Data Flows in React

개요
이 글은 React의 Data Flow를 3000미터 위에서 바라보는 글 입니다.
글의 시작으로 React와 같은 SPA가 페이지를 렌더링하는 방식을 보겠습니다.
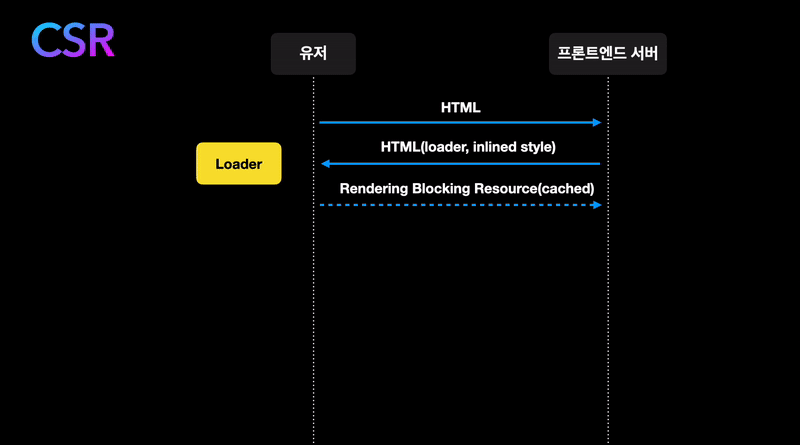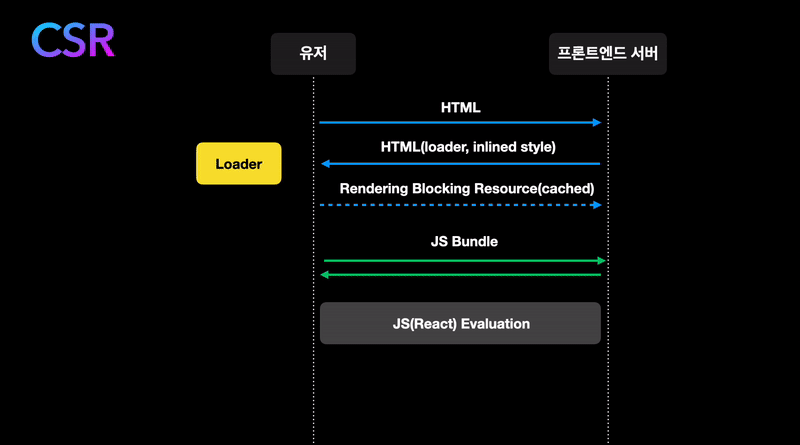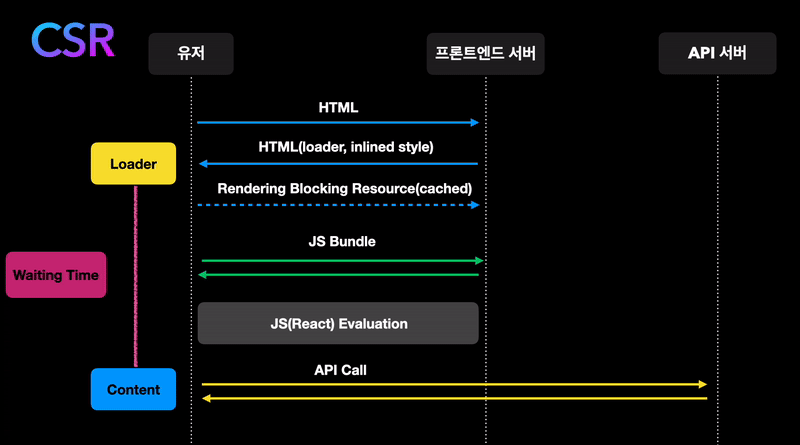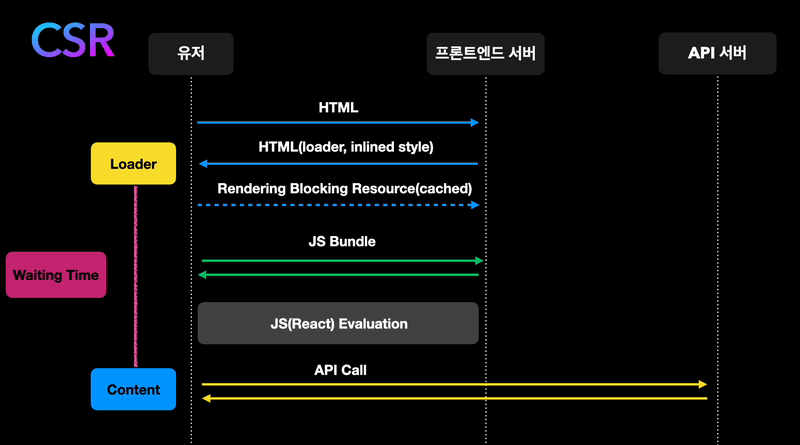
- 유저가 서버에 페이지를 요청합니다.
