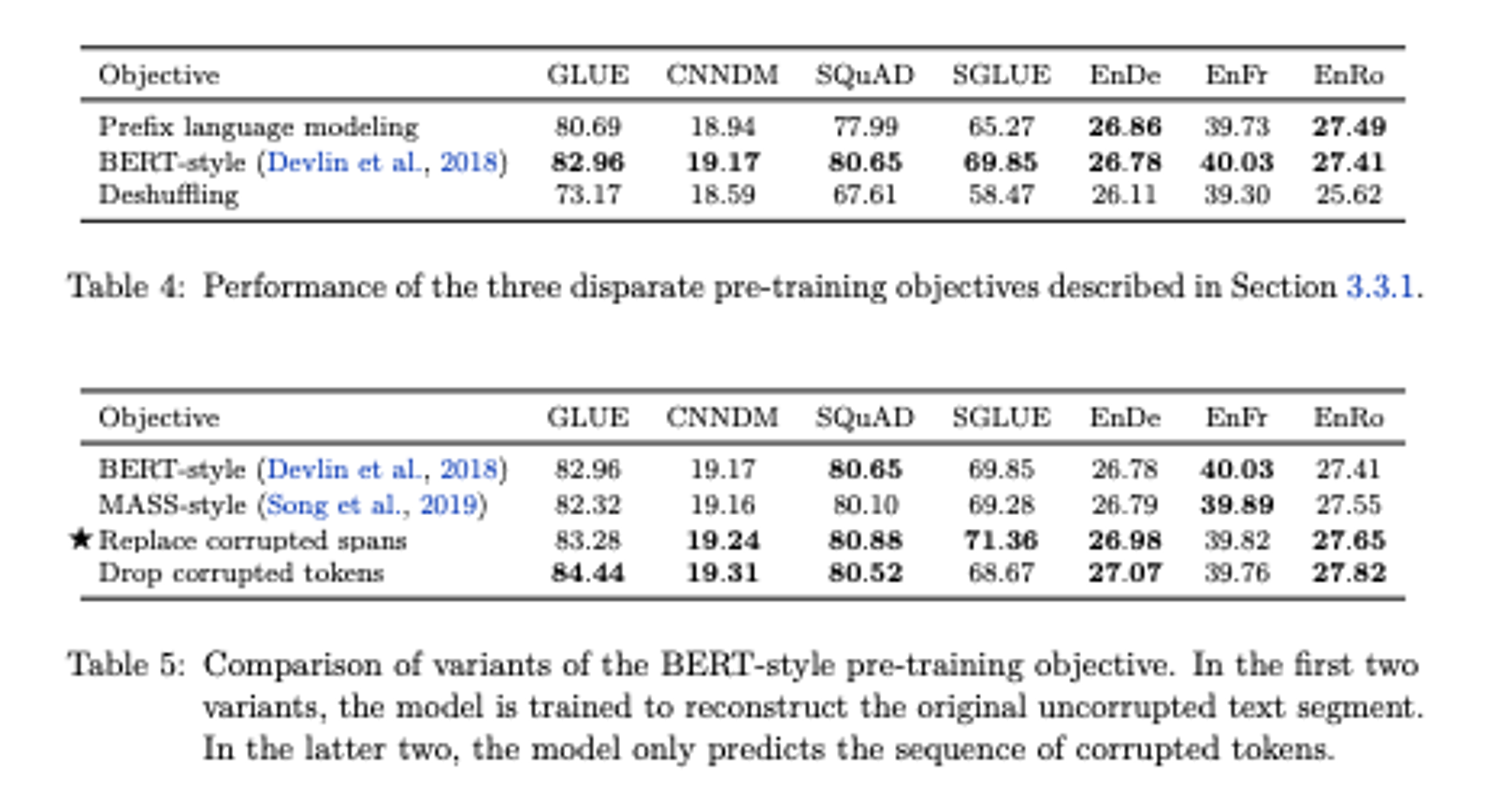
위의 표는 각 pre-training 방법에 대한 성능 비교를 나타낸 표.
Prefix language modeling은 GPT와 같은 standard language modeling 방식.
BERT-style은 BERT에서 사용되는 masked language modeling 방식.
마지막으로 Deshuffling 방식은 sequence를 입력으로 받아 순서를 shuffling한 후 원래 sequence를 target으로 해서 복구하는 방식.
세 종류의 pre-training objective에 대해서 실험한 결과 BERT-style의 masked language modeling 방식이 가장 좋은 성능을 나타냈다.
