Google Colab
캐글에서 타이타닉
파일을 불러오고 개념 익히기
1.캐글에서 파일 다운로드 후 cvs 파일 읽어오기
(1)파일을 DataFrame(titanic_df)으로 로딩. read_csv()
titanic_df = pd.read_csv("/content/train.csv")
titanic_df.head(3) #처음 5건 출력 #3 입력 - 3건 출력
titanic_df.tail() #마지막 프린트 구문
titanic_df.sample(5) #default 로 1건만 출력 #마지막 라인만 출력(2)titanic_df의 type을 확인. type()
print(type(titanic_df)) #DataFrame은 엑셀 파일 같이 생김
DataFrame 속성(함수가 아닌 변수로 구성) : index,column, values3)행과 열의 크기를 확인. shape
titanic_df.shape #(행수,열수)로 구성 인덱스 891 칼럼이 12개
(4)칼럼명 정보를 확인. columns
titanic_df.columns
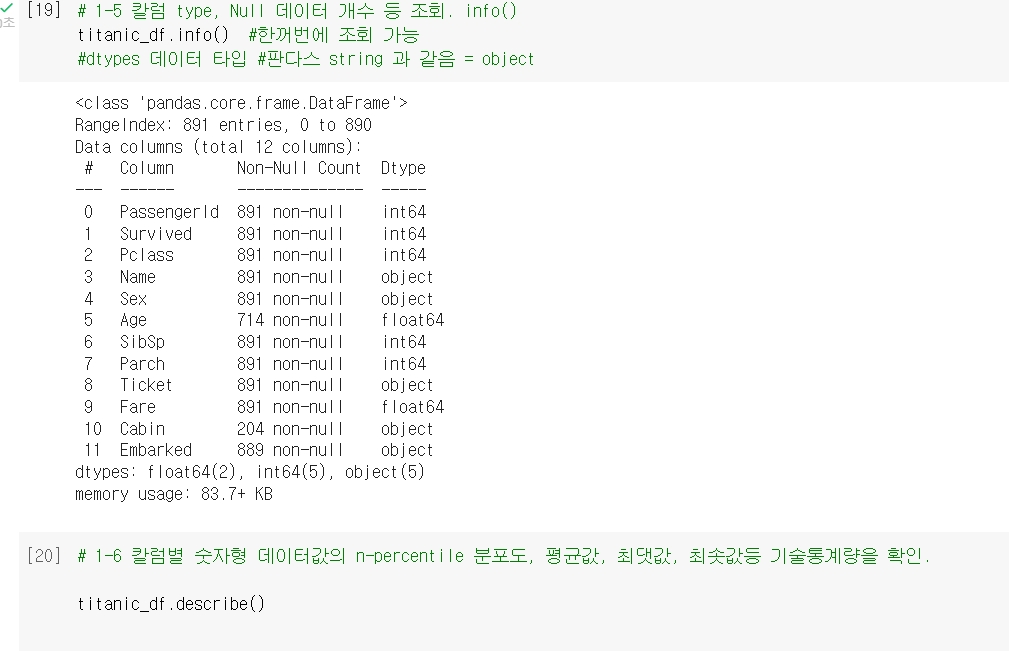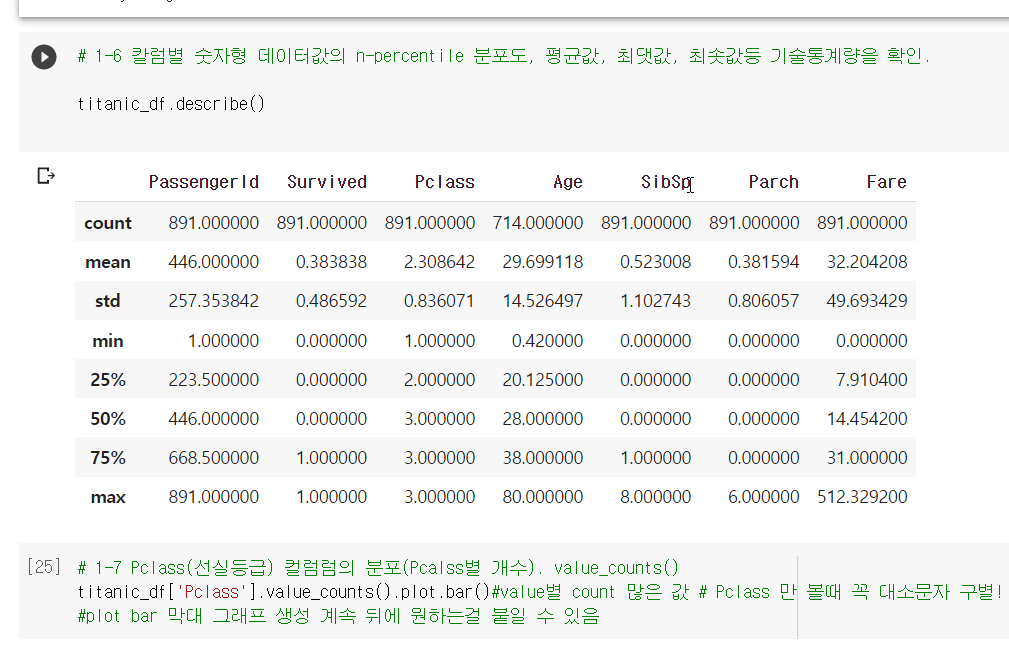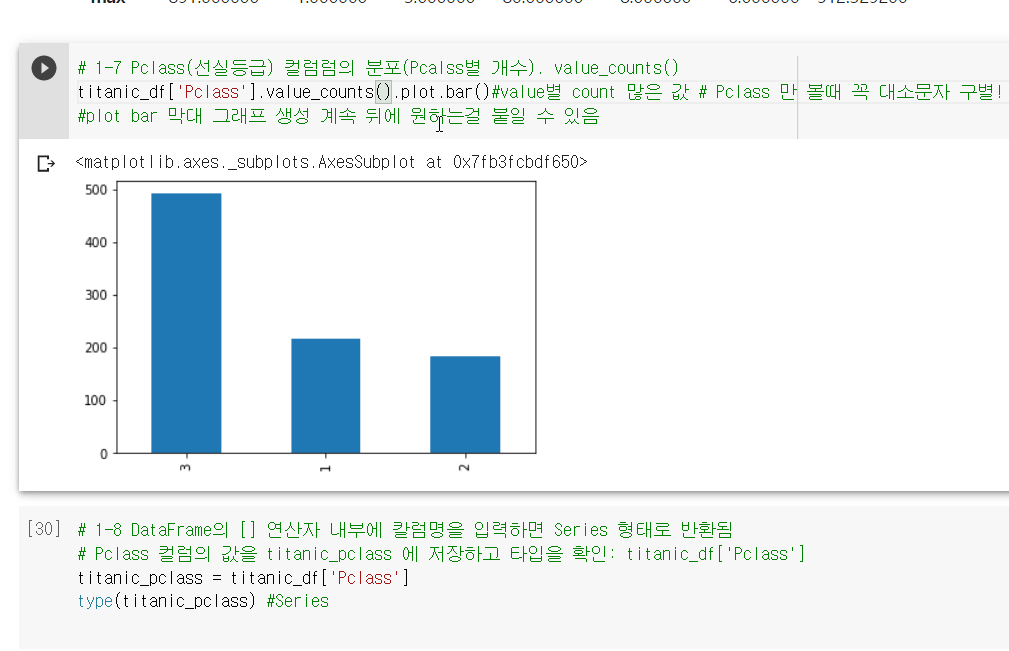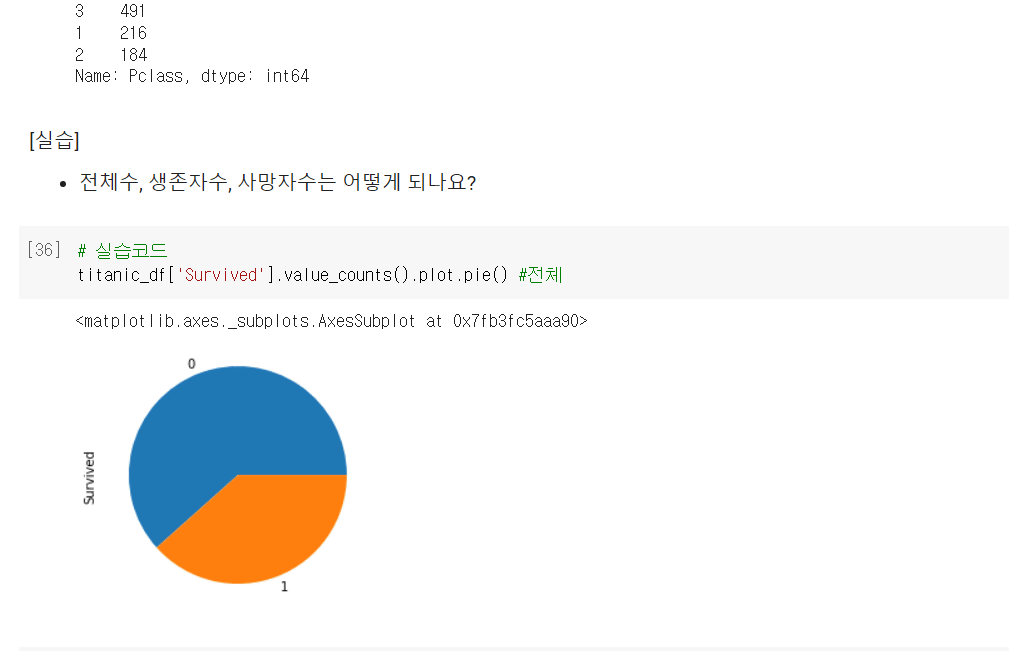
(5)칼럼 type, Null 데이터 개수 등 조회. info()
titanic_df.info() #한꺼번에 조회 가능