- 서버는 React bundle이 들어있는 HTML 파일을 보내줍니다.
- 브라우저가 React bundle을 fetching해와서 React code로 페이지를 그립니다.
- 데이터가 필요한 컴포넌트는 데이터를 요청합니다. 데이터는 유저에게 반환되고 React가 그 데이터로 DOM을 업데이트합니다.
이 글에서 이야기할 내용은 4번과 관련이 깊습니다.
Data Flow in React
React에서 데이터가 필요한 컴포넌트는 데이터를 요청합니다. 그리고 데이터를 가져오는 방법은 다양합니다.(useEffect, redux..등)
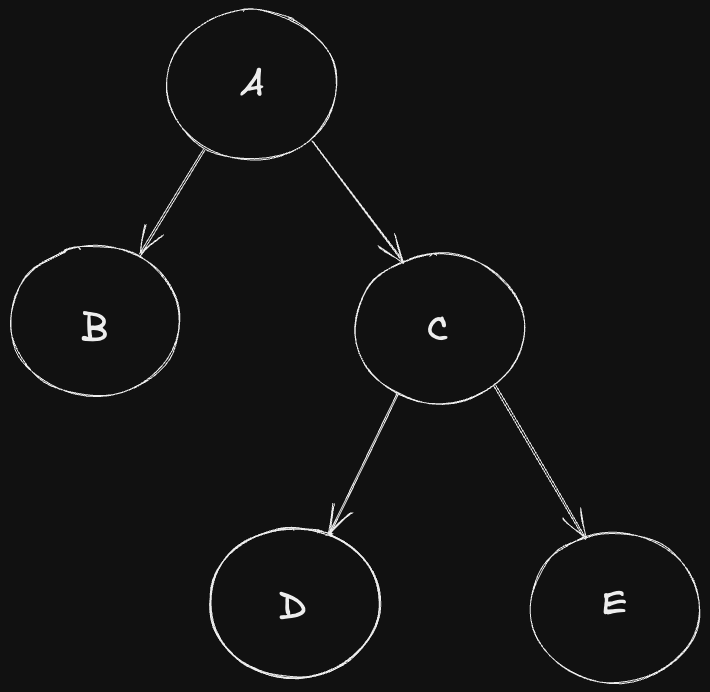
우리가 위와 같은 컴포넌트 계층 구조를 갖는 애플리케이션을 개발했다고 상상해보겠습니다.
React는 단방향 데이터 흐름을 갖으므로 데이터는 부모에서 자식으로 흐릅니다.
C, D, E에 각각 데이터를 fetching하는 로직이 담겨져 있다고 해보겠습니다.
코드로 표현한다면 다음과 같이 표현할 수 있습니다.(B는 제외)
function PageA({ userId }) {
return (
<C userId={userId}>
<D userId={userId} />
<E userId={userId} />
</C>
)
}C의 데이터 fetching이 끝나기 전까지.
다시말하면 C컴포넌트에서 D와 E를 렌더링하기 전까지 D와 E는 fetching을 시작조차 하지 않습니다.