아래 표에서,
BERT-style은 original BERT에서 사용되었던 15%의 token을 masking하는 방식.
MASS-style은 MASS 논문에서 제안되었던 span내 token들을 masking하고 해당 token들을 예측하는 방식.
Replace corrupted spans는 T5에서 사용한 일정 span을 하나의 masking token으로 대체하는 방식.
Drop corrupted tokens는 input sequence의 tokens를 제거하고 다시 복원하는 방식.
그렇게 BERT-style의 pre-training objective가 가장 좋은 성능을 나타냈다는 것을 확인한 후 여러가지의 bert style denoising objectives에 대해서 서로 비교 실험을 진행했다.
실험 결과 전반적으로 가장 좋은 성능을 이끌어낸 방법은 세번째인 Replace corrupted spans였다.
And More…
모든 경우의 수 탐색이 어렵기 때문에 베이스라인을 합리적인 기준으로 선정하고,이후 실험들은 나머지 파이프라인을 고정하고, 비교하고자 하는 부분만 변경하며 실험 진행.
Downstream Task 선정 (벤치마크 선정), Multi-task learning, Scaling... 등의 다양한 실험을 진행했다.
여러 하위 집합에 대해 평가하기 위해 다양한 벤치마크 탐색 및 실험한 것인데, 이 중 멀티 태스크 러닝과 스케일링은 간단히 더 소개하겠다.
Multi-task Learning
한 번에 여러 task에 대해 모델을 pre-train하는 것.
목표는 일반적으로 한 번에 많은 작업을 동시에 수행할 수 있는 단일 모델을 train하는 것.
모델과 해당 매개변수의 대부분이 모든 layer에서 공유됨.
task 별로 데이터의 양이 중요한데, 난이도와 데이터의 양에 따라 모델이 task에 대한 데이터를 memorize할 수 있음.
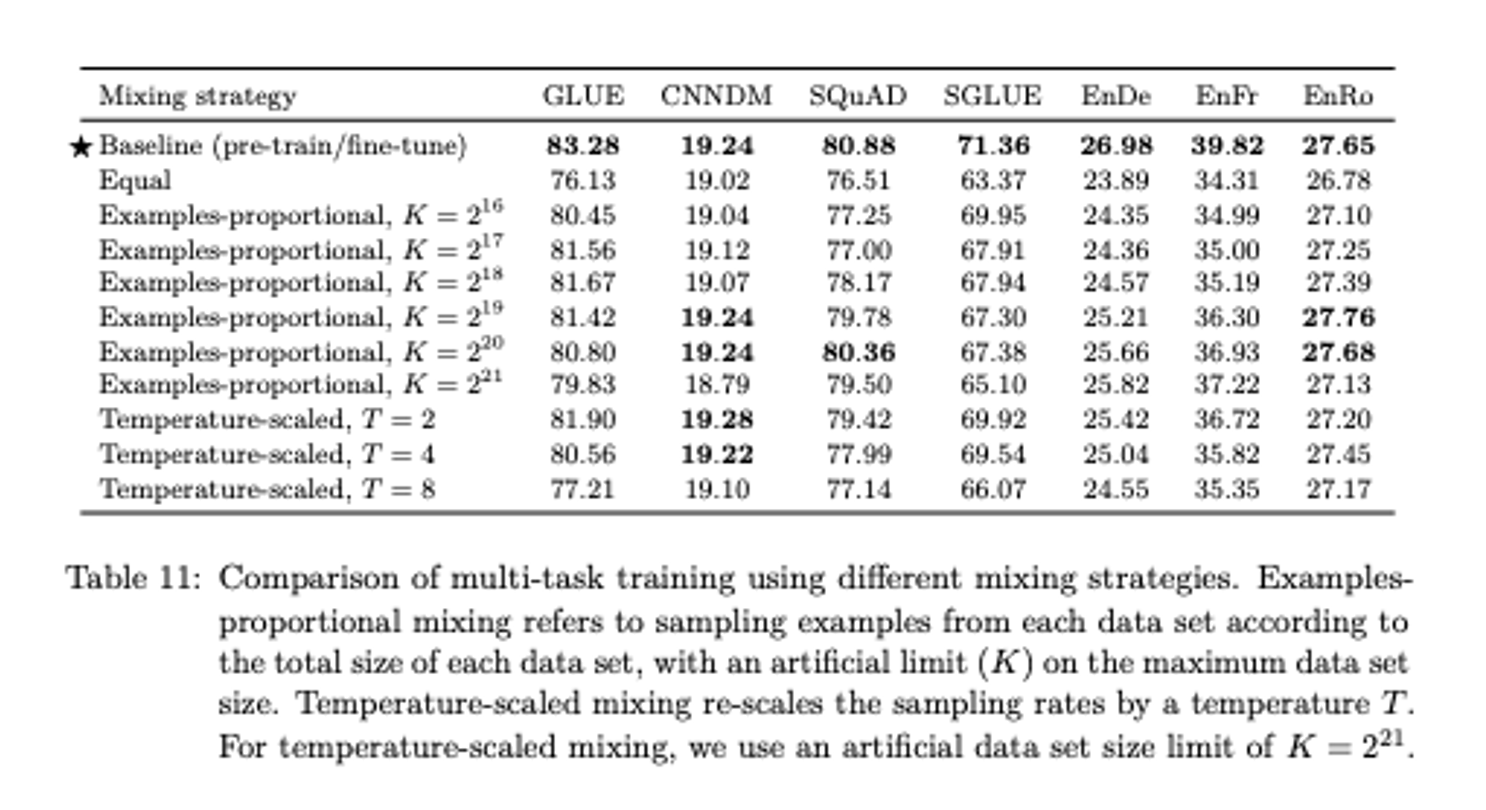
T,K를 통해 데이터의 양을 조절하면서 베이스라인 (기존의 방식인 하나의 unsupervised task에 대해 pre-train 하고 fine tunning을 진행하는 것)과 비교함.
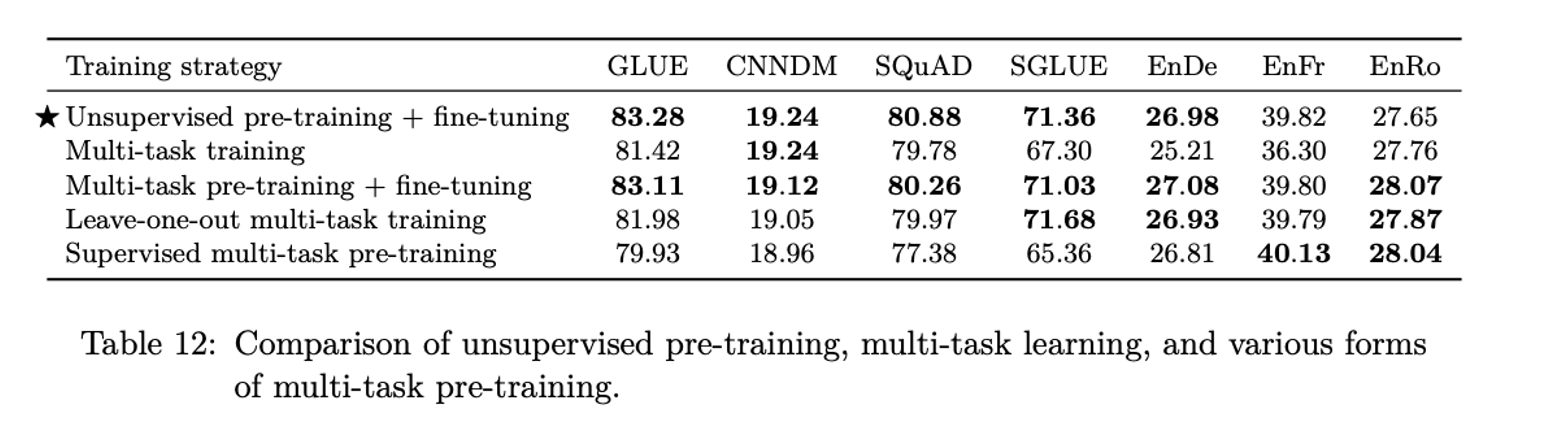
pretrain -> finetunning의 성능이 가장 좋았고,본 논문에서는 여러 task에 대해 multi task learning을 진행한 후 fine tunning하는 방식을 사용함.
Scaling
모델의 크기가 커지면 성능이 좋아지는 것은
이미 입증되었다.
크기가 올라가면 성능도 좋지만, down stream task마다 파인튜닝 하는 것 등에서 더 많은 비용이 발생할 수 있다.
