
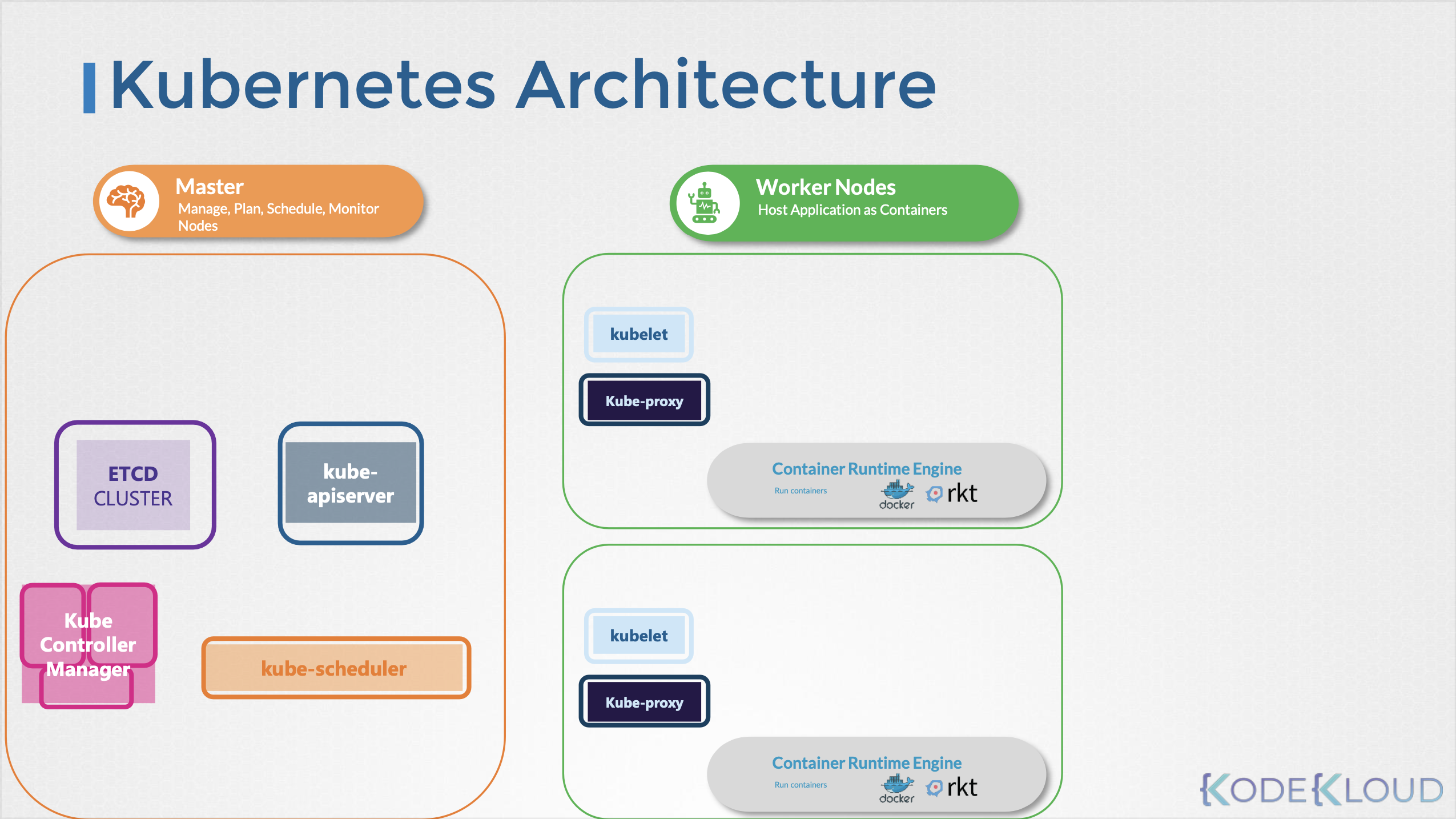
 클러스터는 일반적으로 하나 혹은 다수의 master 노드와 다수의 worker 노드로 구성된다.
클러스터는 일반적으로 하나 혹은 다수의 master 노드와 다수의 worker 노드로 구성된다.
각 노드의 구성은 다음과 같다.