위 그림에서 더 위에있는 React 로고를 상위 컴포넌트라고 하면 상위 컴포넌트가 fetching이 시작되고 끝날 때까지 기다리고 다음 하위 컴포넌트에서 data fetching이 시작됩니다. 동시에 요청을 보낼 수 있지만, 우리가 코드를 짠 방식 때문에 동시에 요청을 보내는 것 자체가 불가능하죠.
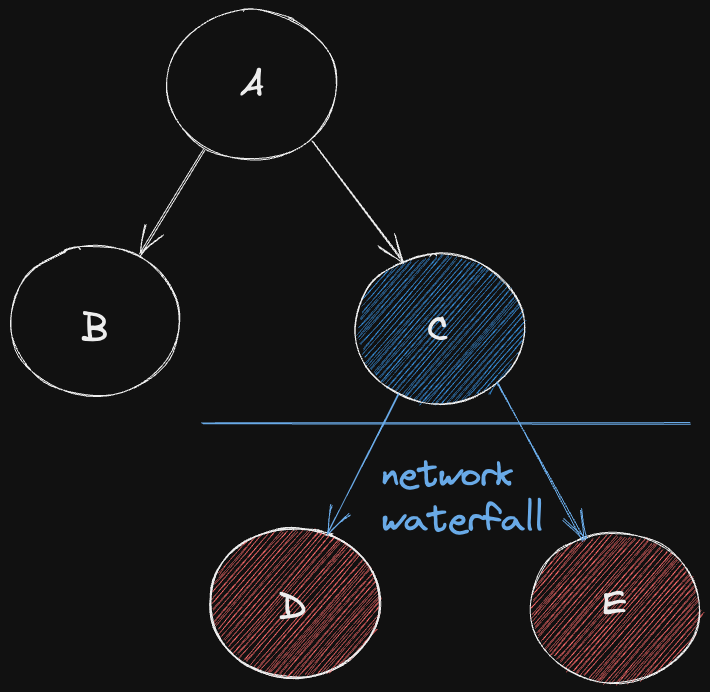
이러한 현상을 Network Waterfall이라고 합니다.
페이스북에서는 이 문제를 GraphQL과 Relay를 사용해 해결했습니다. (각각의 컴포넌트는 자신이 필요한 데이터를 GraphQL Frament를 통해 구체화하고, Relay는 fragments를 조합하여 새로운 페이지로 이동할 때 서버와 한번의 통신으로 데이터를 fetching 합니다.)
GraphQL을 사용하려면 백엔드를 GraphQL로 만들어야하는 제약이 존재합니다. 다른 해결 방법은 없을까요?
정말 쉬운 방법이 존재합니다.(props drilling)
Props Drilling
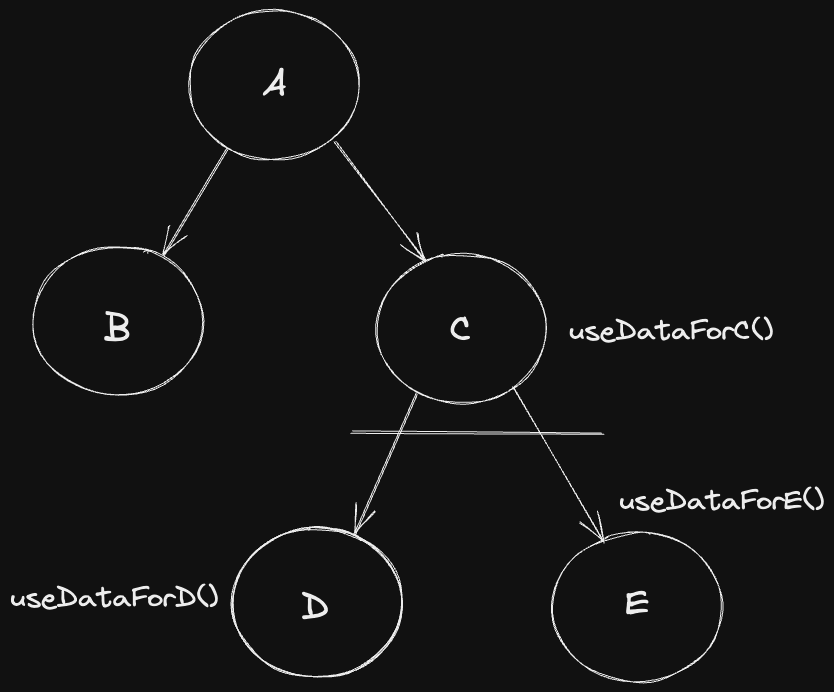
useDataFor*() 훅은 각각의 컴포넌트가 필요로 하는 데이터를 fetching하는 훅입니다.