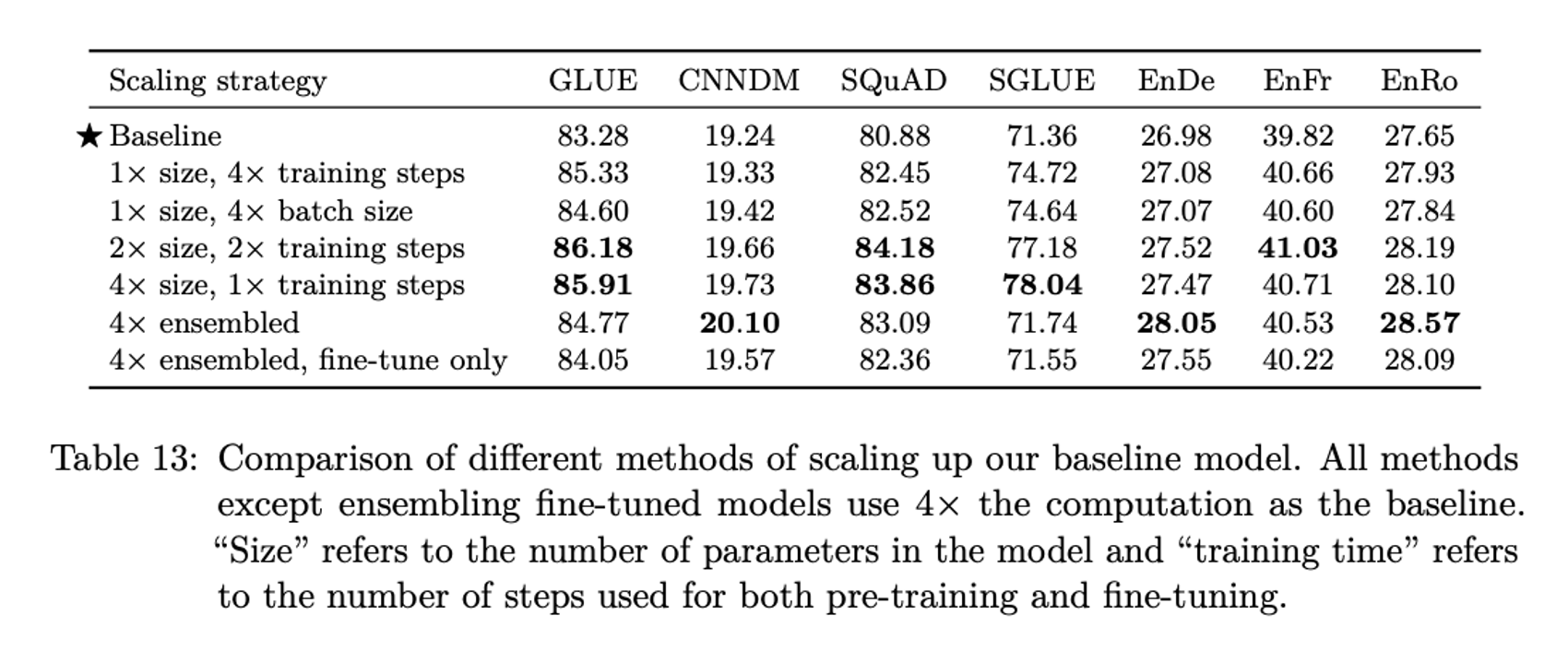
어떤 방식으로 업스케일링을 진행하는 것이 좋을지를 나타내는 표이다.
Putting it all Together
결국 저자들이 다양한 실험을 통해, 채택한 주 방법론들은 아래와 같다.
- span-corruption objective (Denoising Span)
span 평균길이 3, 비율을 15퍼센트
-
longer pre training, model
-
multi task pre training -> fine tunning
-
beam search
Final T5
-
Text-to-Text Framework
Text-to-Text Framework를 사용하게 되는 경우 하나의 모델로 loss, decoding방식 등의 변경없이 generation, classification, regression task 모두에서 좋은 성능을 이끌어낼 수 있다. -
Original Transformer Architecture
BERT나 GPT같은 모델처럼 Transformer의 encoder/decoder를 따로 떼어내서 사용하는 것이 아닌 original Transformer 구조를 그대로 사용하는 것이 text-to-text에서 더 좋은 성능을 나타낸다. 또한 인코더 디코더를 사용함으로써 파라미터는 많아지지만 연산량은 그대로라는 특징. -
Denoising Span Objective Pre-training시 사용하는 objective중에서는 BERT 계열에서 사용하는 denoising objective,
그 중에서도 denoising span이 가장 좋은 성능을 나타낸다. -
C4 Dataset
일부 downstream task에서 in-domain unlabeled dataset이 성능 향상에 큰 기여를 하지만, 도메인을 제한하게 되면 dataset의 크기가 훨씬 더 작아지게 된다. 연구를 통해서 더 크고 더 다양한 도메인을 아우르는 dataset이 성능 향상에 기여함을 알 수 있다.
reference
