[Paper Review] T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Paper Review
논문 읽는 순서 추천
(반드시 이 순서를 따라야 된다는 아니며 내 취향은 이 순서였다는 것 뿐이다.)
- Abstract
- Introduction
- 2.1 Model 첫 문단
- 2.4 Input and Output Format
- Experiments 첫 문단
- Putting It All Together (Test set은 추후 읽어도 될 듯)
- 필요에 따라 Experiments 각 파트
- Reflection
- 남은 부분들
이번에 포스팅할 논문은 2020년 Google에서 발표한 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, T5라 불리는 논문이다.
논문은 최근 NLP task에 거의 다 사용되는 transfer learning 기법의 각 부분들에 대한 전체적인 연구를 담고 있다. Unlabeled dataset, model architecture, pre-training objective, transfer approach등 이제껏 발표된 논문에서 제안된 다양한 기법들에 대해서 각각이 성능 개선에 어느정도의 영향을 끼치는지에 대해 실험한 내용과 함께 새로 제안하는 T5 모델에 대한 설명이 있다.
이 포스팅에서는 논문에서 진행한 실험을 전부 다 담아내기보다는 T5에서 사용된 기법들과 그에 대한 각각의 설명만을 적어보려 한다. (사실 양이 너무 많아서 쓸 엄두가 안난다...)
그래서 포스팅 순서는
- The Purpose of This Paper
- Features of T5
- Future Works
이렇게 크게 세 부분으로 나누어 적으려 한다.
Keywords
- Text-to-Text Framework
- Original Encoder-Decoder Transformer
- Denoising Corrupted Span
- C4 Dataset
- Multi-task pre-training
- Scaling Model Size
1. The Purpose of This Paper
The motivation for this paper was the flurry of recent work on transfer learning for NLP.
논문의 목적을 한 문장으로 표현하라면 이와 같다고 생각한다.
최근의 NLP 연구들은 대량의 unsupervised dataset에 대해 pre-train된 모델을 목표로 하는 downstream task에 대해 supervised fine-tuning하는 transfer learning 방식이 보편화된 상태이다. 이러한 방식이 task-specific model을 만드는 것보다 더 좋은 성능을 나타냄은 이미 입증되었다. 또한 이전의 연구들에 의해 더 큰 모델을 사용할수록, 더 많은 데이터셋을 사용할수록 더 좋은 성능을 나타낸다는 것도 입증되었다.
이에 따라 다양한 방식의 pre-training objective, unlabeled dataset, fine-tuning method들이 등장했고 모델의 크기 또한 그에 맞춰서 크게 증가했으나 각각의 서로 다른 기법들의 효과에 대한 연구는 제대로 되지 않은 상황이였다. 그래서 저자는 이 논문을 통해서 이전까지 인기있고 좋은 성능을 나타냈던 방법들(ex: BERT, GPT)에 사용된 각각의 기법들에 대한 비교 실험을 진행하고자 했다.
2. Features of T5
T5의 특징들은 앞서 말한 Keywords에 있는 것들이라고 보면 된다. 하나씩 자세하게 살펴보자.
Text-to-Text Framework
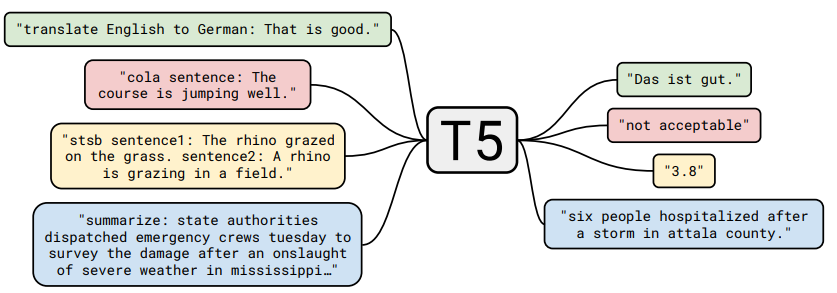
T5는 모든 NLP task들을 Text-to-Text 문제로 취급할 수 있다는 아이디어에서 출발했다. Text-to-Text는 보통 generation task에서 사용하는 방식인데, T5에서는 generation뿐만 아니라 classification, regression 문제도 Text-to-Text로 풀려고 했다. 이렇게 모든 task들을 하나의 접근 방법으로 풀게 된다면 다양한 downstream task에 동일한 model, objective, training procedure, decoding process를 적용할 수 있게 된다.
T5는 획일화된 방식을 통해 다양한 transfer learning objective와 unlabeled dataset 같은 다양한 모델링 요소들에 대해서 효과적으로 비교 분석할 수 있게 되었다.
Original Encoder-Decoder Transformer
T5의 model architecture는 기본 Transformer 구조를 크게 벗어나지 않는다. BERT나 GPT 같은 모델처럼 Transformer 구조의 Encoder나 Deocoder를 따로 떼어내서 사용하는 것이 아니라 그냥 원래 Transformer의 Encoder-Decoder 구조를 그대로 가져와서 사용한다.
다만 약간의 변경점은 있다.
- Transformer의 Layer Normalization에 사용되는 bias를 제거하고 rescale만 수행
- Absolute positional embedding 대신 Relative positional embedding 사용
- Model layer 전체에서 position embedding parameter sharing
Denoising Corrupted Span