useDataForD()와 useDataForE()가 useDataForC()로부터 오는 속성을 요구하지 않는다면 useDataForD()와 useDataForE()를 C 컴포넌트에 끌어올립니다.
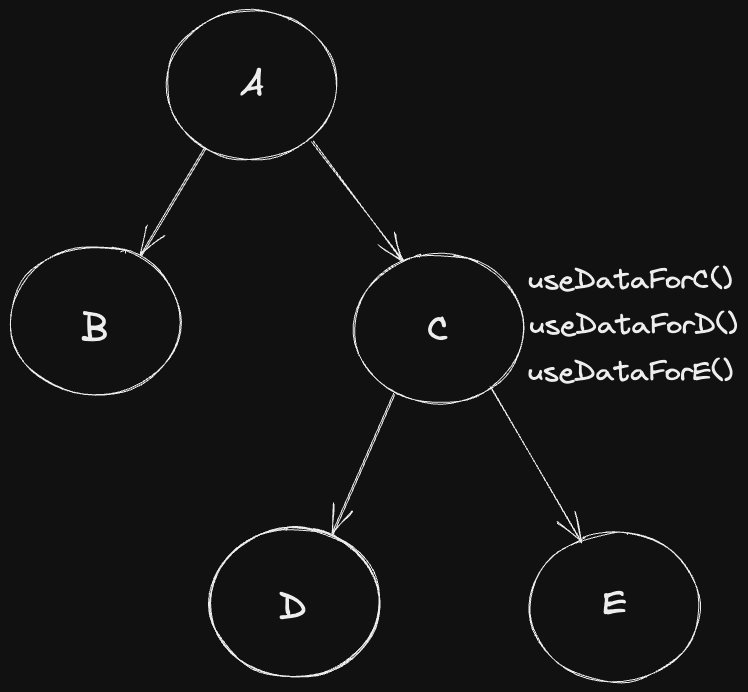
그 후 props drilling으로 아래 컴포넌트에 내려주면 됩니다.(한번에 상위 컴포넌트에서 모든 요청을 하고 props로 내려줍니다.)
하지만 위 경우는 이상적인 경우입니다. D와 E는 C로부터 오는 데이터를 필요로 할 수 있습니다. 아래와 같이 말이죠.