#dtypes 데이터 타입 #판다스 string 과 같음 = object(6)칼럼별 숫자형 데이터값의 n-percentile 분포도, 평균값, 최댓값, 최솟값등 기술통계량을 확인.
titanic_df.describe()
(7)Pclass(선실등급) 컬럼럼의 분포(Pcalss별 개수). value_counts()
titanic_df['Pclass'].value_counts().plot.bar()#value별 count 많은 값 # Pclass 만 볼때 꼭 대소문자 구별! #plot bar 막대 그래프 생성 계속 뒤에 원하는걸 붙일 수 있음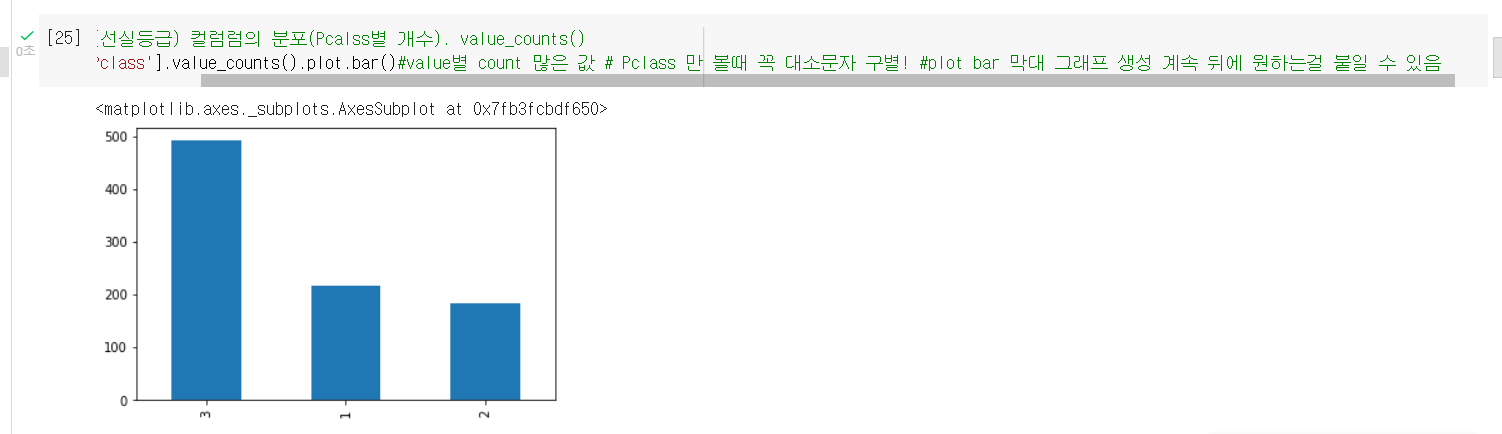

안녕하세요! 오늘도 모두 좋은 하루 보내세요!