마스터 노드 (master node)
마스터 노드는 etcd, apiServer, controllerManager, scheduler 네 가지의 컴포넌트로 구성되며, 각 컴포넌트는 마스터 노드 내 파드로 띄워지며 kube-system 네임스페이스에 위치하게 된다.(자체 호스팅)
1. etcd
etcd는 쿠버네티스(Kubernetes) 클러스터의 핵심 구성 요소로, 클러스터의 중요한 데이터를 저장하는 분산 키-값 저장소이다. etcd 가 저장하는 데이터 및 저장 방식은 다음과 같다.
클러스터 상태 정보
- etcd는 쿠버네티스 클러스터의 전체 상태를 저장한다. 이에는 파드(Pods), 서비스(Services), 디플로이먼트(Deployments), 노드(Nodes)와 같은 쿠버네티스 리소스의 상태 정보가 포함된다.
- 예를 들어, 어떤 파드가 어느 노드에서 실행되고 있는지, 어떤 서비스가 어떤 파드들에 연결되어 있는지 등의 정보가 저장된다.
구성 정보
- 쿠버네티스 클러스터의 구성 설정도 etcd에 저장된다. 이에는 네트워킹 설정, 리소스 할당 제한, 접근 권한 관리 등의 정보가 포함된다.
저장 방식
- etcd는 키-값 형태로 데이터를 저장한다. 각 쿠버네티스 리소스는 고유한 키를 가지며, 해당 키에 해당 리소스의 상태와 구성 정보가 값으로 저장된다.
- 예를 들어, 특정 파드에 대한 정보는 /kubernetes.io/pods/[네임스페이스]/[파드 이름]의 키를 가지며, 이 키에 해당 파드의 상세 정보가 JSON 형식의 값으로 저장된다.
분산 저장과 일관성
- etcd는 분산 시스템으로 설계되어 있어, 데이터의 안정성과 가용성을 보장한다. 클러스터 내 여러 마스터 노드에 걸쳐 데이터가 복제되어 저장된다.
- etcd에 저장된 데이터를 바탕으로 클러스터 상태를 일관되게 유지한다. 예로, 한 deploy의 replica를 3으로 설정했다는 데이터가 있을 때, 해당 deploy의 pod 중 하나가 죽어도 다시 만들어서 pod가 3으로 유지될 수 있도록 한다.
2. kube-apiserver
apiserver 는 노드와 노드 간의 통신, 사용자와 클러스터 간의 통신, 노드 내 각 컴포넌트 간의 통신 등 클러스터 내 일어나는 요청 및 응답에 대한 처리를 당담한다.
API 인터페이스 제공
- kube-apiserver는 쿠버네티스 API의 주요 인터페이스를 제공한다. 이 API를 통해 사용자, 클러스터 내부의 다른 구성 요소, 외부 시스템들이 클러스터와 상호 작용할 수 있다.
데이터 처리 및 검증
- API를 통해 받은 요청들은 kube-apiserver에 의해 처리되고 검증된다. 이는 클러스터의 상태를 변경하는 명령들을 포함한다.
다른 컴포넌트들과의 통신
- kube-apiserver는 클러스터의 상태 정보를 저장하고 검색하기 위해 etcd 저장소와 통신한다.
- 이외의 컴포넌트(scheduler, manager)과도 통신한다.
인증 및 권한 부여
- kube-apiserver는 요청이 유효한 인증 정보를 가지고 있는지 확인하고, 해당 사용자가 요청한 작업을 수행할 수 있는 권한을 가지고 있는지 검사한다.
3. Kube Controller Manager
클러스터 내에는 여러 컨트롤러들이 있다. 이 컨트롤러들은 클러스터의 상태를 지속적으로 감시하고, 필요한 조정을 통해 클러스터가 원하는 상태를 유지하도록 한다. kube-controller-manager는 이러한 컨트롤러들을 효율적으로 관리하고 조정하는 역할을 수행한다.
주요 controller 들은 다음과 같다.
노드 컨트롤러(Node Controller)
- 노드의 상태를 모니터링하고, 노드에 문제가 발생했을 때 적절한 대응을 한다. 예를 들어, 노드가 다운되었을 때, 해당 노드에 있던 파드들을 다른 노드로 이동시키는 작업을 수행한다.
레플리케이션 컨트롤러(Replication Controller)
- 파드의 replicas의 수를 관리한다. 이 컨트롤러는 지정된 수의 파드 replica 만큼 실행되고 있는지 확인한다.
엔드포인트 컨트롤러(Endpoints Controller)
- 서비스와 파드를 연결한다. 서비스에 정의된 파드들이 변경될 때마다 엔드포인트를 갱신하여, 서비스가 올바른 파드들을 가리키도록 한다.