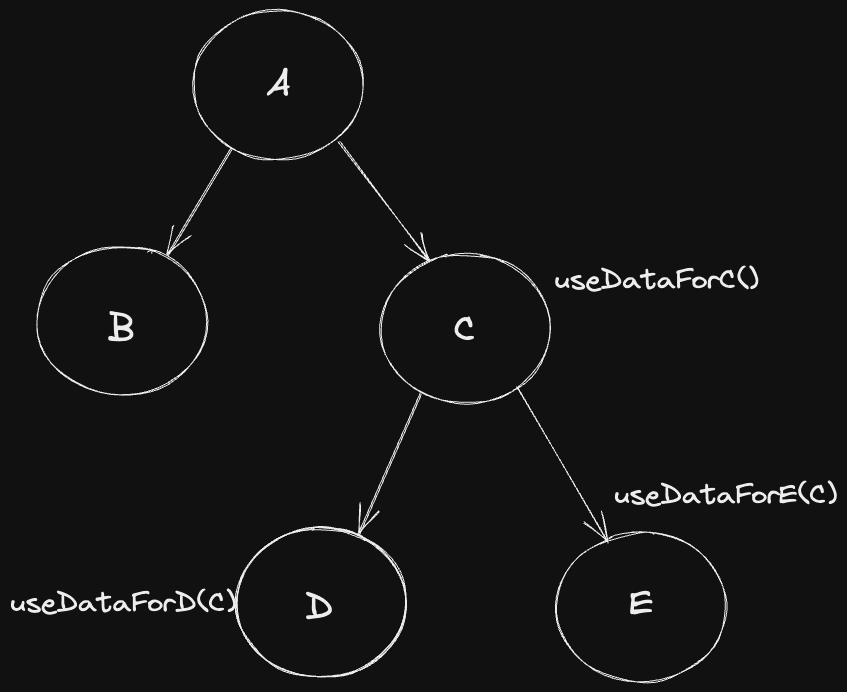
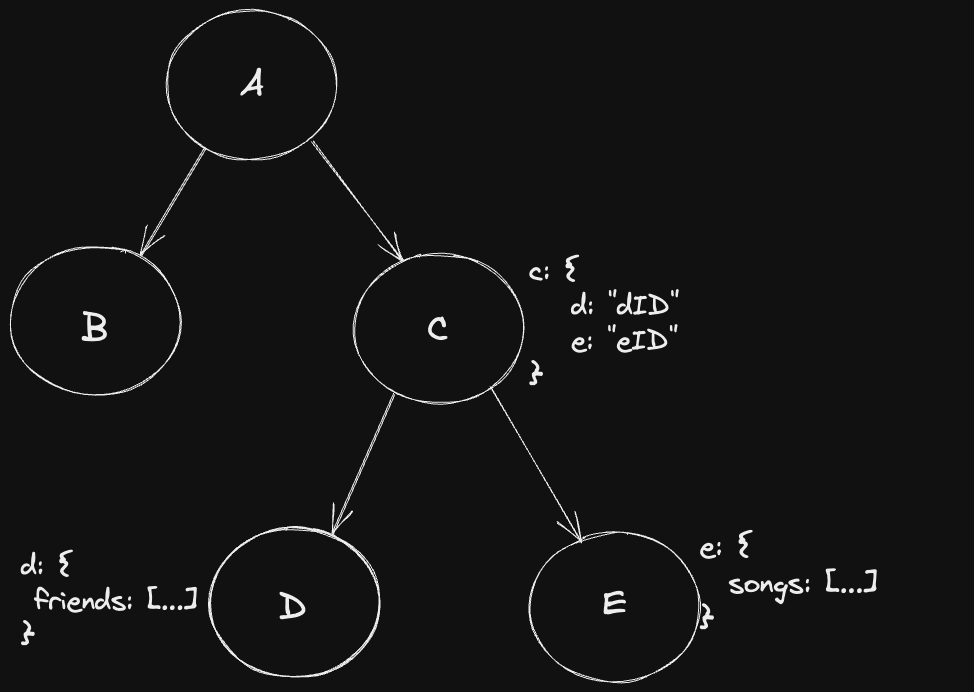
이러한 경우 useDataForC() 훅이 받는 데이터는 다음과 같습니다.
c: {
d: "dID"
e: "eID"
}그리고 D와 E는 그 아이디를 이용한 요청을 보내고 다음과 같은 임의의 데이터를 받을 것 입니다.
// D가 받는 데이터
d: {
friends: [...]
}
// E가 받는 데이터
e: {
songs: [...]
}
이 상황을 다시 이상적인 data fetching으로 바꿔보면 다음과 같습니다.