T5의 pre-training objective는 SpanBERT논문에서 제안된 기법을 사용한다.
원래 BERT의 경우에는 입력되는 original text 내의 일부 token들을 [MASK] token으로 교체하는 방식을 택했으나, SpanBERT에서는 각 token을 마스킹하는 것이 아니라 Span을 하나의 [MASK] token으로 마스킹한다.
이 방식을 사용했을 때 어느정도의 성능 향상이 있었을 뿐만 아니라 계산 효율도 꽤 향상되었다.
Why Denoising Span?

위의 표는 각 pre-training 방법에 대한 성능 비교를 나타낸 표 인데, Prefix language modeling은 GPT와 같은 standard language modeling 방식을, BERT-style은 BERT에서 사용되는 masked language modeling 방식을 말한다. 마지막으로 Deshuffling 방식은 sequence를 입력으로 받아 순서를 shuffling한 후 원래 sequence를 target으로 해서 복구하는 방식의 denoising sequential autoencoder를 이야기한다.
세 종류의 pre-training objective에 대해서 실험한 결과 BERT-style의 masked language modeling 방식이 가장 좋은 성능을 나타냈다.

그렇게 BERT-style의 pre-training objective가 가장 좋은 성능을 나타냈다는 것을 확인한 후 여러가지의 denoising objectives에 대해서 서로 비교 실험을 진행했다.
위 표가 실험의 결과인데, 첫번째로 BERT-style은 original BERT에서 사용되었던 15%의 token을 masking하는 방식을 말한다. 두번째로 MASS-style은 MASS 논문에서 제안되었던 span내 token들을 masking하고 해당 token들을 예측하는 방식을 말한다. 그 아래의 Replace corrupted spans는 T5에서 사용한 일정 span을 하나의 masking token으로 대체하는 방식을, Drop corrupted tokens는 input sequence의 tokens를 제거하고 다시 복원하는 방식을 말한다.
실험 결과 전반적으로 가장 좋은 성능을 이끌어낸 방법은 세번째인 Replace corrupted spans였다.