서비스 어카운트 및 토큰 컨트롤러(Service Account & Token Controllers)
- 새 네임스페이스에 대한 기본 서비스 어카운트와 API 액세스 토큰을 생성한다.
4. kube-scheduler
스케줄러는 pod가 배포될 node를 결정하는 역할을 한다.
pod 생성 요청이 들어오면, 스케줄러는 각 ndoe의 여유 자원을 파악하여 해당 pod가 어느 노드로 배치될지 결정한다. 그러나 실제 pod 배포를 담당하는 것은 아니며, 배포될 node 가 결정되면 kubelet을 통해 해당 worker node 에 pod 생성 명령이 떨어지게 된다.
워커 노드 (worker node)
1. kubelet
worker node 의 모든 부분을 관리하며, master 로부터 내려온 명령을 수행하거나 node 내 발생하는 이벤트를 master에 보고한다.
파드 관리
- kubelet은 API 서버로부터 파드에 대한 명령(생성, 수정, 삭제 등)을 받고, 이에 따라 컨테이너를 실행하거나 중지한다.
상태 보고
- 실행 중인 파드의 상태를 주기적으로 쿠버네티스 API 서버에 보고한다. 이는 클러스터의 상태를 모니터링하는 데 중요하다.
자원 관리
- 각 노드에 할당된 리소스(예: CPU, 메모리)를 관리하며, 파드가 요구하는 리소스를 기반으로 컨테이너를 실행한다.
헬스 체크
- ubelet은 파드의 헬스 체크(건강 검사)를 수행하여, 문제가 있는 파드를 자동으로 재시작할 수 있다.
- 이 역시 master에 보고되어 etcd 의 해당 pod의 정보가 재시작 상태로 변경되며, manager는 해당 정보를 토대로 다른 적절한 조치를 취할 수 있다.
2. kube-proxy
kube-proxy는 쿠버네티스(Kubernetes) 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 클러스터 내 서비스(Service)에 대한 네트워크 트래픽을 관리하는 역할을 한다. kube-proxy의 주요 기능과 역할은 다음과 같다.
트래픽 라우팅
- kube-proxy는 클러스터 내부 또는 외부에서 오는 요청을 적절한 서비스의 백엔드 파드(Pods)로 라우팅한다. 예를 들어, 특정 서비스에 대한 요청이 들어오면, kube-proxy는 이 요청을 서비스를 구성하는 파드 중 하나로 전달한다.
로드 밸런싱
- 여러 파드로 구성된 서비스에 대해, kube-proxy는 들어오는 요청을 service에 정의된 규칙에 따라 파드들 사이에 균등하게 분배한다. 이를 통해 로드 밸런싱을 제공하여 서비스의 가용성과 신뢰성을 높인다.
NAT(Network Address Translation)
- kube-proxy는 NAT를 사용하여 클라이언트의 목적지 IP 주소(외부의 노출되는 service의 ip)를 서비스의 pod IP로 변환한다. 이를 통해 클라이언트는 서비스에 연결할 때 파드의 실제 IP를 몰라도 접근할 수 있다.
세션 어피니티
- 필요한 경우, kube-proxy는 특정 클라이언트의 연속적인 요청을 동일한 파드로 라우팅하여 세션 어피니티(session affinity)를 유지할 수 있다.
service와 kube-proxy의 차이
서비스(Service)
- 서비스는 파드 그룹에 대한 논리적인 접근 포인트를 제공한다. 서비스는 일련의 파드를 하나의 네트워크 서비스로 그룹화하고, 이 그룹에 대한 고정된 IP 주소와 포트를 할당한다.
- 서비스는 파드의 실제 IP 주소를 숨기고, 클라이언트가 서비스의 IP와 포트를 사용하여 파드 그룹에 접근할 수 있게 한다.
- 서비스는 또한 로드 밸런싱의 설정을 정의하지만, 실제 로드 밸런싱을 수행하는 것은 아니다.
kube-proxy
- kube-proxy는 각 노드에서 실행되며, 서비스의 로드 밸런싱 설정을 실제로 구현한다.
- 클라이언트가 서비스에 접근할 때, kube-proxy는 서비스의 로드 밸런싱 규칙에 따라 들어오는 요청을 적절한 파드로 전달한다. 이는 NAT(Network Address Translation) 또는 IP 테이블 규칙을 조작하여 이뤄진다.
- kube-proxy는 서비스가 정의한 로드 밸런싱(예: 라운드 로빈)을 실제 네트워크 수준에서 실행하여, 들어오는 요청을 여러 파드에 분산한다.