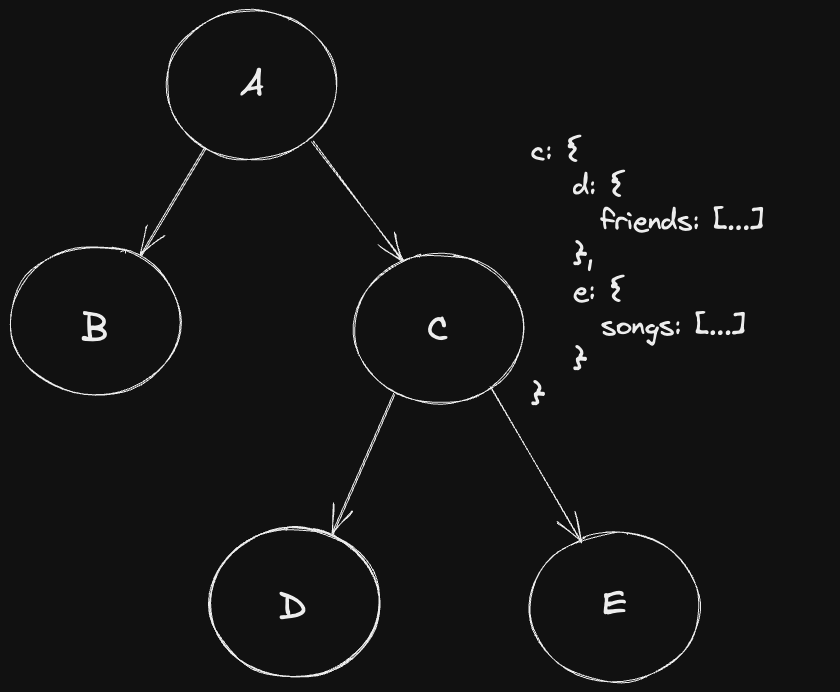
첫번째 fetch에서 모든 데이터를 가져오기 위해 Join을 활용한 것을 볼 수 있습니다.
팀원들(백엔드 엔지니어)과 대화를 통해 이 데이터를 가져오는 로직을 상단 컴포넌트로 올리고 하위 컴포넌트가 늦게 렌더링되는 것을 막아야합니다.
이렇게 하면 useDataForC() 훅을 호출하는 것을 통해 모든 데이터를 가져오게 되고 props drilling으로 내려줌으로써 Network Waterfall을 방지할 수 있습니다.
Example
지금까지 설명한 내용을 블로그 글을 렌더링하는 상황을 가정해서 예로 들어보겠습니다.
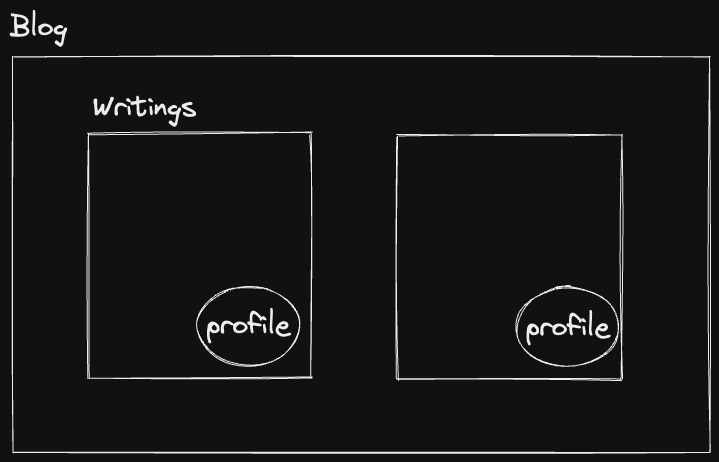
블로그 애플리케이션 내부에는 글들(writings)이 있고 글 컴포넌트 내부에는 작성자의 profile 컴포넌트가 있습니다.
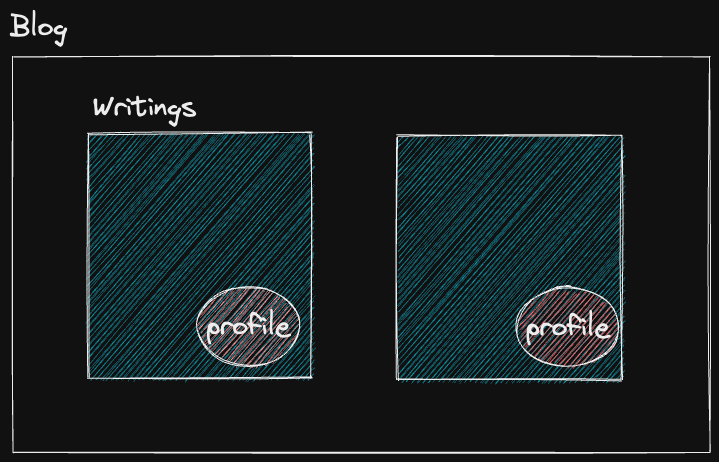
글 컴포넌트가 렌더링이 되었지만 profile 컴포넌트는 글이 렌더링이 된 이후에야 데이터 fetching을 할 수 있습니다.