추가로 masking 비율에 대한 성능 비교 실험도 진행했는데, 그 결과 전체 15%의 sequence를 masking하는 것이 가장 좋은 성능을 나타냈다고 말한다.
BERT 논문에서도 결국 15%의 token을 masking했던 것으로 보아 아마도 이 비율로 masking하는 방식이 가장 좋은 성능을 나타내는데에는 다른 이유가 있지 않을까 생각이 든다.
C4 Dataset
T5의 pre-training에 사용된 데이터셋은 C4라는 데이터셋이다. Colossal Clean Crawled Corpus라는 의미로 이전에 GPT-3의 학습에 사용되었던 Common Crawl에 몇가지 cleaning 기법들을 적용해서 만든 데이터셋이다. 각 기법들을 정리해보면 아래와 같다.
- 마침표, 느낌표, 물음표, 끝 따옴표로 끝나는 줄만 가져옴
- 문장 5개 미만은 제거, 3 단어 이상으로 이루어진 줄만 가져옴
- 비속어 담은 페이지는 제거
- JavaScript 단어 들어간 줄은 제거
- lorem ipsum (무의미한 문장) 있는 페이지 제거
- 중괄호 { 나타나는 페이지 제거
- 중복 문장 제거 위해서 3번이상 나오면 하나 빼고 다 제거
또한 langdetect라는 필터를 사용해서 영어로만 이루어진 corpus를 구성했다.
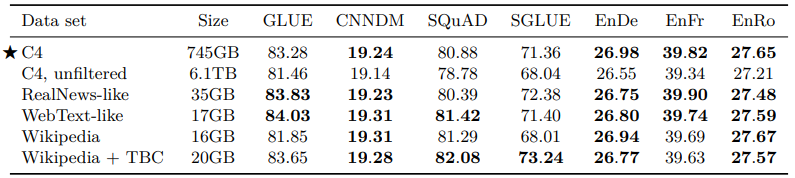
그렇게 제작된 unlabeled dataset은 기존에 사용되던 다른 여러 데이터셋과의 pre-train 성능 비교를 진행했다. 실험 결과를 보면 생각보다 C4 dataset의 성능이 뛰어나지 않음을 알 수 있다. 이는 RealNews-like나 Wikepedia, Wikepedia+TBC 같은 dataset이 C4에 비해 더 domain에 국한되어 있기 때문이라고 한다. 가장 심한 예시를 보면 SuperGLUE의 MultiRC task에서 C4는 EM 25, Wikipedia+TBC는 EM 50 가량의 점수를 내며 두 배 정도 성능 차이를 보였다.
T5 논문 저자가 특정 domain에 국한되지않는 모델의 pre-training이 목표였던 것으로 보아 이 부분에 있어서는 다른 방식으로 unlabeled corpus를 수집하거나 별도의 기법이 더 적용되어야 할 것으로 보인다.
Multi-task pre-training
Multi-task learning이란 하나의 unsupervised task에 대해서 pre-training을 진행한 후 fine-tuning하는 것 대신에 여러 종류의 task에 대해서 한 번에 training을 진행하는 것을 말한다.
논문에서는 이 multi-task learning 방식과 pre-train + fine-tune 방식의 성능 비교를 진행하고자 했다. Multi-task learning의 경우에는 각 task별 data 사용 비율에 따라 성능이 달라지게 되는데, 자칫 너무 많은 양의 data를 training에서 활용하게 된다면 training dataset을 memorize하게 된다. 그래서 논문에서는 여러가지 비율 설정 방식에 대해서 비교를 진행했다.
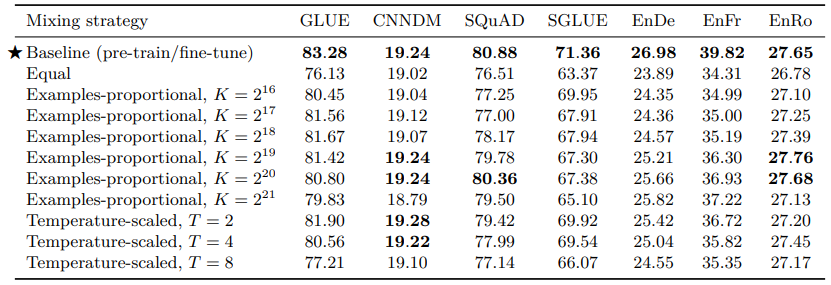
결과는 pre-train/fine-tune 방식이 가장 좋은 성능을 나타냈다. 그래서 저자는 pre-train/fine-tune 방식에 multi-task learning을 적용하고자 하였고, multi-task로 pre-training한 모델을 다시 하나의 task에 대해서 fine-tuning하는 방식을 고안해냈다.

그 결과 multi-task pre-training + fine-tuning이 기존의 unsupervised pre-training + fine-tuning 방식과 거의 비슷한 성능을 나타내는 것을 확인하고 최종 모델의 학습에 해당 방식을 사용했다.
Scaling Model Size
마지막은 모델의 크기에 대한 연구였다. 사실 BERT, GPT부터 시작해서 NLP 분야에서 transfer learning은 모델의 크기가 성능을 좌우한다고 봐도 무방할 정도이다. 그만큼 이미 큰 모델 == 좋은 성능은 사실로 판명이 난 상황이라 생각보다 놀라운 발견은 없었던 것 같다.
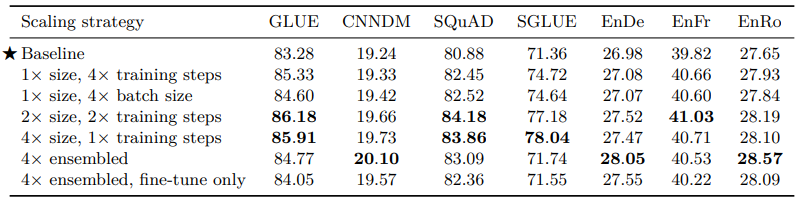
위의 표는 실험의 결과이다. 당연하게도 모델의 크기가 증가할수록, 학습을 더 길게 할수록 성능이 좋아짐을 알 수 있다. 그리고 ensemble을 할 경우에도 모델 크기를 키우는 것과 비슷하게 성능 향상을 이끌어낼 수 있었다.
2-1. Final T5 Model & Takeaways
여러 실험들을 거친 후 T5 모델이 선택한 기법들은 다음과 같다.
- Span-corruption objective
- Longer pre-training (1 million steps on batch size )
- Larger model (11B parameters)
- Multi-task pre-training + fine-tuning
- Beam Search
그리고 논문에서는 이 연구를 통해 얻게된 핵심 정보들을 다음과 같이 정리했다.
- Text-to-Text Framework
Text-to-Text Framework를 사용하게 되는 경우 하나의 모델로 loss, decoding방식 등의 변경없이 generation, classification, regression task 모두에서 좋은 성능을 이끌어낼 수 있다.
- Original Transformer Architecture
BERT나 GPT같은 모델처럼 Transformer의 encoder/decoder를 따로 떼어내서 사용하는 것이 아닌 original Transformer 구조를 그대로 사용하는 것이 text-to-text에서 더 좋은 성능을 나타낸다.
- Denoising Span Objective
Pre-training시 사용하는 objective중에서는 BERT 계열에서 사용하는 denoising objective, 그 중에서도 SpanBERT에서 사용한 denoising span이 가장 좋은 성능을 나타낸다.
- C4 Dataset
일부 downstream task에서 in-domain unlabeled dataset이 성능 향상에 큰 기여를 하지만, 도메인을 제한하게 되면 dataset의 크기가 훨씬 더 작아지게 된다. 연구를 통해서 더 크고 더 다양한 도메인을 아우르는 dataset이 성능 향상에 기여함을 알 수 있다.
3. Future Works
지금까지 NLP의 transfer learning에서 연구되었던 것들에 대한 정리를 마치고, 남은 연구 과제들을 말하는 것으로 논문은 마무리 된다.
간단하게 요약해보자면
- 더 이상 big model이 아닌 작은 크기로도 좋은 성능을 낼 수 있는 모델이 개발되어야 한다.
- 더 효율적이고 좋은 pre-training 방식이 필요하다. 특히 general knowledge에 대한 학습이 가능한.
- 각 task간의 유사성을 공식화해서 더 이상 unsupervised pre-training이 아닌 supervised pre-training으로 나아가야한다.
마지막으로는 특정 언어에 구애받지 않는 언어 모델을 만들 수 있어야 한다고 말하는데, 사실 이 부분에 대해서는 가능할지 모르겠다. 언어마다 다른 문법체계와 다른 단어들, 그리고 문화 차이로 인해 만들어지는 다양한 관용구들과 구절들을 모델이 학습하려면 음.... 아마 이제껏 쌓인 모든 기록들과 기록되지 않은 부분들에 대해서까지 학습할 수 있어야 가능하지않을까 한다.
아니면 뭐 그만큼 많은 corpus를 제작하는 것 밖에는 답이 없지 않을까...

2개의 댓글

t5는 SpanBERT의 token 단위가 아닌 span 단위의 consecutive masking 개념만 사용하였습니다.
SpanBERT는 single mask token으로의 infilling 기법을 사용하지 않습니다.
안녕하세요 치영님! 저는 NLP는 아니라서 사실 논문 내용은 잘 이해하지 못했지만, 처음부터 끝까지 꼼꼼하게 읽으셨다는걸 느낄 수 있었습니다. 공부를 많이하셨겠어요! :) 마지막에 각 핵심정리를 하이라이트로 표현한 부분이 좋았습니다. 서두에 이 논문의 주 목적과 contribution을 bold체로 작성해주시면 더 좋을 것 같습니다!