이렇게 Network Waterfall을 만드는 것이 아닌, 데이터를 가져오는 로직을 최상단으로 끌어올려서 Props Drilling 해야합니다.
React는 View를 잘 다루기 위한 라이브러리입니다. 데이터를 가져오는 로직을 상단 컴포넌트로 끌어올림으로써 View와 비즈니스 로직을 분리하고 단방향 데이터의 흐름을 구축할 수 있습니다.(FLUX)
이게 React가 의도한 Data Flow입니다.
Drastic Props Drilling
과감한 Props Drilling
Props Drilling이 나쁘기만 한 것일까요?
저는 React의 특징인 단방향 데이터 흐름을 잘 활용하는 방법이라고 생각합니다.
Props Drilling을 하면 데이터의 흐름이 한방향으로만 이루어지기 때문에 추적하기 쉽습니다.
Props Drilling이 안좋다고 말하는 것은 상위 props들이 하위로 전달되는 유통과정에서 중간에 있는 컴포넌트가 그 props를 사용하지 않으면서 오직 전달을 위한 매개체로 사용될 때라고 생각합니다.
Props Drilling을 사용하면 컴포넌트를 테스팅하기도 쉬워집니다. 의존하는 것이 props뿐이기 때문입니다.(전역상태, Context, react-query등에 의존하지 않습니다.)
전역 상태에 의존하지 않는 컴포넌트는 컴포넌트를 컴포넌트답게 개발할 수 있으며(컴포넌트 주도 개발), 재사용 가능한 컴포넌트를 만들게 도와줍니다.
모든 React 애플리케이션은 적절한 deps의 Props Drilling과 각 컴포넌트의 상태가 조화를 이루어야하며, 적절한 Data Flow을 갖을 수 있도록 노력해야합니다.
React-Query
마지막으로 데이터 fetching을 매우 쉽게해주는 react-query에 대한 내용을 넣었습니다.
react-query를 통해 상위 컴포넌트에서 데이터를 가져오고 Props Drilling으로 내려줄 수 있습니다.
React는 View를 위한 라이브러리이고 ReactDOM은 UI를 실제로 브라우저에 렌더링할 때 사용하는 라이브러리이므로 데이터를 fetching하는 것에는 관심이 없습니다.
단지 fetching한 데이터를 UI에 반영시키는 것에만 관심이 많습니다.
React에서 데이터를 가져오는 방법에는 useEffect에서 fetch 요청을 하는 방법이나 redux와 같은 상태관리 라이브러리를 사용하는 방법이 있습니다.
위와 같이 데이터를 가져오는 방법은 isLoading, isError, isSuccess와 같은 상태를 직접 정의해야하고 많은 보일러 플레이트 코드를 수반하는 단점이 존재합니다.
react-query는 이를 해결합니다.
대다수의 애플리케이션에서 모든 비동기 코드를 react-query로 마이그레이션한 후 남겨지는 전역 상태는 매우 적을 것 입니다. 예제를 통해서 확인해보겠습니다.
전역 상태 관리 라이브러리에 의해 관리되는 다음과 같은 상태들이 있습니다.
const globalState = {
projects, // server state
teams, // server state
tasks, // server state
users, // server state
themeMode, // client state
sidebarStatus, // client state
}여기서 서버상태를 react-query로 옮긴다면 전역 상태는 많이 거의 남지 않게됩니다.
const globalState = {
themeMode,
sidebarStatus,
}이를 통해 알 수 있는 react-query의 역할은 분명합니다.
서버 상태를 관리하기위해 필요했던 보일러플레이트 코드를 제거한다. 그리고 단 몇줄의 코드로 대체한다.
